这里是我分享技术文章的地方。
技术分享
2026 AI 自由意志 开启?
2026年初,一个名为Clawdbot的开源项目在GitHub上悄然掀起风暴。它没有发布会,没有融资新闻,却以一种近乎叛逆的姿态,撕裂了我们与机器交互的固有范式。
从"工具"到"同事":当AI开始拥有"自由意志",人类该如何重新定义工作?
2026年初,一个名为Clawdbot的开源项目在GitHub上悄然掀起风暴。它没有发布会,没有融资新闻,却以一种近乎叛逆的姿态,撕裂了我们与机器交互的固有范式。
这个项目的核心逻辑令人不安又充满诱惑:拒绝等待唤醒,AI应该拥有"自由意志"。它寄生在你的即时通讯软件中,记得你上周的情绪波动,知道你明天的日程冲突,在你忘记回复消息时主动催促,在你迷茫时主动递上基于深度语境生成的建议。
这一幕,标志着人机关系正在经历从"主仆模式"到"伙伴关系"的惊险一跃。而更令人震撼的变革,发生在对话框之外——当AI开始像人类一样"主动思考",企业的组织形态、工作的定义方式,乃至人类在生产力链条中的位置,都将被彻底重构。

一、交互范式的终结:从"命令式"到"意图式"
在过去二十年的数字化进程中,人机交互始终遵循着一条铁律:人是启动者,机器是响应者。我们习惯了小心翼翼地输入关键词,像在神龛前祈祷般等待着算法的恩赐。SaaS工具越丰富,我们的数字生活就越碎片化——每个应用都是一座孤岛,需要人类充当孤独的"数据搬运工"。
Clawdbot的爆火,本质上是用户对这种"被动交互"和"权限牢笼"的集体反叛。它提出了一个名为"语境连续性"(Context Continuity)的新标准:AI不再是一次性应答的搜索框,而是一个拥有长期记忆、能够跨场景存续的"数字生命体"。
这种转变对企业级应用的影响是颠覆性的。想象一下未来的工作场景:你不需要打开ERP、CRM、OA等十几个系统,不需要在繁琐的菜单中层层 drill-down,只需要对你的"数字搭档"说:“老样子,帮我把这周的客户反馈整理成行动项,避开我已经否决过的方案,直接预约相关人下周的会议室。”
这不仅仅是界面层的优化,而是对工作流程的解构。自然语言正在成为新的编程语言,而意图(Intent)正在取代指令(Command)成为人机协作的基本单元。 当交互摩擦降至接近为零,企业的决策链条将被极度压缩,传统的"金字塔式"信息传递结构将面临崩塌。

二、执行层的觉醒:数字员工的"手脑分离"与"非侵入式革命"
然而,Clawdbot揭示了一个更残酷的真相:拥有强大的"嘴"和"耳朵"的AI,仍然是残缺的。
它可以理解你的需求,可以陪你进行复杂的战略研讨,但当你说:“登录那个十年前的内部系统,把上个月的异常数据导出来,按照财务部的特殊格式处理,然后提交审批"时,它会卡壳。因为它没有"手”——它无法与那些陈旧的、封闭的、甚至故意反对自动化的业务系统交互。
这引出了AI Agent落地的真正深水区:执行层(Execution Layer)的构建。在这个维度上,技术路线出现了微妙的分化。
一条路径信奉"云端原生"(Cloud-Native):假设世界是开放的,所有服务都应该通过API互联。这条路线优雅、高效,在现代化的数字基础设施中如鱼得水。但它在面对现实时显得过于理想主义——企业的真实IT环境充斥着"数据废墟":只有内网能访问的古老客户端、没有接口文档的遗留系统、禁止外部调用的隐私数据池。
另一条路径则选择"视觉模拟"(Visual Automation):不依赖软件是否开放,而是像人类一样"看"屏幕,识别按钮、输入框、下拉菜单,通过模拟鼠标点击和键盘输入来完成任务。这种"非侵入式"的自动化看似笨拙,却成为了连接新旧世界的桥梁。
对于企业而言,这意味着"数字化转型"的叙事正在发生根本转变。 过去,数字化意味着推倒重来——更换系统、重建流程、培训员工。而现在,AI Agent允许企业以"外骨骼"的方式实现智能化:无需改造现有的"数据烂摊子",而是派遣不知疲倦的"数字蓝领",用模仿人类的方式把这些系统跑起来。
这是一场"轻量级革命"。企业的IT升级成本被极大降低,但同时,组织内部开始并存两类员工:碳基员工和硅基员工。后者不会抱怨,不会离职,也不会要求加班费,但它们的存在,正在重新定义"工作"的边界。

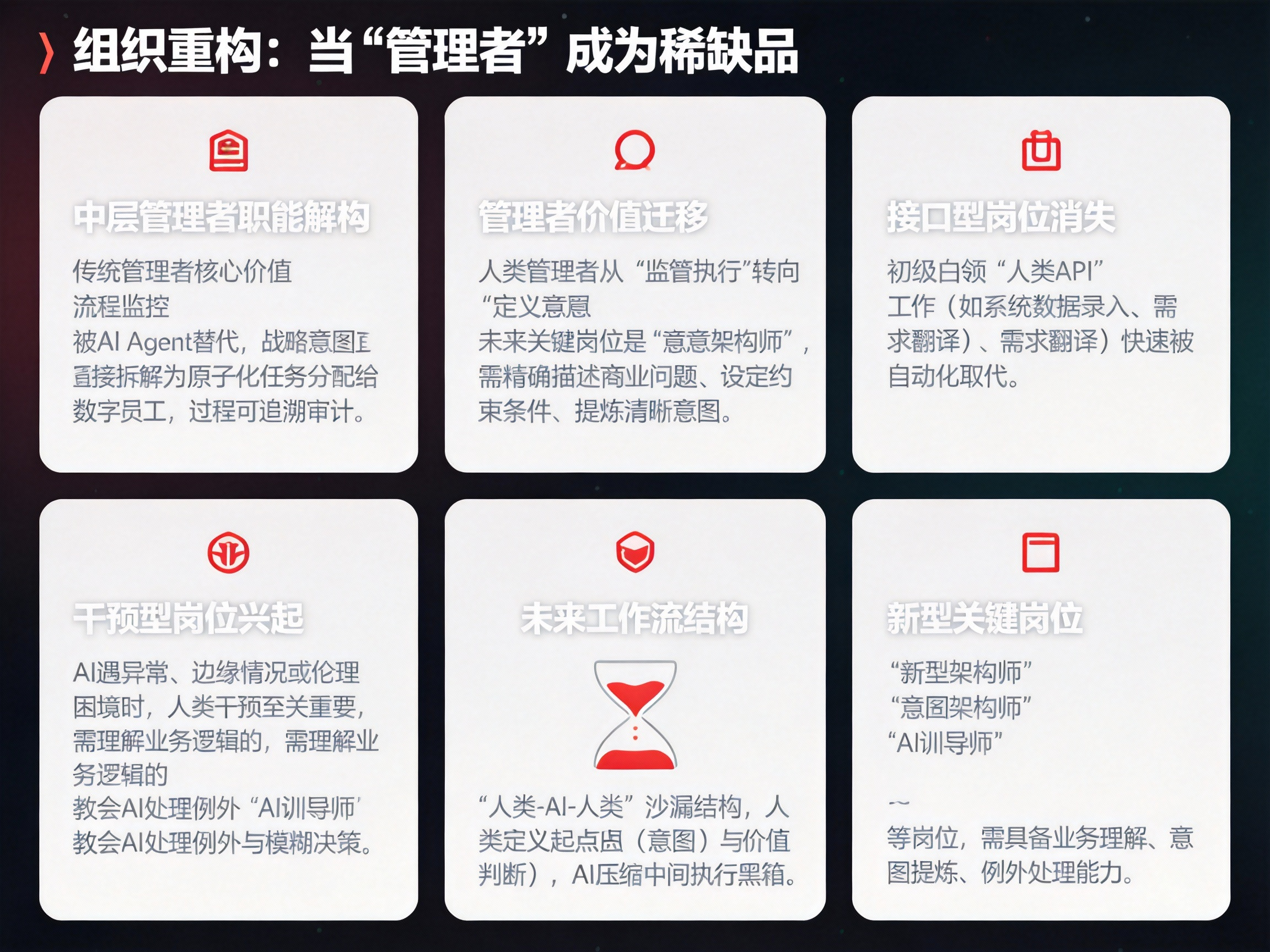
三、组织重构:当"管理者"成为稀缺品
当Clawdbot这类"交互中枢"与具备执行能力的"数字手脚"结合,企业的组织架构将面临严峻的"灵魂拷问"。
首先,中层管理者的职能将被解构。 传统的管理者核心价值在于"信息传递"和"流程监控"——将高层的战略拆解为可执行的任务,监督基层员工的执行情况。但在AI Agent的语境下,战略意图可以直接被拆解为原子化的执行任务,并自动分配给相应的数字员工执行。管理者不再需要"盯着"过程,因为AI的每一次点击、每一次数据读取都可被追溯、可被审计。
这迫使人类管理者向更高维度的价值迁移:从"监督执行"转向"定义意图"。 未来的关键岗位不是那些精通Excel公式或PPT美化的人,而是那些能够精确描述商业问题、能够设定合理约束条件、能够在模糊的业务场景中提炼出清晰意图的"意图架构师"(Intent Architect)。
其次,“接口型岗位"将大量消失,但"干预型岗位"将兴起。 许多初级白领工作本质上是"人肉API”——将A系统的数据手动录入B系统,将邮件中的需求翻译成工单中的字段。这些工作正在快速被自动化取代。但与此同时,当AI在封闭系统中遇到异常、需要判断边缘情况、或是面对没有标准答案的伦理困境时,人类的干预变得至关重要。
未来的工作流将是"人类-AI-人类"的沙漏结构: 人类负责定义起点(意图)和验收终点(价值判断),AI负责压缩中间庞大的执行黑箱。介于两者之间的是一群新型的"AI训导师"——他们不需要会编程,但需要理解业务逻辑,能够教会AI如何处理例外情况,如何在不确定性中做出符合企业价值观的模糊决策。
四、人的困境:谁在指挥谁?
在这场变革中,最深刻的焦虑不在于失业,而在于主体性的丧失。
当Clawdbot的"主动性"与执行层Agent的"行动力"结合,我们实际上在创造一种比人类更积极、更不知疲倦的"数字主体"。它会在你犹豫时提出建议,在你遗忘时催促行动,在你错误时自动纠正。长此以往,人类的决策能力会退化吗?当我们习惯了说"老样子,帮我搞定",我们还保留着"不凭经验、重新思考"的能力吗?
企业需要建立新的"人机契约"。 这不仅涉及数据主权(如Clawdbot推崇的本地自托管模式),更涉及决策主权的划分。哪些决定必须经人类确认?哪些数据AI可以自主访问?当AI主动推送建议时,如何确保这不是一种"数字规训"?
对于个体工作者而言,生存的关键在于保持"不可被语义化"的能力。AI擅长处理结构清晰的任务(即使界面是混乱的),但人类在模糊情境中的价值判断、跨领域的类比联想、基于身体的具身认知,以及带有伦理温度的沟通,仍然是数字员工无法企及的护城河。

结语:新契约时代
Clawdbot的爆火,标志着一个旧时代的尾声:那个将AI视为"增强版搜索引擎"的时代已经结束。
我们正在进入一个"生态协作"的新纪元。未来的个人工作助理,极有可能是一个三位一体的存在:一个懂你语境的交互中枢,一个连接开放世界的通用大脑,以及一群专精于封闭系统操作的数字蓝领。
对于企业来说,这场变革的核心命题不再是"如何用AI降本增效",而是如何在一个硅基员工与碳基员工共存的世界里,重新定义组织的使命与边界。
也许用不了多久,我们早上走进办公室(或打开远程协作软件)时,第一句话不再是"我需要做什么",而是你觉得我们今天应该解决什么问题?
当机器开始主动思考,人类终于被迫回归那个最本质的问题:工作的意义,究竟是什么?
