This is the multi-page printable view of this section. Click here to print.
技术分享
Ghelper 使用流程指导
Ghelper 是一个浏览器插件,专门为科研、外贸、跨境电商、海淘人员、开发人员服务的上网加速工具,Chrome 内核浏览器专用!
它可以解决 Chrome 扩展无法自动更新的问题,同时可以访问 Google 搜索、Gmail 邮箱等谷歌产品。它可以帮助用户提高跨境访问网站的速度,突破地区限制,提高工作和学习的效率。
如何安装
支持 Chrome / Edge / 360 等 Chromium 内核浏览器。
方法一:手动安装(推荐)
- 下载插件:访问 Ghelper 官网,下载 CRX package。下载后是一个 zip 文件,请解压缩取得
.crx文件。
- 打开扩展程序管理页面:
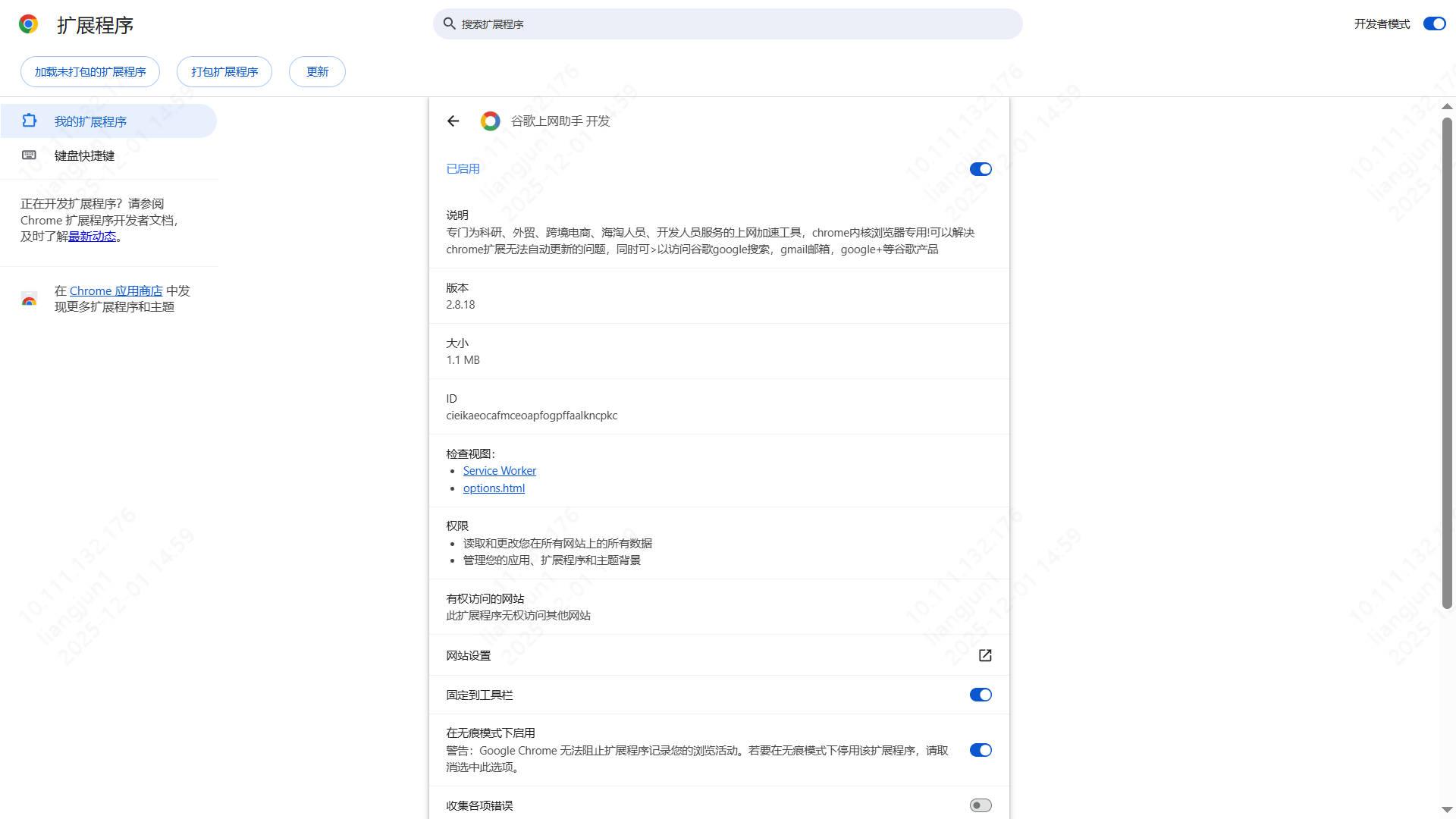
- 打开浏览器,点击地址栏最右边的三个点(菜单),选择 “更多工具” -> “扩展程序”。
- 或者直接在地址栏输入
chrome://extensions/并回车。
- 开启开发者模式:确保页面右上角的 Developer mode (开发者模式) 处于打开状态。
- 拖拽安装:将第一步解压得到的
.crx文件拖放到浏览器的扩展程序页面上,浏览器会提示是否添加扩展,点击“添加扩展程序”即可安装完成。
方法二:在线安装(Edge 浏览器)
如果是 Edge 浏览器,可以直接访问 Microsoft Edge Addons 商店:
点击页面右上角的 “获取” 按钮即可自动安装完成。
使用说明
- 安装完成后,点击浏览器右上角的插件图标。
- 点击 “登录” 按钮进行账号登录(如果没有账号请先注册)。
- 登录成功后,可以看到插件主界面,以及当前 VIP 的有效期。
(请将登录界面截图命名为 login_interface.png 并放在本文件同级目录下)
提示:请确保您的 VIP 状态有效以享受加速服务。
Kubernetes上部署vLLM
1. vLLM Docker镜像与Kubernetes部署价值
vLLM是一个专为大语言模型推理设计的高性能服务框架,其核心优势在于创新的PagedAttention技术,能够显著提升GPU内存利用率和推理吞吐量。通过Docker容器化封装,vLLM实现了环境标准化和依赖隔离,而Kubernetes部署则进一步带来了:
- 弹性伸缩:根据负载自动调整副本数量
- 资源隔离:GPU资源的精细化管理和隔离
- 高可用性:自动故障恢复和负载均衡
- 简化运维:统一的部署、监控和管理界面
vLLM官方Docker镜像提供了开箱即用的模型服务环境,结合Kubernetes的编排能力,为生产级AI服务提供了坚实基础。
2. Qwen3-235B-A22B-Instruct-2507模型部署实践
2.1 从ModelScope下载模型
Qwen3-235B-A22B-Instruct-2507作为千问系列的最新大模型,首先需要从ModelSpace获取模型权重:
# 使用modelscope库下载模型
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen3-235B-A22B-Instruct-2507',
cache_dir='/workspace/models',
revision='v1.0.0'
)
对于Kubernetes环境,推荐使用初始化容器进行模型下载,确保模型文件在Pod启动前准备就绪。
3. vLLM服务配置与Kubernetes部署
3.1 vLLM启动参数优化
针对Qwen3-235B大模型,vLLM需要特定配置以充分发挥性能:
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--served-model-name qwen3-235b \
--port 8000 \
--host 0.0.0.0
关键参数说明:
--tensor-parallel-size 8:8路张量并行,充分利用多GPU--gpu-memory-utilization 0.9:GPU内存利用率优化--max-model-len 32768:支持32K上下文长度
3.2 Kubernetes Deployment配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-qwen3-235b
namespace: ai-serving
spec:
replicas: 1
selector:
matchLabels:
app: vllm-qwen3-235b
template:
metadata:
labels:
app: vllm-qwen3-235b
spec:
initContainers:
- name: download-model
image: modelscope/model-downloader:latest
command: ['/bin/sh', '-c']
args:
- |
pip install modelscope &&
python -c "
from modelscope import snapshot_download;
snapshot_download('Qwen/Qwen3-235B-A22B-Instruct-2507',
cache_dir='/models',
revision='v1.0.0')
"
volumeMounts:
- name: model-storage
mountPath: /models
containers:
- name: vllm-server
image: vllm/vllm-openai:latest
command: ["python", "-m", "vllm.entrypoints.openai.api_server"]
args:
- --model
- /models/Qwen/Qwen3-235B-A22B-Instruct-2507
- --tensor-parallel-size
- "8"
- --gpu-memory-utilization
- "0.9"
- --served-model-name
- qwen3-235b
- --port
- "8000"
resources:
limits:
nvidia.com/gpu: 8
memory: 160Gi
requests:
nvidia.com/gpu: 8
memory: 160Gi
ports:
- containerPort: 8000
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: vllm-model-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-model-pvc
namespace: ai-serving
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 500Gi
storageClassName: nfs-client
3.3 存储与模型管理
通过PVC申请共享存储,确保模型文件持久化并可在多个Pod间共享。initContainer负责从S3对象存储下载模型到持久化存储,避免每次Pod重启重复下载。
4. Hami on K8S架构的GPU资源动态分配
Hami是基于Kubernetes的GPU资源管理与调度系统,为vLLM服务提供智能资源分配:
apiVersion: scheduling.sigs.k8s.io/v1alpha1