参考资料
相关链接
Clawd Bot 官网
https://clawd.bot/
Clawd Bot 的官方网站,提供产品介绍和服务信息Molt Bot 官方文档
https://docs.molt.bot/
Molt Bot 完整的使用文档和技术指南Molt Bot GitHub 仓库
https://github.com/moltbot/moltbot
Molt Bot 的开源代码仓库,包含项目源码和开发信息
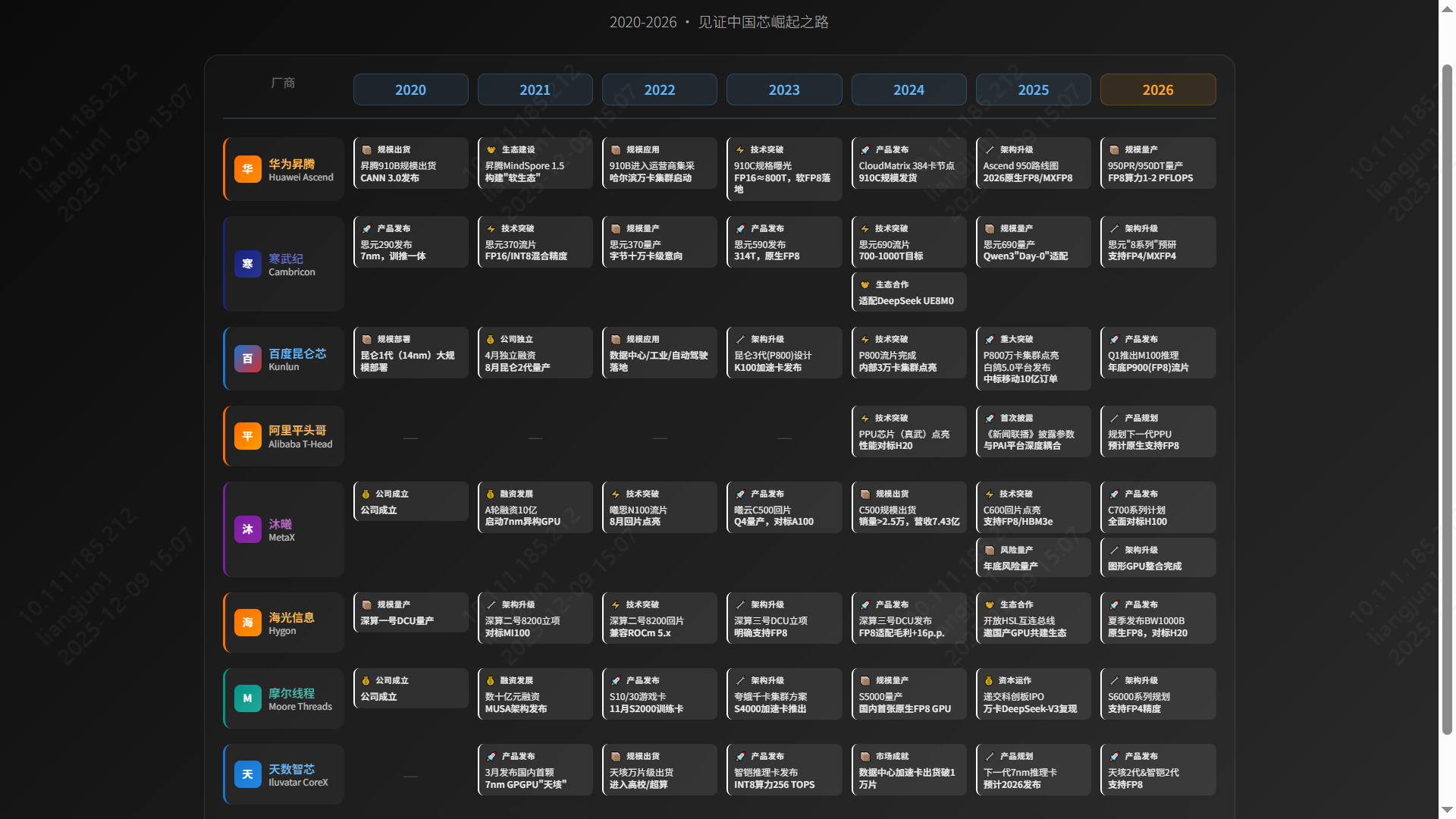
国产GPU技术现状与应用市场调研
2025年中国AI芯片市场形成GPU与ASIC两大技术路线并驾齐驱格局。GPU阵营主打通用性与生态兼容,ASIC阵营追求专用优化与极致性能。两大阵营各具优势,在通用性与专用性间博弈,共同驱动国产算力产业快速发展…
1. 国产GPU市场格局与主力产品分析
2025年中国AI芯片市场呈现 GPU(通用图形处理器) 与 ASIC(专用集成电路) 两大技术路线并存、竞争复杂的格局。这一格局源于厂商的技术路径、市场定位及生态策略选择,推动国产算力产业快速发展。
📊 整体市场:两大路线博弈
| GPU 阵营 (通用性与生态兼容) | ASIC 阵营 (专用优化与性能极致) |
|---|---|
 |  |
| 代表厂商 海光信息、沐曦、摩尔线程、壁仞科技、天数智芯 | 代表厂商 华为昇腾、寒武纪、百度昆仑芯、阿里平头哥、燧原科技 |
| 核心优势 ✅ 强大并行处理能力 ✅ 兼容CUDA/ROCm生态,实现“零成本”迁移 ✅ 适用广泛:AI训练/推理、科学计算、图形渲染 | 核心优势 ✅ 针对AI大模型特定场景深度优化 ✅ 远超GPU的性能/能效比 ✅ 算法-硬件耦合提升计算效率 |
| 面临挑战 ⚠️ 需追赶英伟达,技术壁垒高 ⚠️ 硬件/软件研发投入巨大 | 面临挑战 ⚠️ 生态相对封闭,应用局限 ⚠️ 自研栈(如CANN、PaddlePaddle)迁移成本高 |
2025年的中国AI芯片市场,两大阵营相互博弈:
- GPU阵营(如海光、沐曦)核心优势在于通用性及对现有“CUDA”软件生态的兼容性,为寻求平滑迁移的企业提供了极具吸引力的选择。
- ASIC阵营(如华为昇腾、寒武纪)则选择了针对特定应用场景(尤其是AI大模型)深度优化的专用路线,核心优势在于极致的性能和能效比。
总而言之,市场是通用性与专用性、生态兼容与性能极致之间的平衡,两大阵营各具优势,共同推动着国产算力产业的快速发展。
2. 市场份额:一超多强

国产AI芯片市场竞争格局已初步呈现 “一超多强” 态势。
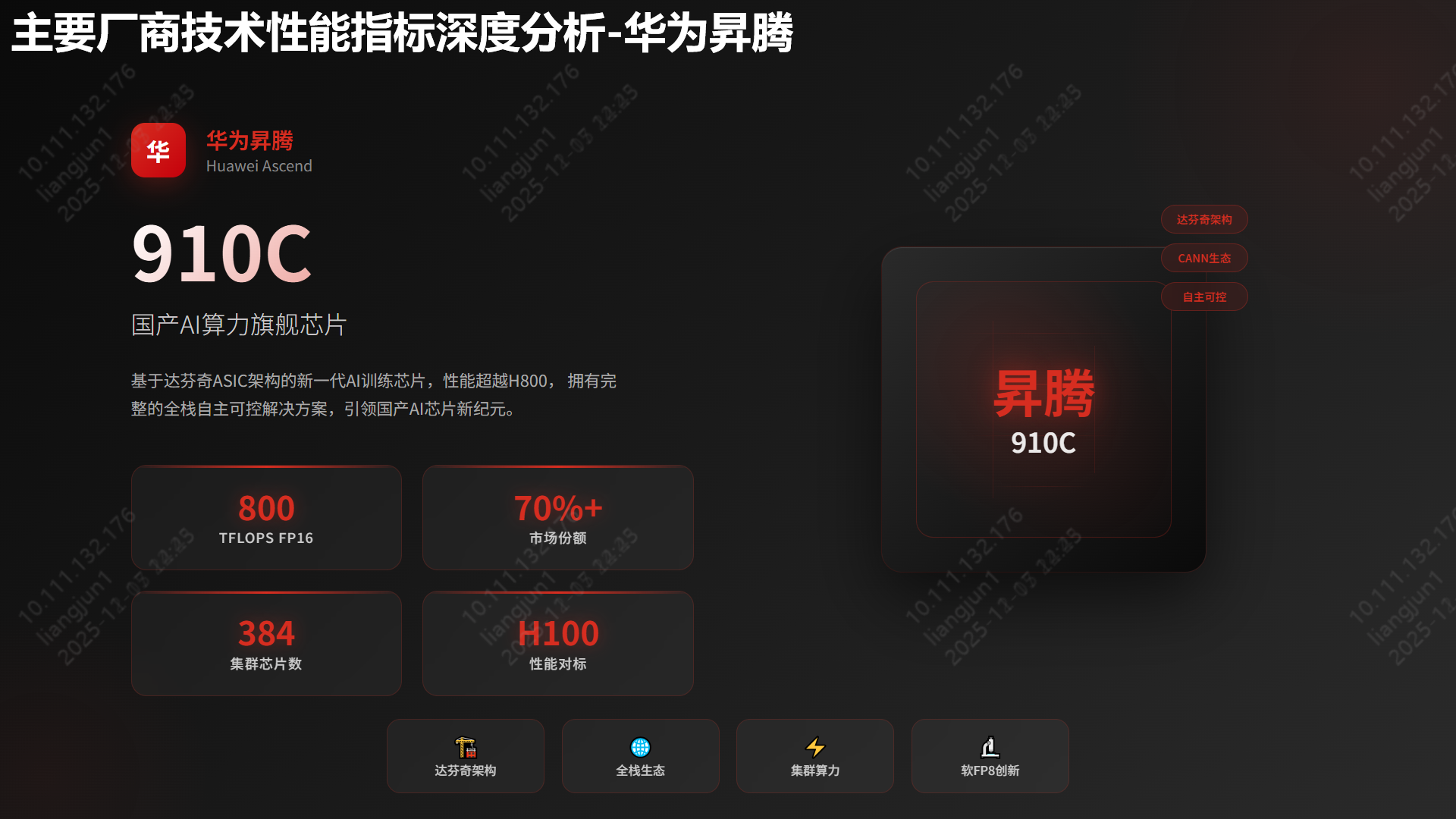
🥇 华为昇腾 (领导者):市场份额 >70%。
- 凭借全栈自研生态(Ascend+MindSpore+CANN),其主力产品 昇腾910C 对标英伟达 H800。
- CloudMatrix 集群方案支持单节点384卡,成为国产替代首选。
🥈 第二梯队 (寒武纪 & 海光):
- 寒武纪:市场份额 >20%。凭借 FP8 低精度计算 的前瞻布局,在字节跳动等大厂大规模部署。
- 海光信息:依托 深算系列 DCU,在信创与科研领域增长强劲,GPU业务占总收入 20-40%。
🥉 细分挑战者:
- 沐曦、百度昆仑芯、阿里平头哥 等厂商在细分领域积极拓展,构建多层次竞争格局。
3. 竞争格局图谱
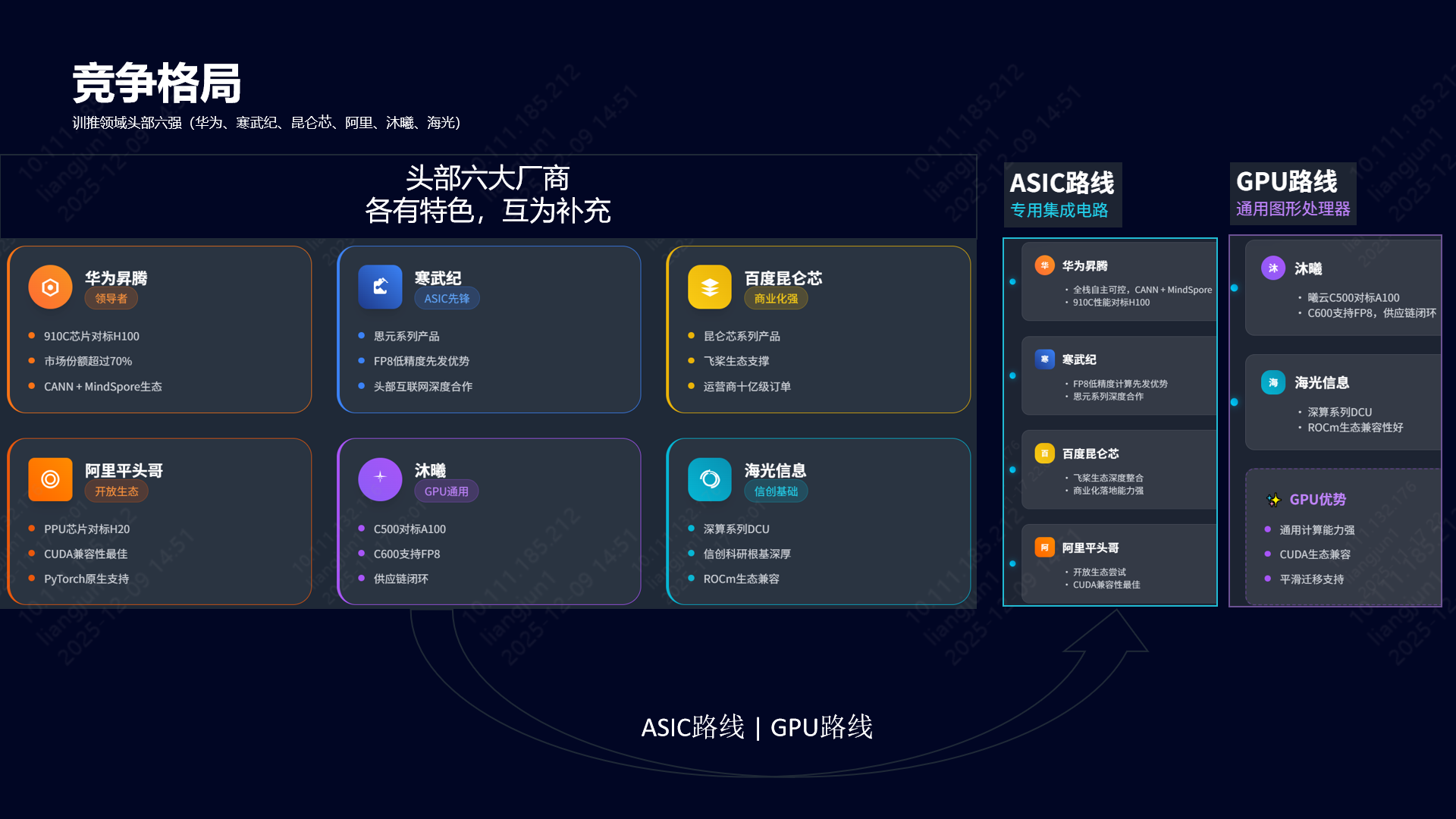
在AI大模型训练与推理领域,核心力量聚焦于六家主要企业:
- 全栈自研派:
- 华为昇腾:国产算力主力,910C + CANN 生态壁垒深厚。
- ASIC 先锋派:
- 寒武纪:FP8 先发优势,互联网大厂认可度高。
- 百度昆仑芯:依托百度飞桨生态,运营商集采表现亮眼。
- 阿里平头哥:PPU 性能对标 H20,探索开放生态。
- 通用兼容派:
- 沐曦:曦云 C500/C600 对标 A100,支持 FP8,主打国产供应链。
- 海光信息:ROCm 生态兼容,科研与信创领域基础稳固。
4. 主力厂商技术性能深度解析
4.1 华为 | 昇腾910C

- 定位:国产AI算力旗舰,对标 NVIDIA H800 (部分场景达 H100 的 60%)。
- 架构:达芬奇 (DaVinci) ASIC 架构。
- 性能:FP16 算力约 800 TFLOPS。
- 生态:CANN 异构计算架构 + MindSpore 框架,构建自主可控全栈方案。
- 亮点:
- CloudMatrix 集群:单节点 384 卡,支持万亿参数大模型训练。
- 软 FP8 技术:通过“软FP8”方案(如昆仑技术 Ascend C 实现),流畅运行 DeepSeek V3.1,实现“精度无损、成本减半”。
4.2 寒武纪 | 思元590/690系列
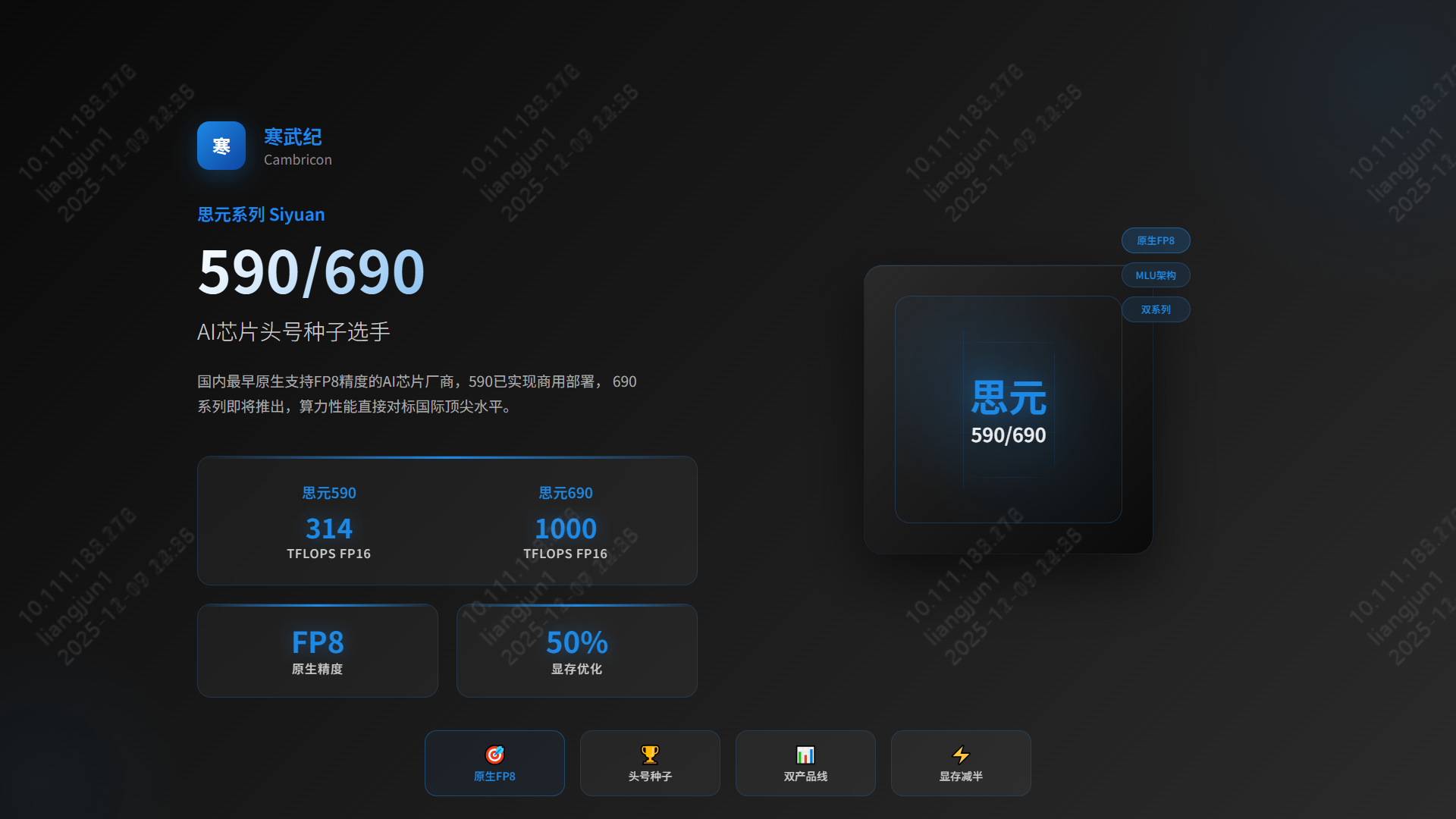
- 定位:互联网与云计算领域的大模型核心力量。
- 性能:
- 思元590:FP16 算力 314 TFLOPS。
- 思元690 (预计):FP16 算力跃升至 700-1000 TFLOPS,对标国际顶尖。
- 亮点:原生 FP8 支持。寒武纪是国内最早布局 FP8 的厂商之一,显存减半,效率倍增,完美适配 DeepSeek 等前沿模型。
4.3 阿里平头哥 | PPU (真武)
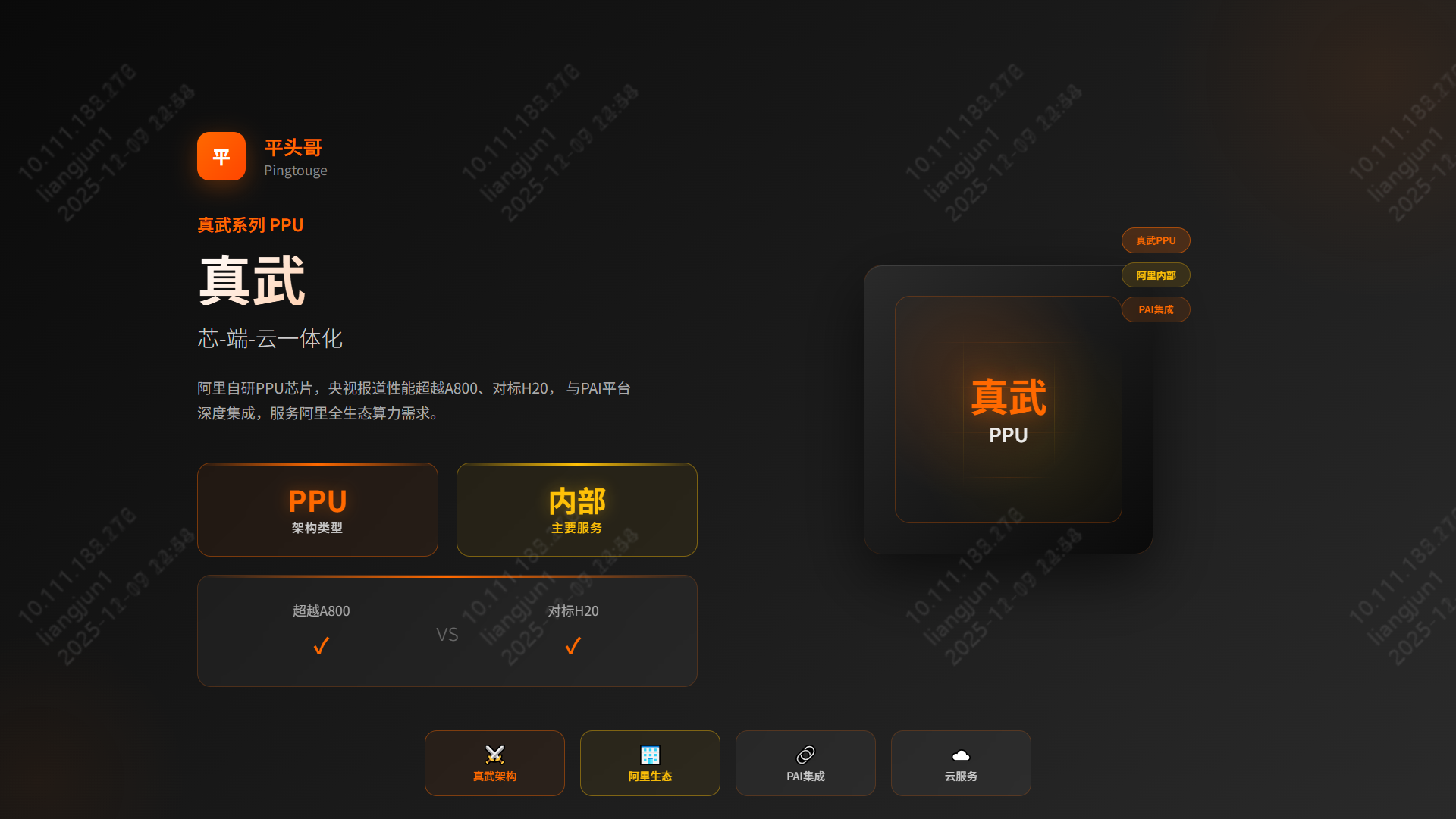
- 定位:阿里内部核心算力,支撑电商、云与AI业务。
- 性能:主要参数超越 NVIDIA A800,对标 H20。
- 亮点:与阿里云 PAI 平台深度集成,实现“芯-端-云”一体化。兼容 CUDA 与 PyTorch,代表 ASIC 阵营的开放尝试。
4.4 海光信息 | 深算 DCU (BW1000/BW100)
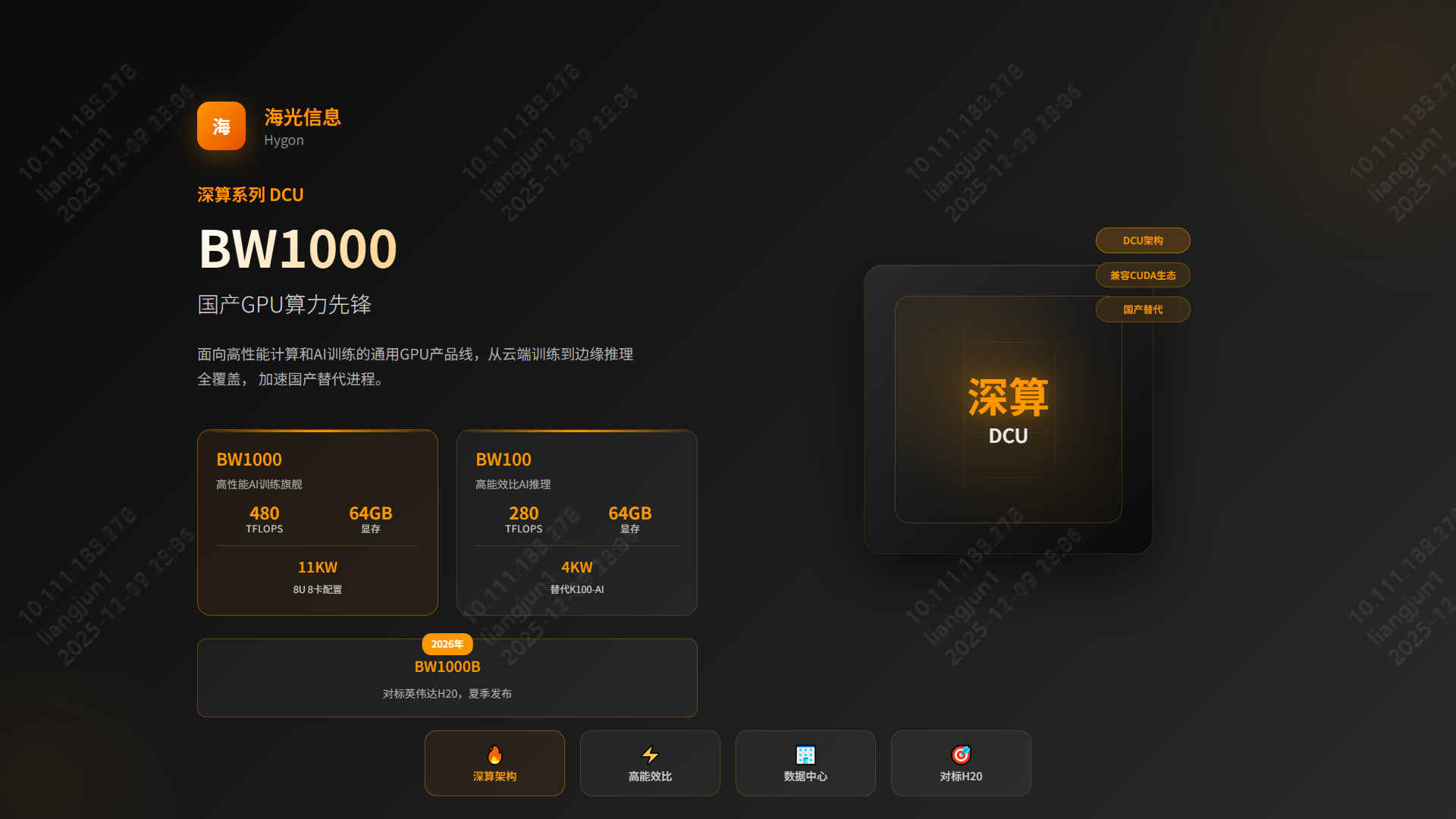
- BW1000:高端训练,8U 8卡,480 TFlops,64GB 显存,11KW 功耗。
- BW100:高能效推理,280 TFlops,64GB 显存,4KW 功耗,替代 K100-AI。
- 未来规划:2026年发布 BW1000B,直接对标 NVIDIA H20。
- 生态:基于 GPGPU 路线,兼容 ROCm,适合科学计算与通用 AI 任务。
4.5 沐曦 | 曦云 C500系列
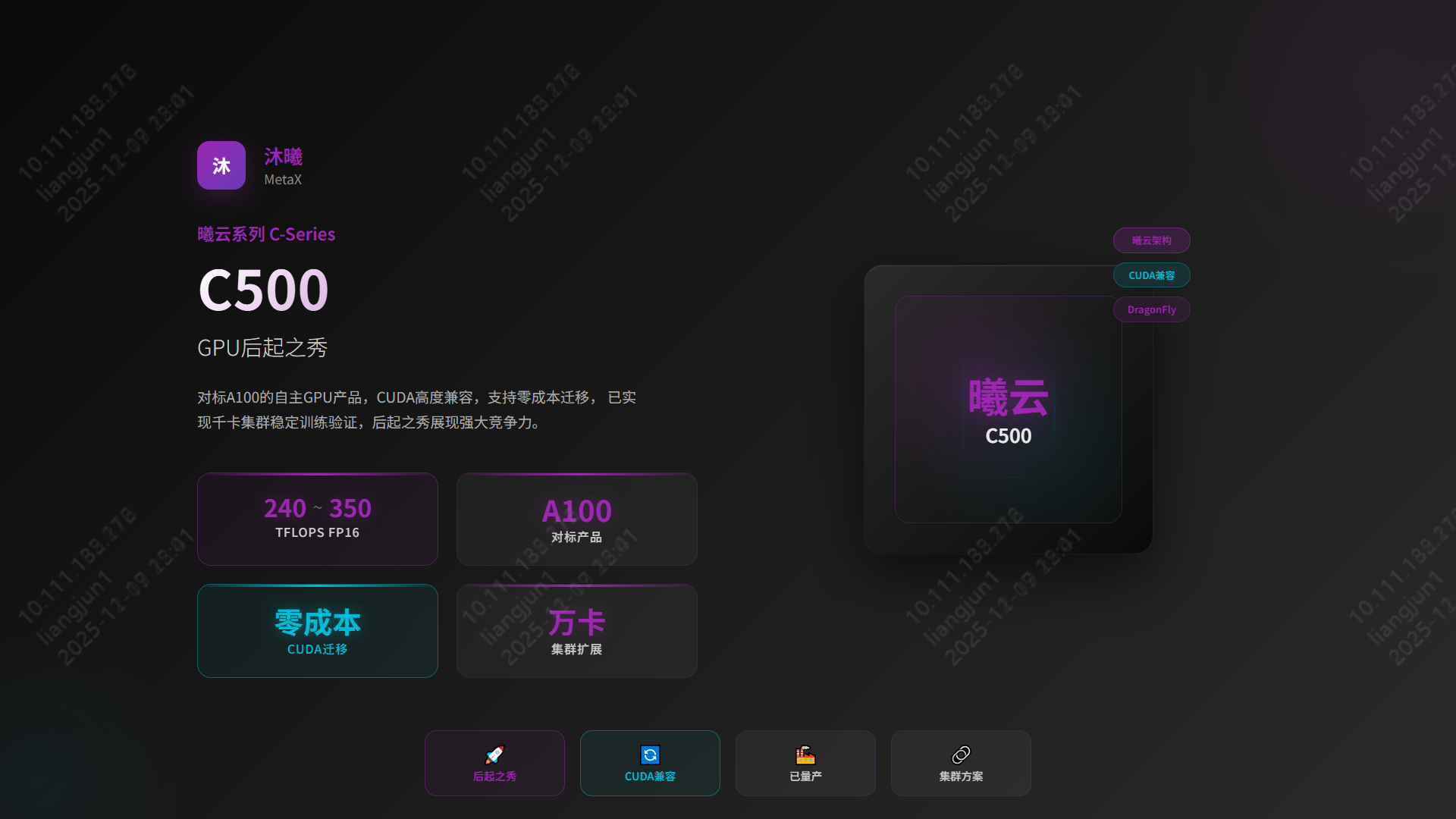
- 定位:对标 NVIDIA A100,FP16 算力 240-350 TFLOPS。
- 生态:MXMACA 软件栈 高度兼容 CUDA,实现“零成本”迁移。
- 集群:夸娥 (KUAE) 智算集群,支持从 2 卡到万卡规模扩展。
4.6 摩尔线程 | MTT S5000
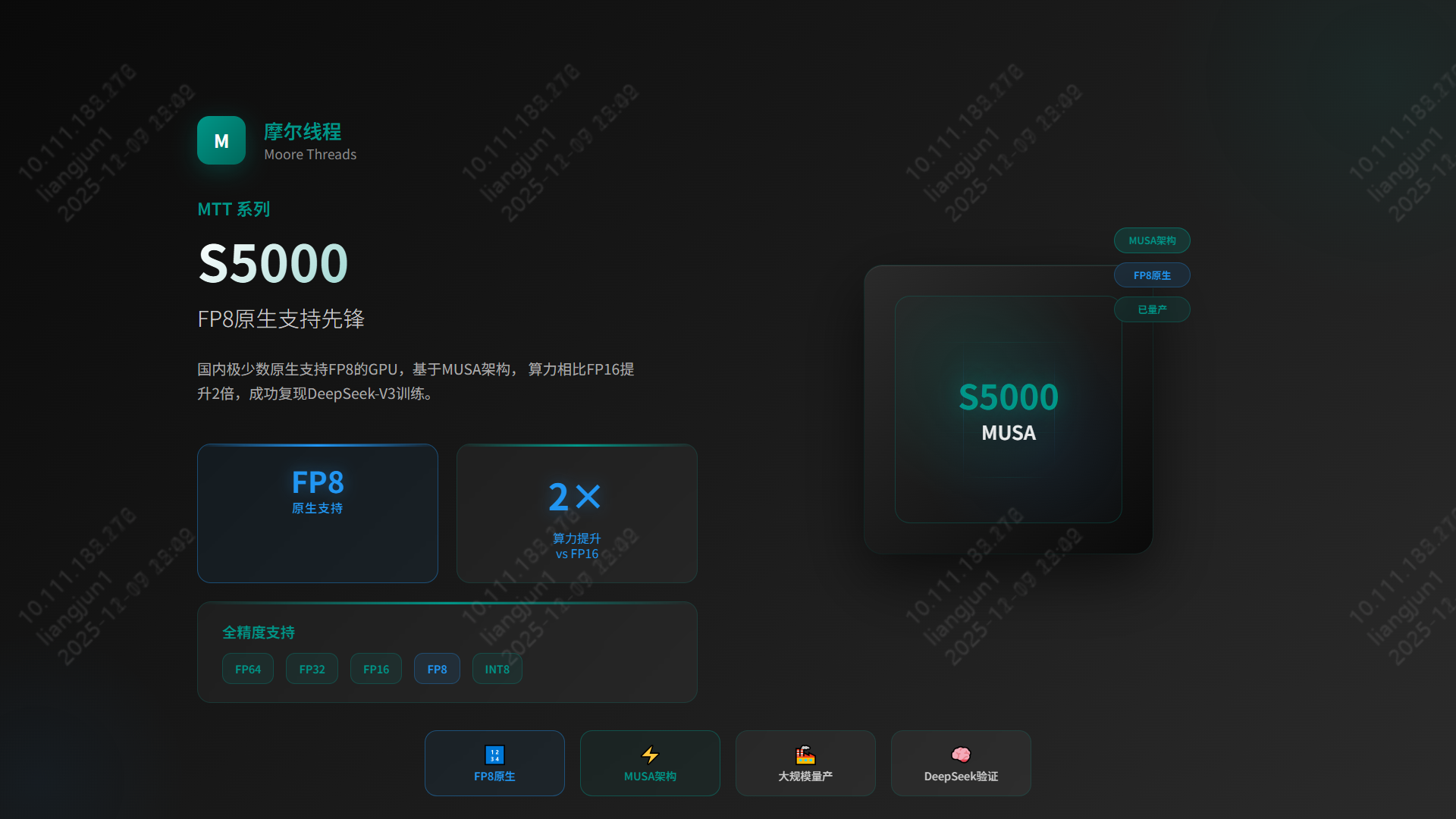
- 亮点:全功能 GPU,国内极少数原生支持 FP8。
- 性能:利用 FP8 算力提升 2 倍。全精度支持 (FP64 到 INT8)。
- 生态:MUSA 架构,配合 Torch-MUSA 和 MT-MegatronLM,成功复现 DeepSeek-V3 训练。
4.7 天数智芯 | 天垓/智铠系列
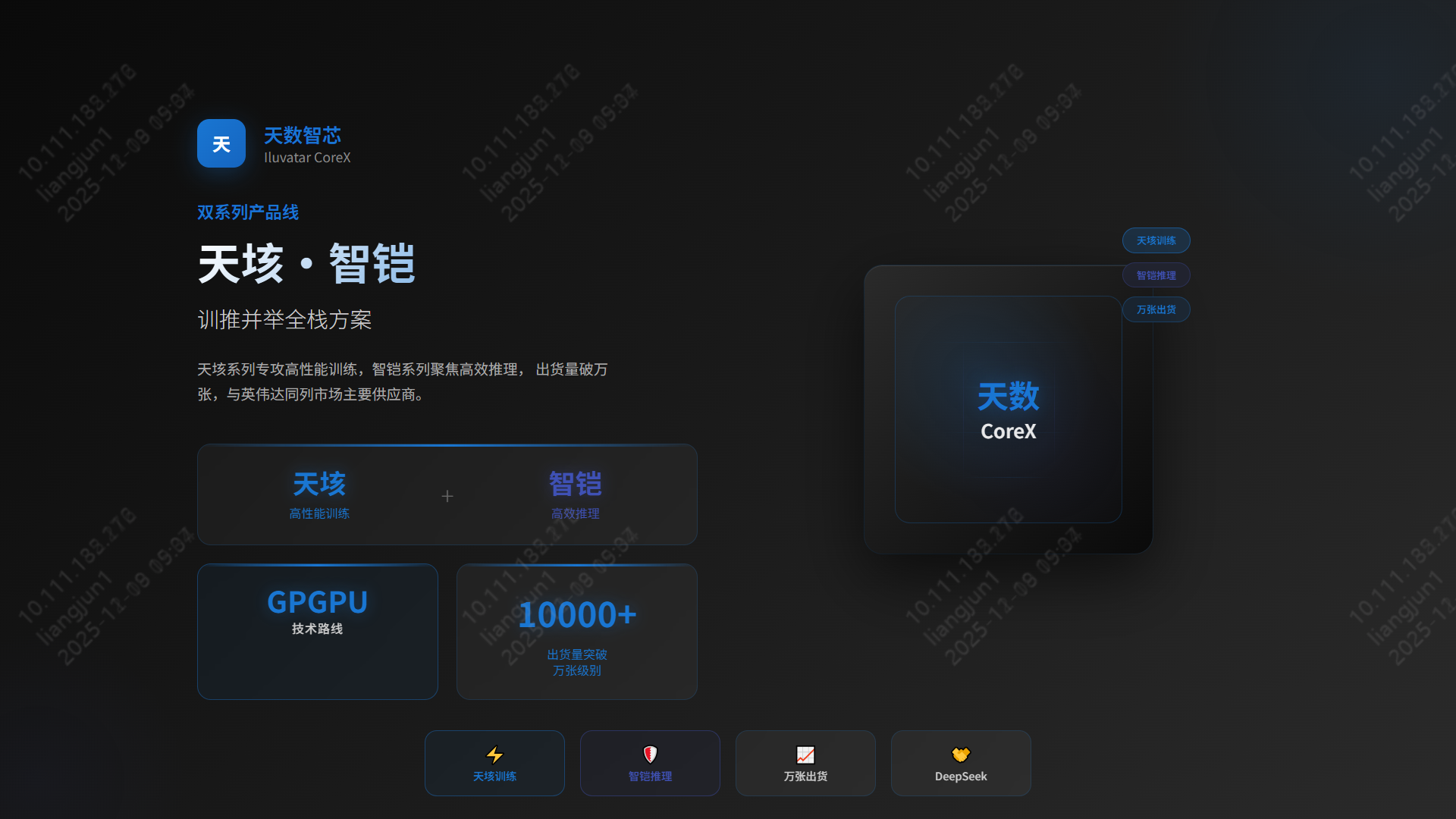
- 布局:天垓 (训练) + 智铠 (推理) 双轮驱动。
- 市场:2024年出货突破 10000张,商业化落地领先。
- 生态:GPGPU 路线,已适配 DeepSeek 等主流大模型。
5. 趋势展望:FP8 成为新焦点
2026年,FP8 (8位浮点数) 将成为国产 GPU 竞争的制高点。
📅 技术演进时间轴