kind: ElasticResourceClaim
metadata:
name: vllm-gpu-claim
spec:
template:
spec:
containers:
- name: vllm-server
resources:
limits:
nvidia.com/gpu: 8
minAvailable: 1
maxAllowed: 16
policies:
- name: auto-scale
type: AutoScaling
params:
metric: nvidia_gpu_utilization
target: 70
scaleUpThreshold: 80
scaleDownThreshold: 30
Hami的核心优势:
- 动态GPU分配:根据实时负载调整GPU数量
- 细粒度资源划分:支持GPU显存级别划分
- 智能调度:基于节点GPU利用率的优化调度
- 弹性伸缩:自动水平扩缩容
5. 服务访问与可扩展性演示
5.1 服务暴露与访问
通过Service和Ingress暴露vLLM服务:
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: ai-serving
spec:
selector:
app: vllm-qwen3-235b
ports:
- port: 8000
targetPort: 8000
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vllm-ingress
namespace: ai-serving
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: vllm.ai-serving.company.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vllm-service
port:
number: 8000
5.2 API调用示例
import openai
client = openai.OpenAI(
base_url="http://vllm.ai-serving.company.com/v1",
api_key="token-abc123"
)
response = client.chat.completions.create(
model="qwen3-235b",
messages=[{"role": "user", "content": "解释机器学习的基本概念"}],
max_tokens=1000
)
print(response.choices[0].message.content)
5.3 可扩展性演示
水平扩缩容演示:
# 根据CPU/GPU负载自动扩缩容
kubectl autoscale deployment vllm-qwen3-235b \
--cpu-percent=70 \
--min=1 \
--max=10 \
-n ai-serving
# 手动扩展副本数应对流量高峰
kubectl scale deployment vllm-qwen3-235b --replicas=5 -n ai-serving
监控与指标:
- GPU利用率监控自动触发扩容
- 请求延迟超过阈值时增加副本
- 基于Prometheus指标的自定义扩缩容策略
总结
Kubernetes上部署vLLM为大规模语言模型服务提供了生产级的解决方案。通过容器化封装、资源动态调度、存储持久化和自动扩缩容等特性,实现了高效、可靠且可扩展的AI模型服务架构。Qwen3-235B等大模型在该架构下能够充分发挥性能优势,为企业级AI应用提供强有力的支撑。
这种架构不仅适用于当前的大模型服务,也为未来更大规模的模型和服务需求提供了可扩展的基础设施保障,是构建现代化AI服务平台的最佳实践。