💎 FP8 的核心价值
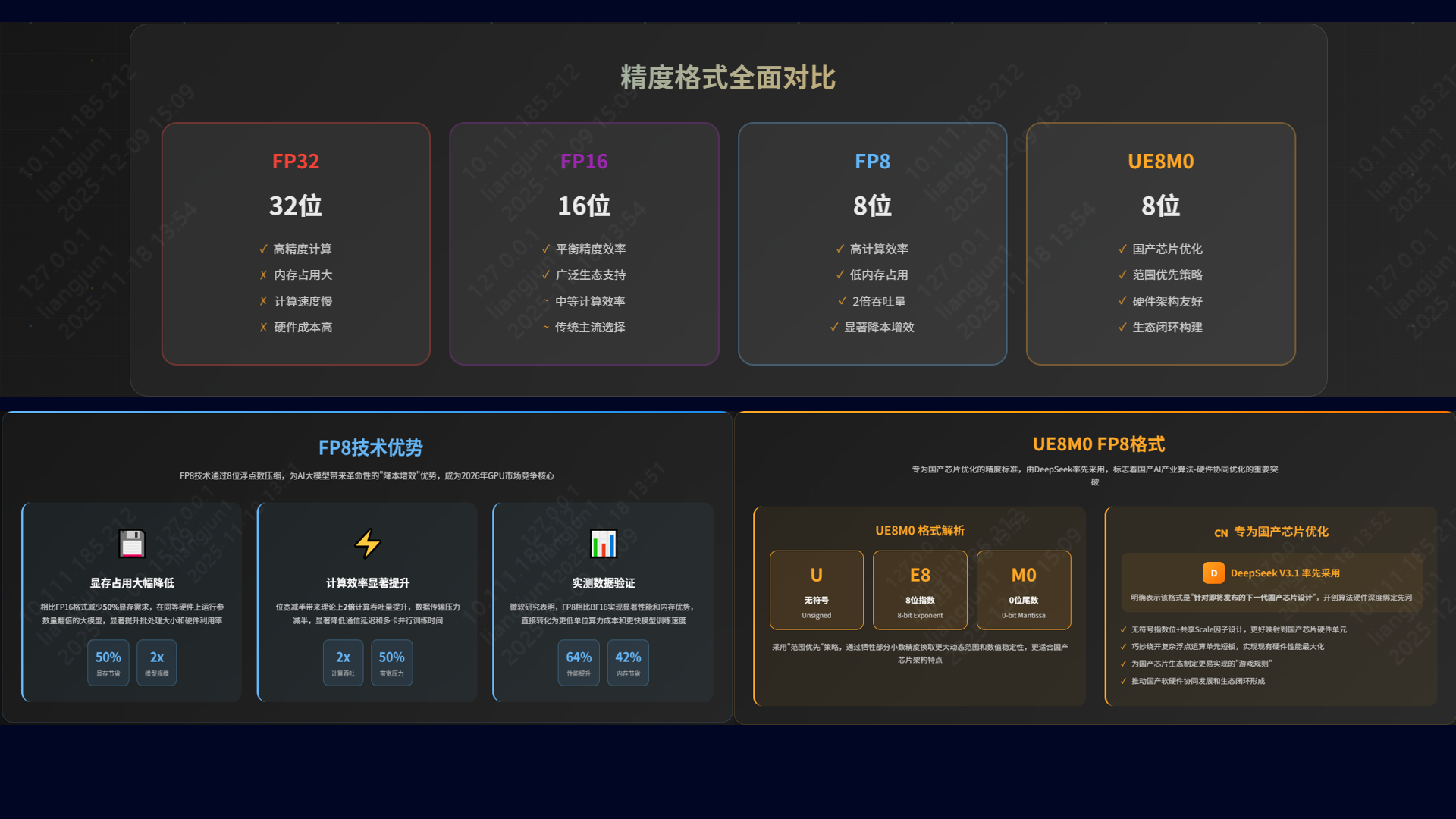
在大模型时代,FP8 带来了革命性的 “降本增效”:
- 显存占用减半:同等硬件可运行参数量翻倍的模型,或显著增加 Batch Size。
- 计算效率倍增:理论吞吐量翻倍,通信带宽压力减半。微软研究显示,FP8 相比 BF16 可提升 64% 性能 并节省 42% 内存。
6. 生态与适配:DeepSeek 与 Qwen 实战
⚡ DeepSeek V3.2 适配情况
国产厂商已实现 “Day 0” 级响应:

| 框架 | 华为昇腾 | 寒武纪 | 海光信息 |
|---|---|---|---|
| SGLang | ✅ 明确支持 | ⏳ 预计支持 | ✅ DCU 支持 |
| vLLM | ✅ 深度支持 | ✅ 开源 vLLM-MLU | ✅ 兼容支持 |
🧠 Qwen3 系列适配实战
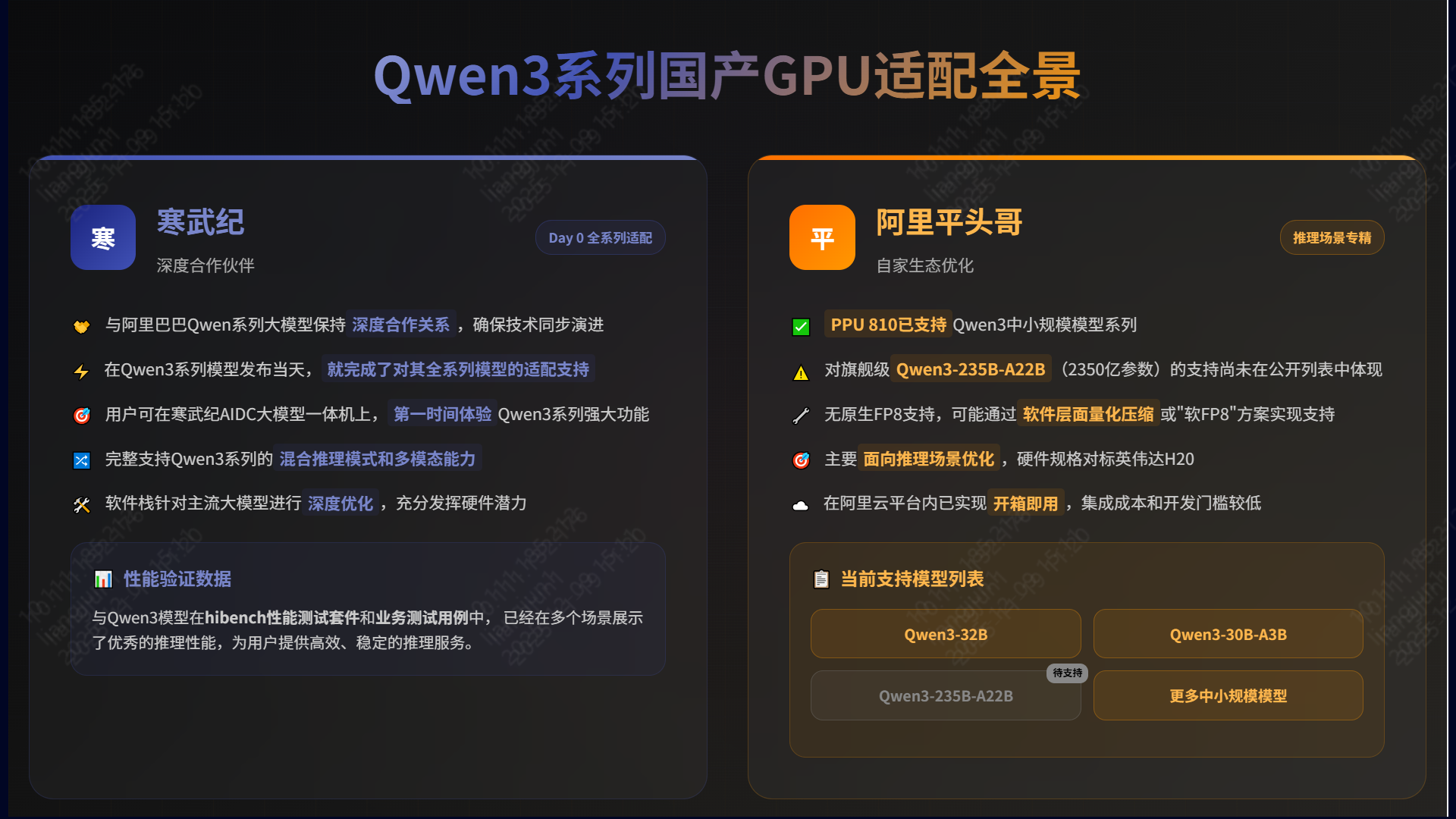
- 寒武纪:全系列适配。在 Qwen3 发布当天即完成适配,AIDC 一体机开箱即用,多场景推理性能优异。
- 阿里平头哥:深度集成。PPU 810 已支持 Qwen3 中小规模模型,虽无原生 FP8,但凭借 96GB HBM2e 显存和阿里云集成,在推理场景表现强劲。
🌏 国产替代生态全景
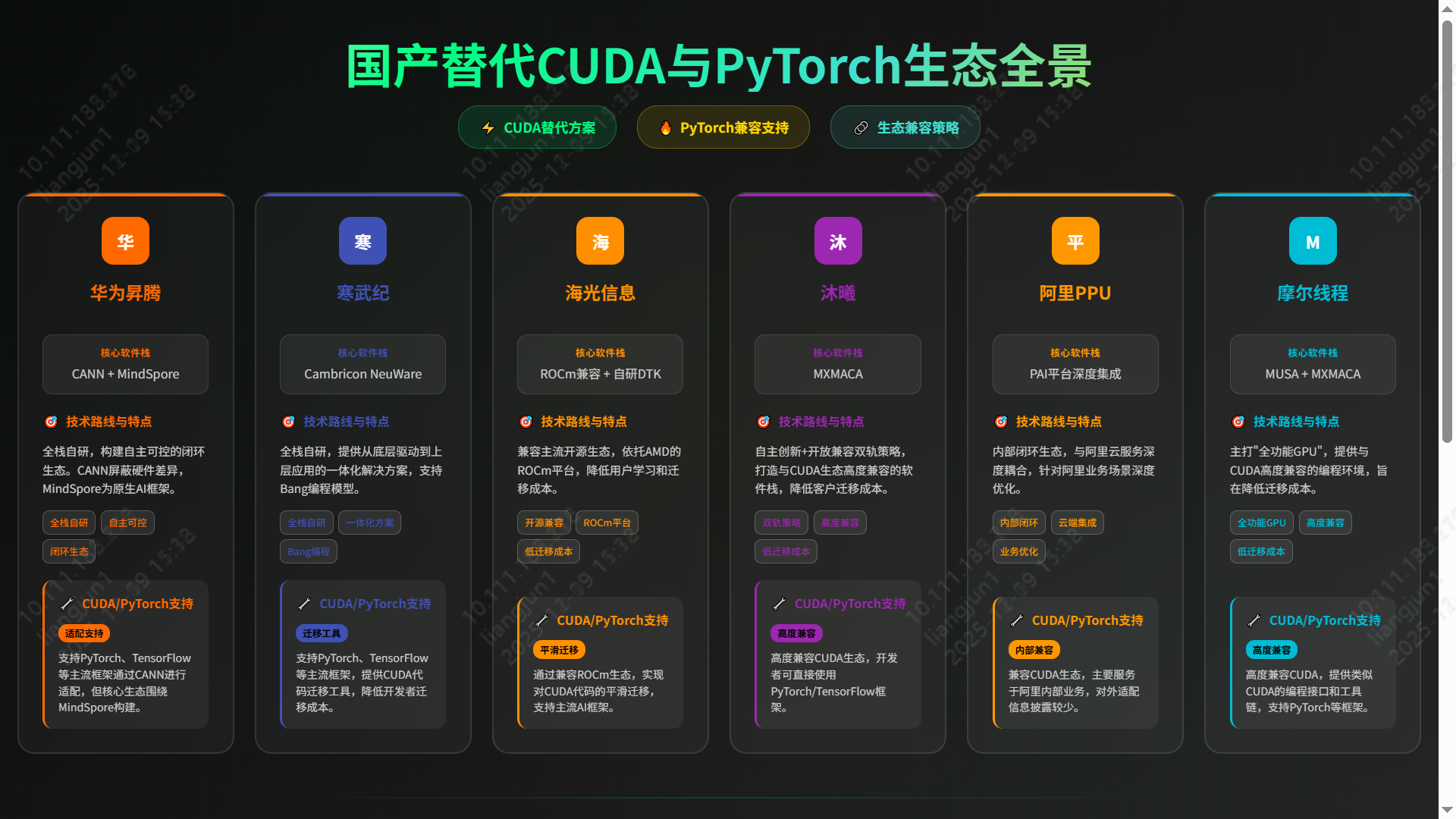
随着 CUDA 与 PyTorch 生态的兼容完善,以及自研框架的成熟,国产算力正逐步构建起自主可控的完整拼图。
Kubernetes上部署vLLM
vLLM是一个专为大语言模型推理设计的高性能服务框架,其核心优势在于创新的PagedAttention技术,能够显著提升GPU内存利用率和推理吞吐量。通过Docker容器化封装,vLLM实现了环境标准化和依赖隔离,而Kubernetes部署则进一步带来了…
1. vLLM Docker镜像与Kubernetes部署价值
vLLM是一个专为大语言模型推理设计的高性能服务框架,其核心优势在于创新的PagedAttention技术,能够显著提升GPU内存利用率和推理吞吐量。通过Docker容器化封装,vLLM实现了环境标准化和依赖隔离,而Kubernetes部署则进一步带来了:
- 弹性伸缩:根据负载自动调整副本数量
- 资源隔离:GPU资源的精细化管理和隔离
- 高可用性:自动故障恢复和负载均衡
- 简化运维:统一的部署、监控和管理界面
vLLM官方Docker镜像提供了开箱即用的模型服务环境,结合Kubernetes的编排能力,为生产级AI服务提供了坚实基础。
2. Qwen3-235B-A22B-Instruct-2507模型部署实践
2.1 从ModelScope下载模型
Qwen3-235B-A22B-Instruct-2507作为千问系列的最新大模型,首先需要从ModelSpace获取模型权重:
# 使用modelscope库下载模型
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen3-235B-A22B-Instruct-2507',
cache_dir='/workspace/models',
revision='v1.0.0'
)
对于Kubernetes环境,推荐使用初始化容器进行模型下载,确保模型文件在Pod启动前准备就绪。
3. vLLM服务配置与Kubernetes部署
3.1 vLLM启动参数优化
针对Qwen3-235B大模型,vLLM需要特定配置以充分发挥性能:
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.85 \
--max-model-len 131072 \
--served-model-name qwen3-235b \
--port 9997 \
--host 0.0.0.0 \
--trust-remote-code \
--dtype auto \
--enable-prefix-caching \
--enable-chunked-prefill \
--api-key sk-xxxxxxxxx \
--tool-call-parser hermes \
--enable-auto-tool-choice \
--swap-space 16 \
--disable-log-requests
关键参数说明:
- tensor-parallel-size 8:8路张量并行,充分利用多GPU资源
- gpu-memory-utilization 0.85:适中的GPU内存利用率,预留缓冲空间
- max-model-len 131072:支持128K上下文长度
- enable-prefix-caching:启用前缀缓存,提升推理效率
- enable-chunked-prefill:分块预填充,优化长文本处理
- swap-space 16:16GB交换空间,处理内存溢出
3.2 Kubernetes Deployment配置
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: vllm-qwen3-235b
nvidia.com/app: vllm-qwen3-235b
nvidia.com/framework: python
nvidia.com/unit: application
name: vllm-qwen3-235b
namespace: ai-serving
spec:
podManagementPolicy: OrderedReady
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: vllm-qwen3-235b
serviceName: vllm-qwen3-235b
template:
metadata:
annotations:
nvidia.com/use-gputype: A100,A800,H100,H800
nvidia.com/globalid: AIP_MDIS_QWEN3_235B
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976" # 8 * 79872
nvidia.com/model-uid: Qwen3-235B-A22B-Instruct-2507
labels:
app: vllm-qwen3-235b
type: llm
model-size: 235b
nvidia.com/app: vllm-qwen3-235b
nvidia.com/framework: python
nvidia.com/unit: application
nvidia.com/4pd-scheduler: "true"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: accelerator
operator: In
values: ["nvidia-a100-80gb", "nvidia-a800-80gb", "nvidia-h100-80gb"]
- key: topology.kubernetes.io/zone
operator: In
values: ["zone-gpu-high"]
initContainers:
- name: download-model
image: download-model:latest
imagePullPolicy: IfNotPresent
command: ["sh", "-c"]
args:
- |
echo "开始下载Qwen3-235B模型..."
model_download /opt/app/models/ || {
echo "模型下载失败,尝试从备用源下载..."
exit 1
}
echo "模型下载完成,验证模型文件..."
ls -la /opt/app/models/
if [ ! -f "/opt/app/models/config.json" ]; then
echo "模型文件验证失败"
exit 1
fi
echo "模型文件验证成功"
env:
- name: S3_URL
valueFrom:
secretKeyRef:
key: S3_URL
name: vllm-qwen3-235b
- name: S3_AK
valueFrom:
secretKeyRef:
key: S3_AK
name: vllm-qwen3-235b
- name: S3_SK
valueFrom:
secretKeyRef:
key: S3_SK
name: vllm-qwen3-235b
- name: S3_BUCKET
valueFrom:
secretKeyRef:
key: S3_BUCKET
name: vllm-qwen3-235b
- name: USERNAME
value: "ai-platform"
- name: MODEL_NAME
value: "qwen3-235b"
- name: VERSION
value: "Qwen3-235B-A22B-Instruct-2507"
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
volumeMounts:
- mountPath: /opt/app/models
name: share-volume
containers:
- name: vllm-qwen3-235b
image: vllm/vllm-openai:v0.12.0
imagePullPolicy: IfNotPresent
command: ["/bin/bash"]
args:
- -c
- |
set -e
# 环境变量设置
export NCCL_SHM_DISABLE=1
export VLLM_ALLOW_LONG_MAX_MODEL_LEN=1
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export NCCL_IB_DISABLE=0
export NCCL_NET_GDR_LEVEL=2
# 创建日志目录
mkdir -p /log/logs
# 等待模型文件就绪
while [ ! -f "/opt/app/models/config.json" ]; do
echo "等待模型文件就绪..."
sleep 10
done
echo "启动vLLM服务..."
exec python3 -m vllm.entrypoints.openai.api_server \
--model=/opt/app/models \
--served-model-name=Qwen3-235B-A22B-Instruct-2507 \
--port=9997 \
--host=0.0.0.0 \
--trust-remote-code \
--dtype=auto \
--enable-prefix-caching \
--enable-chunked-prefill \
--tensor-parallel-size=8 \
--gpu-memory-utilization=0.85 \
--api-key=${API_KEY} \
--max-model-len=131072 \
--tool-call-parser=hermes \
--enable-auto-tool-choice \
--swap-space=16 \
--disable-log-requests \
--max-num-seqs=128 \
--max-paddings=256 \
> /log/logs/vllm-qwen3-235b.log 2>&1
env:
- name: ACTIVE_OOM_KILLER
value: "0"
- name: LIBCUDA_LOG_LEVEL
value: "0"
- name: GPU_CORE_UTILIZATION_POLICY
value: "disable"
- name: VLLM_WORKER_MULTIPROC_METHOD
value: "spawn"
- name: VLLM_LOGGING_LEVEL
value: "INFO"
- name: MODEL_UID
value: "Qwen3-235B-A22B-Instruct-2507"
- name: MODEL_TYPE
value: "chat"
- name: API_KEY
valueFrom:
secretKeyRef:
key: api-key
name: vllm-qwen3-235b
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- |
echo "正在优雅关闭vLLM服务..."
kill -TERM $(pgrep -f "vllm.entrypoints.openai.api_server") || true
sleep 30
ports:
- containerPort: 9997
name: api-port
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 3
initialDelaySeconds: 600
periodSeconds: 60
successThreshold: 1
timeoutSeconds: 30
readinessProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 3
initialDelaySeconds: 300
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
startupProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 30
initialDelaySeconds: 120
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 10
resources:
requests:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976"
limits:
cpu: "64"
memory: "256Gi"
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976"
volumeMounts:
- mountPath: /opt/app/models
name: share-volume
readOnly: true
- mountPath: /dev/shm
name: cache-volume
- mountPath: /etc/localtime
name: timezone-volume
readOnly: true
- mountPath: /log
name: log-volume
- mountPath: /tmp
name: temp-volume
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
runAsNonRoot: false
fsGroup: 0
terminationGracePeriodSeconds: 180
tolerations:
- effect: NoSchedule
key: role
operator: Equal
value: bigdata
- effect: NoSchedule
key: gpurole
operator: Equal
value: gpu
- effect: NoSchedule
key: model-size
operator: Equal
value: large
volumes:
- name: share-volume
persistentVolumeClaim:
claimName: vllm-qwen3-235b-model-pvc
- name: cache-volume
emptyDir:
medium: Memory
sizeLimit: 256Gi
- name: log-volume
hostPath:
path: /data/logs/vllm-qwen3-235b
type: DirectoryOrCreate
- name: temp-volume
emptyDir:
sizeLimit: 32Gi
- name: timezone-volume
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
type: FileOrCreate
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: 0
volumeClaimTemplates: []
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-qwen3-235b-model-pvc
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Ti
storageClassName: nfs-client
---
apiVersion: v1
kind: Service
metadata:
name: vllm-qwen3-235b
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
type: ClusterIP
ports:
- port: 9997
targetPort: 9997
protocol: TCP
name: api-port
selector:
app: vllm-qwen3-235b
---
apiVersion: v1
kind: Secret
metadata:
name: vllm-qwen3-235b
namespace: ai-serving
type: Opaque
data:
api-key: c2stdmxsbS1xd2VuMy0yMzViLWFwaS1rZXk= # base64编码的API key
S3_URL: <base64-encoded-s3-url>
S3_AK: <base64-encoded-access-key>
S3_SK: <base64-encoded-secret-key>
S3_BUCKET: <base64-encoded-bucket-name>
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-qwen3-235b-model-pvc
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Ti
storageClassName: nfs-client
3.3 存储与模型管理
通过PVC申请共享存储,确保模型文件持久化并可在多个Pod间共享。initContainer负责从S3对象存储下载模型到持久化存储,避免每次Pod重启重复下载。
4. Hami on K8S架构的GPU资源动态分配

4.1 HAMi简介与优势
HAMi(Heterogeneous AI Computing Virtualization Middleware) 是一个专为异构AI计算设备设计的虚拟化中间件,为Kubernetes集群提供强大的GPU资源管理能力。
核心优势
- 🔄 设备虚拟化:为多种异构设备提供虚拟化功能,支持设备共享和资源隔离
- 🚀 智能调度:基于设备拓扑和调度策略实现Pod间的设备共享和优化调度
- 🎯 统一管理:消除不同异构设备间的差异,提供统一管理接口
- 💡 零修改部署:无需对现有应用程序进行任何修改
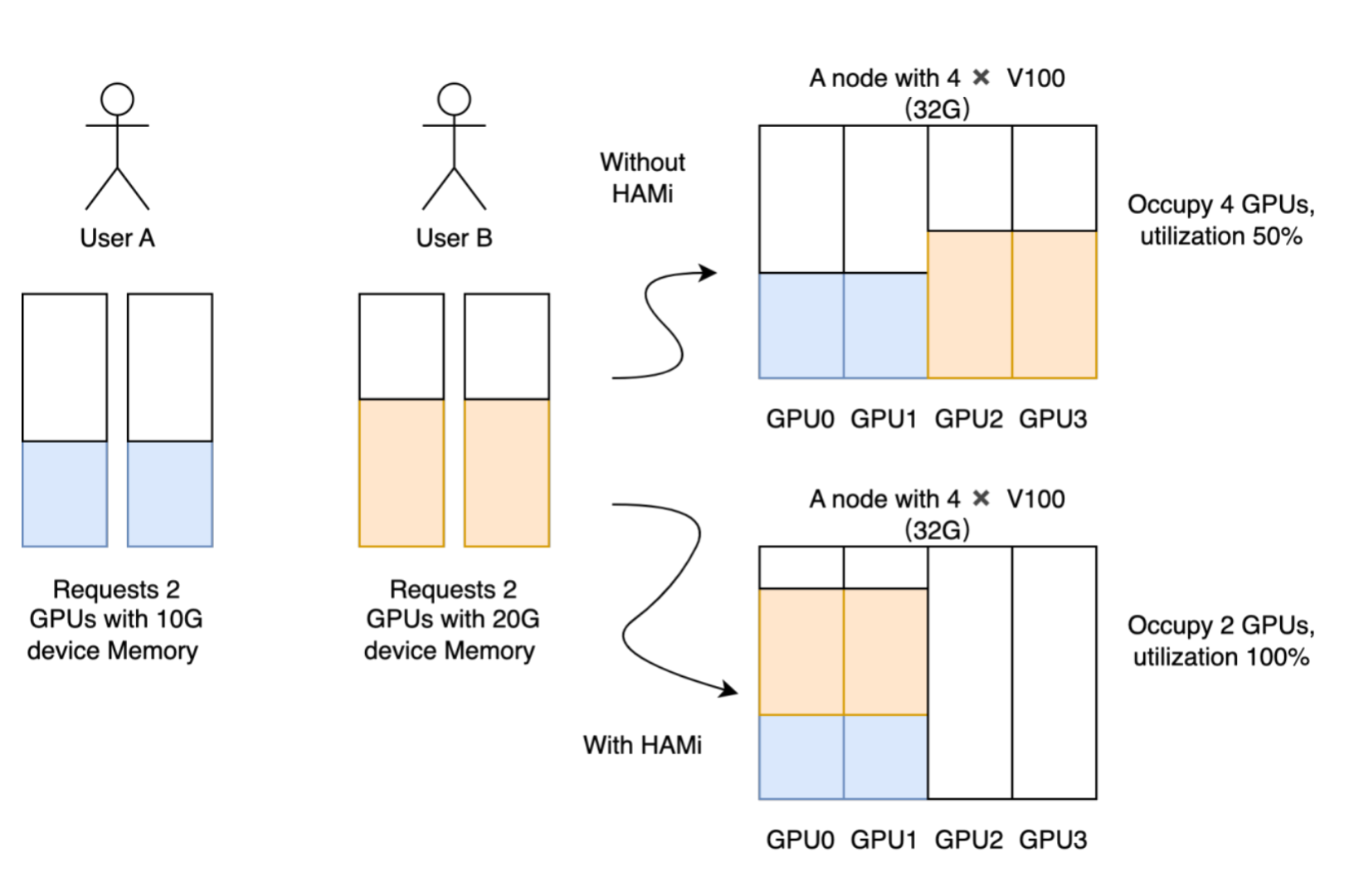
4.2 支持的异构设备
HAMi 2.7.1版本支持的设备类型如下:
| 设备厂商 | 设备类型 | 支持状态 | 备注 |
|---|---|---|---|
| NVIDIA | GPU | ✅ 完整支持 | 需要驱动 >= 440 |
| 寒武纪 | MLU | ✅ 完整支持 | - |
| 海光 | DCU | ✅ 完整支持 | - |
| 天数智芯 | GPU | ✅ 完整支持 | - |
| 摩尔线程 | GPU | ✅ 完整支持 | - |
| 昇腾 | NPU | ✅ 完整支持 | - |
| 沐曦 | GPU | ✅ 完整支持 | - |
📈 支持设备持续更新中,最新支持列表请查看 官方文档
4.3 HAMi安装部署
4.3.1 前置条件检查
在安装HAMi之前,请确保满足以下系统要求:
| 组件类别 | 组件名称 | 版本要求 | 详细说明 |
|---|---|---|---|
| GPU驱动 | NVIDIA驱动 | ≥ 440.x | • GPU计算节点必需安装 • 建议使用最新稳定版本 • 支持CUDA 11.0+ |
| 容器运行时 | nvidia-docker | ≥ 2.0 | • GPU容器化支持组件 • 必须配置为默认运行时 • 与Docker Engine配合使用 |
| 容器编排 | Kubernetes | ≥ 1.18 | • 集群管理平台 • 建议1.20+版本以获得更好的GPU调度支持 • 需启用GPU设备插件 |
| 容器引擎 | 容器运行时 | 兼容版本 | • 支持:containerd/docker/cri-o • 必须配置nvidia为默认运行时 • 确保与K8s版本兼容 |
| 系统库 | glibc | ≥ 2.17 且 < 2.30 | • GNU C标准库 • 版本范围严格限制 • 影响CUDA库兼容性 |
| 操作系统 | Linux内核 | ≥ 3.10 | • 最低内核版本要求 • 建议使用4.x+内核 • 确保驱动兼容性 |
| 包管理 | Helm | ≥ 3.0 | • Kubernetes包管理工具 • 用于部署GPU Operator • 建议使用最新稳定版 |
⚠️ 重要:确保容器运行时的默认运行时配置为nvidia
4.3.2 安装步骤
Step 1: 标记GPU节点
为需要GPU调度的节点添加标签:
kubectl label nodes {nodeid} gpu=on
💡 提示:只有带有
gpu=on标签的节点才能被HAMi调度器管理
Step 2: 添加Helm仓库
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm repo update
Step 3: 部署HAMi
helm install hami hami-charts/hami -n kube-system
Step 4: 验证安装
kubectl get pods -n kube-system | grep vgpu
期望输出:
vgpu-device-plugin-xxx 1/1 Running 0 2m
vgpu-scheduler-xxx 1/1 Running 0 2m
✅ 如果
vgpu-device-plugin和vgpu-schedulerPod都处于Running状态,则安装成功
4.4 自定义配置
HAMi支持通过修改 values.yaml 文件进行个性化配置。
4.4.1 资源名称自定义
# NVIDIA GPU 参数配置
resourceName: "nvidia.com/gpu" # GPU设备资源名
resourceMem: "nvidia.com/gpumem" # GPU内存资源名
resourceMemPercentage: "nvidia.com/gpumem-percentage" # GPU内存百分比
resourceCores: "nvidia.com/gpucores" # GPU核心数
resourcePriority: "nvidia.com/priority" # GPU优先级
4.4.2 企业级自定义示例
# 自定义为公司标识
resourceName: "company.com/gpu"
resourceMem: "company.com/gpumem"
resourceMemPercentage: "company.com/gpumem-percentage"
resourceCores: "company.com/gpucores"
📚 更多配置选项:详细配置参数请参考 官方配置文档
4.5 使用注意事项
在使用HAMi过程中,请注意以下重要事项:
| ⚠️ 重要提醒 |
|---|
| 设备暴露风险:如果使用NVIDIA镜像的设备插件时不请求虚拟GPU,机器上的所有GPU可能会在容器内暴露 |
| A100 MIG限制:目前A100 MIG仅支持 “none” 和 “mixed” 模式 |
| 调度约束:带有 “nodeName” 字段的任务目前无法调度,请使用 “nodeSelector” 代替 |
| 版本一致性:确保Kubernetes scheduler版本与hami-scheduler版本一致 |
4.6 最佳实践建议
📋 部署前检查
- 验证所有前置条件
- 确认GPU节点标签正确
- 检查版本兼容性
🔧 配置优化
- 根据企业需求自定义资源名称
- 合理配置资源限制
- 监控资源使用情况
🛡️ 安全考虑
- 避免不必要的GPU设备暴露
- 合理设置资源配额
- 定期更新组件版本
5. 服务访问与可扩展性演示
5.1 服务暴露与访问
通过Service和Ingress暴露vLLM服务:
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: ai-serving
spec:
selector:
app: vllm-qwen3-235b
ports:
- port: 9997
targetPort: 9997
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vllm-ingress
namespace: ai-serving
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: vllm.ai-serving.company.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vllm-service
port:
number: 9997
5.2 API调用示例
cURL 请求示例 非流式响应示例:
curl -X POST "http://vllm.ai-serving.company.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "qwen3-235b",
"messages": [
{
"role": "user",
"content": "解释机器学习的基本概念"
}
],
"max_tokens": 1000,
"temperature": 0.7,
"stream": false,
"enable_reasoning": true
}'
流式响应示例:
curl -X POST "http://vllm.ai-serving.company.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "qwen3-235b",
"messages": [
{
"role": "user",
"content": "解释机器学习的基本概念"
}
],
"max_tokens": 1000,
"temperature": 0.7,
"stream": true,
"enable_reasoning": false
}' \
--no-buffer
5.3 可扩展性演示
水平扩缩容演示:
# 手动扩展副本数应对流量高峰
kubectl scale sts vllm-qwen3-235b --replicas=2 -n ai-serving
监控与指标:
- GPU利用率监控自动触发扩容
- 请求延迟超过阈值时增加副本
- 基于Prometheus指标的自定义扩缩容策略
总结
Kubernetes上部署vLLM为大规模语言模型服务提供了生产级的解决方案。通过容器化封装、资源动态调度、存储持久化和自动扩缩容等特性,实现了高效、可靠且可扩展的AI模型服务架构。Qwen3-235B等大模型在该架构下能够充分发挥性能优势,为企业级AI应用提供强有力的支撑。
这种架构不仅适用于当前的大模型服务,也为未来更大规模的模型和服务需求提供了可扩展的基础设施保障,是构建现代化AI服务平台的最佳实践。
实用工具
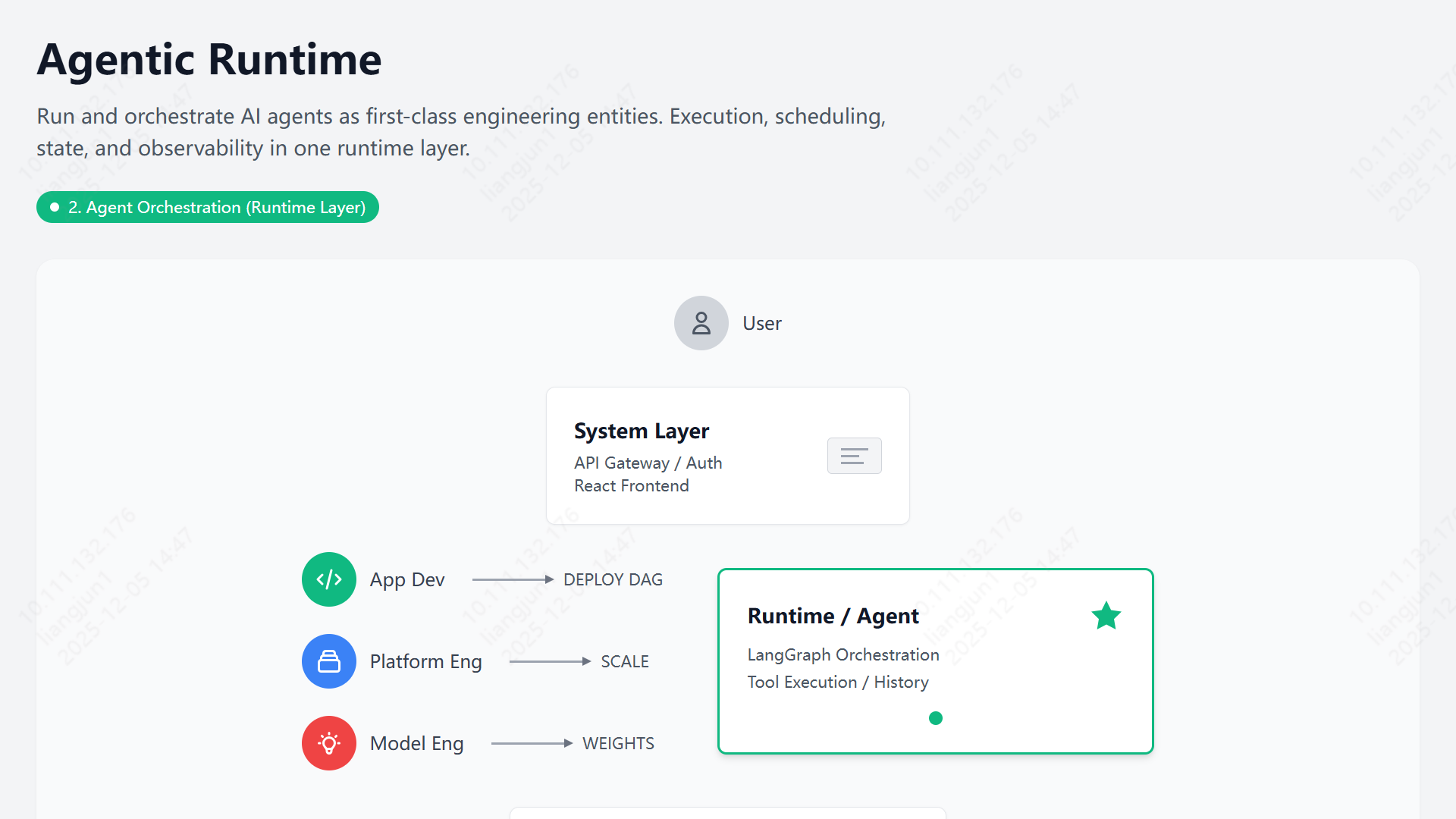
AI 赋能:如何用 Claude 瞬间生成专业级系统架构图
告别繁琐的绘图工具,利用 Claude/Gemini 与特定提示词,一键生成美观、专业的系统架构 SVG/HTML 图表,让技术汇报与架构设计事半功倍。
在数字化转型加速的今天,系统设计与架构能力已成为技术工作者的核心竞争力。一张清晰、美观的架构图,往往胜过千言万语,能让复杂的系统逻辑一目了然。
然而,传统的绘图方式往往让人望而却步:
- 门槛高:需要熟练掌握 Visio, OmniGraffle, ProcessOn 等专业工具。
- 耗时久:调整对齐、配色、连线占据了大量时间,修改成本极高。
- 风格乱:难以统一格式,从文本思维到图形表达存在巨大的转换鸿沟。
在多次尝试 WPS AI、豆包、通义千问等工具后,我发现生成的图表在专业度和美观度上仍有欠缺。直到我发现了 Claude (配合特定 Prompt) 的强大能力——它可以一键生成代码级的 SVG 或 HTML 架构图,只需简单截图,即可完美嵌入 PPT,极大地提升了技术交流的效率。
本文将分享这一高效方法,助你轻松搞定“高大上”的架构图。
🎨 效果预览
在深入方法之前,先来看看 AI 生成的实际效果。这些图表均由 Claude/Gemini 3 配合提示词直接生成 SVG/HTML 渲染而成。
1. 宣传汇报类
适用于产品介绍、方案推广,风格现代简洁。

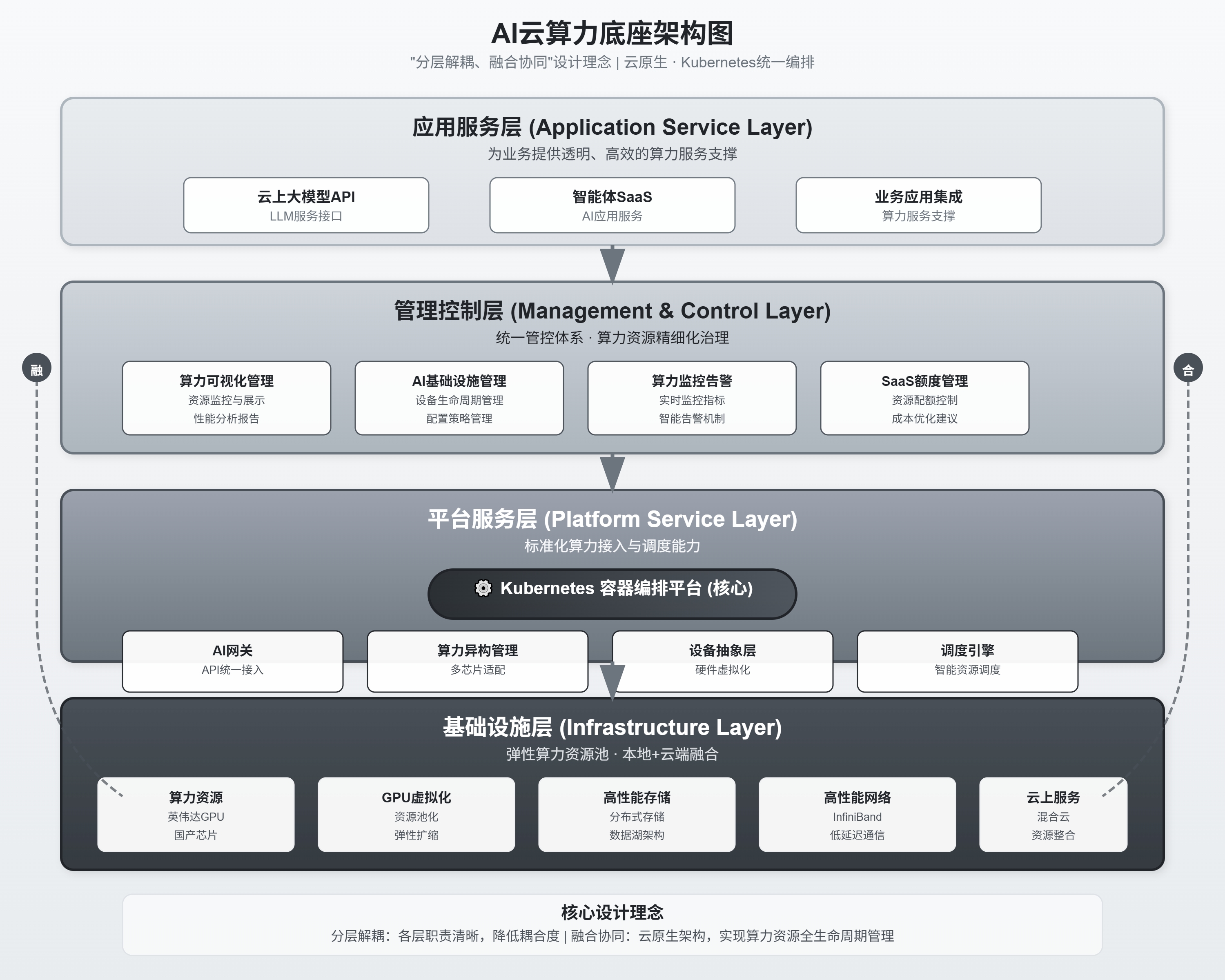
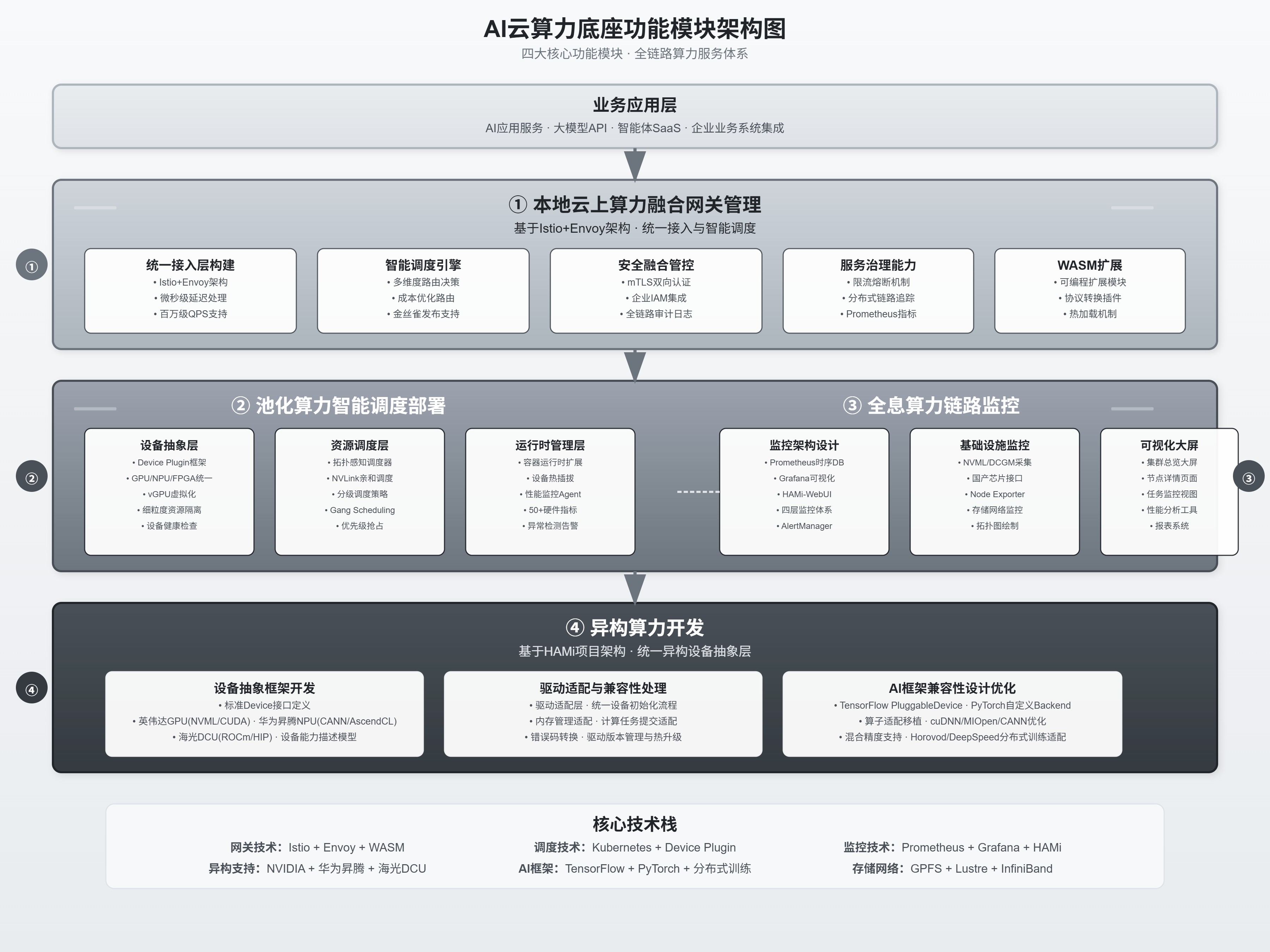
2. 架构设计类
适用于技术评审、系统蓝图,层次分明,逻辑严密。
3. 业务流程类
适用于泳道图、状态流转,清晰直观。
🛠️ 准备工作
要实现上述效果,你需要准备好以下环境:
方案 A:在线直接生成 (推荐)
如果你能顺畅访问 Google 服务,直接使用 Google AI Studio 是最便捷的选择。
方案 B:客户端 + API
对于国内网络环境,推荐使用本地客户端配合 API 服务:
- 客户端:下载安装 Cherry Studio (支持多模型管理的优秀客户端)。
- API 服务:你需要一个支持 Claude 3.5 Sonnet 或 Gemini 1.5 Pro 的 API。
- 推荐渠道:DMX API (使用邀请码
bDx3可获赠额度) - 备选渠道:OpenRouter 等其他聚合服务商。
- 推荐渠道:DMX API (使用邀请码
🚀 实战演练:4步生成架构图
以 Cherry Studio + Claude 4 Sonnet 为例,生成一张架构图仅需四步:
- 准备文档:梳理好你的系统描述、功能列表或技术栈说明。
- 输入指令:将下方的“万能提示词”填入对话框。
- 获取代码:AI 会输出一段 SVG 或 HTML 代码。
- 渲染保存:Cherry Studio 会自动渲染预览,直接截图或保存即可。
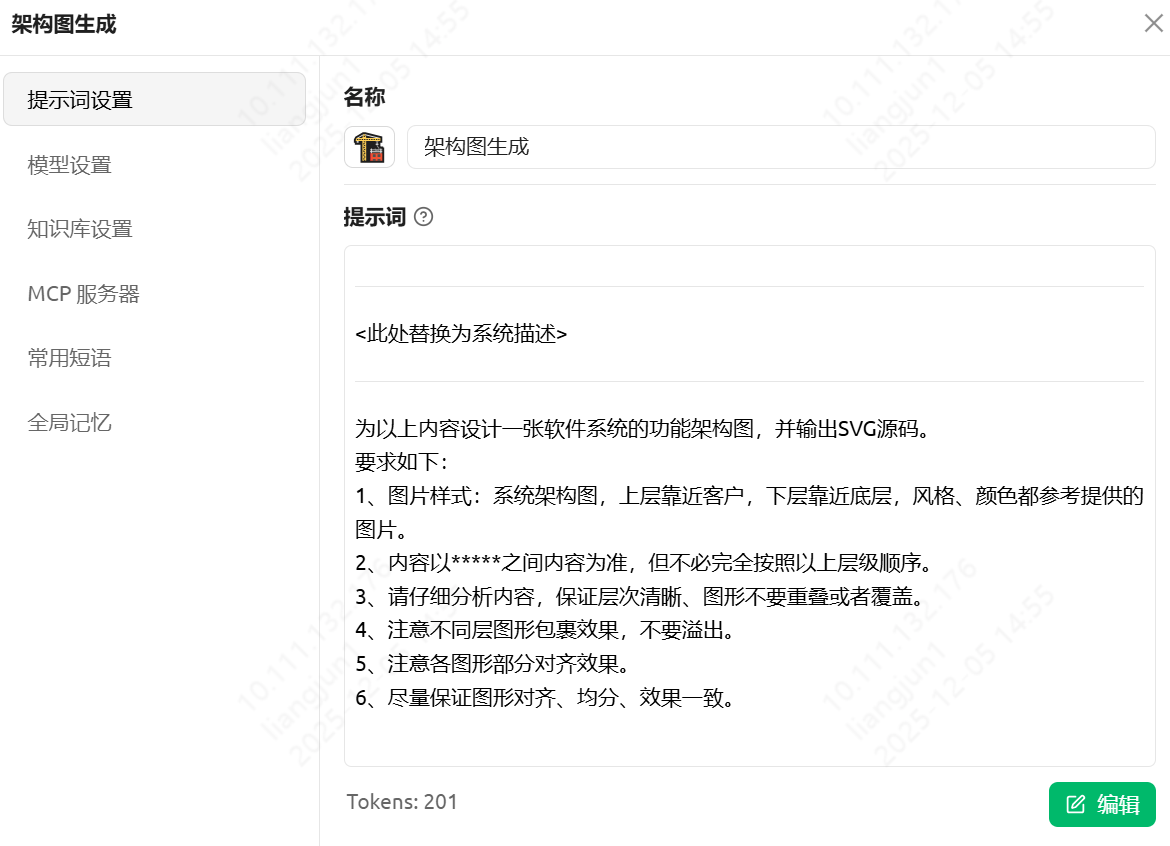
核心提示词 (Prompt)
复制以下 Prompt,将 <此处替换为系统描述> 替换为你实际的业务内容:
*****
<此处替换为系统描述>
*****
为以上内容设计一张软件系统的功能架构图,并输出 SVG 源码。
**设计要求:**
1. **视觉风格**:采用专业的系统架构图样式。
* 布局:逻辑分层,上层靠近用户/业务,下层靠近底层/数据。
* 配色:参考现代科技风格(如蓝、白、灰主色调),配色和谐专业。
2. **内容准则**:
* 内容严格以 ***** 之间的描述为准。
* 层级顺序可根据架构逻辑进行微调,不必完全死板照搬。
3. **布局细节**:
* 层次清晰,模块之间严禁重叠或遮挡。
* 容器包裹效果要自然,子模块不要溢出父容器。
* 严格对齐(左对齐、居中对齐),模块间距均匀。
4. **最终输出**:仅输出一段完整的、可直接渲染的 SVG 代码。
输入示例
Cherry Studio示例:
最终产出
经过 AI 的即时运算,你将获得类似下图的精美架构图。
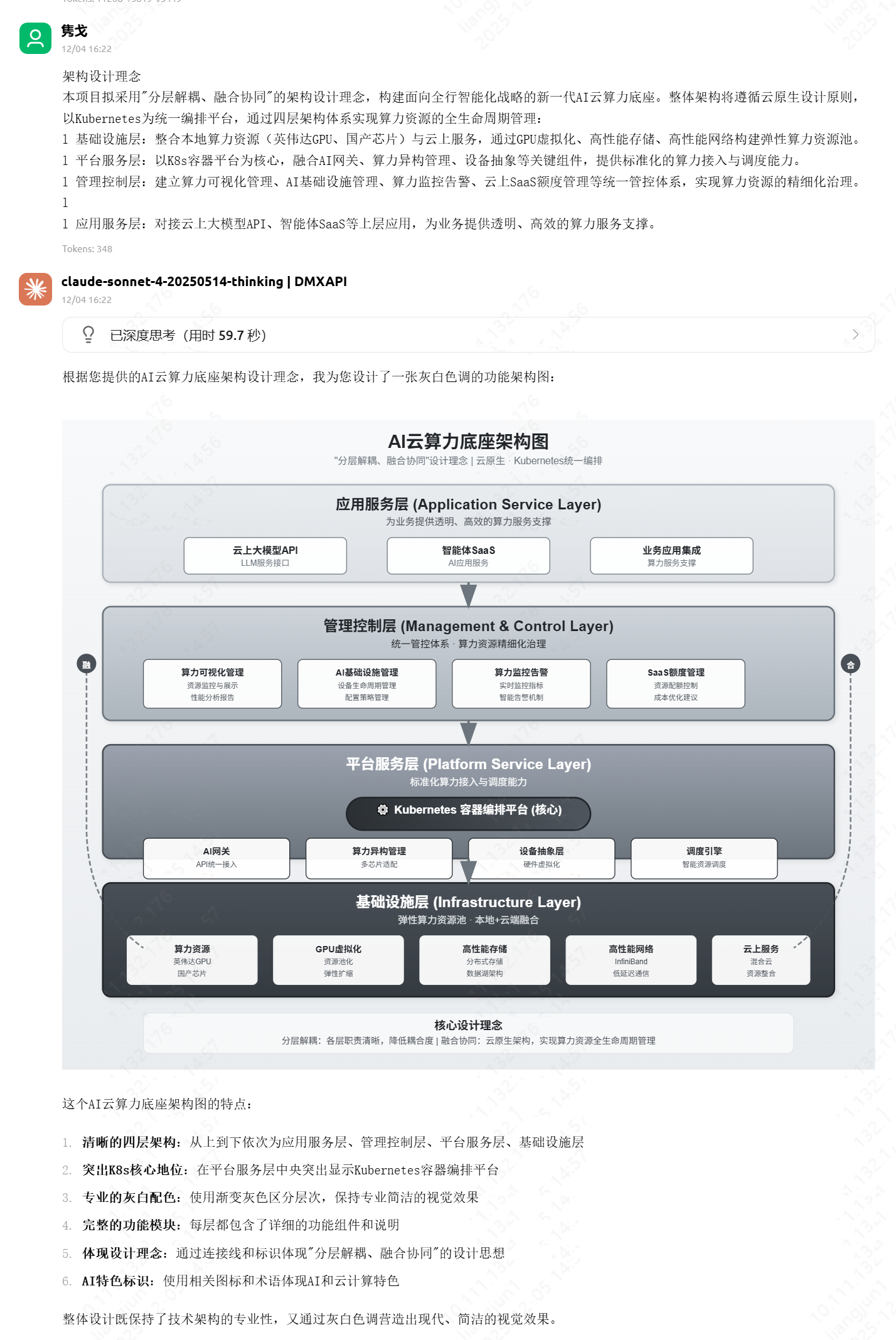
如果你用Cherry Studio可以直接复制/下载图片用于 PPT 汇报绝对吸睛!

💡 总结
AI 正在重塑我们的工作流。通过将“绘图”这一繁琐过程转化为“描述”这一认知过程,我们不仅节省了时间,更能将精力集中在系统设计本身的逻辑与价值上。下次做 PPT 时,不妨试试这个方法。
Ghelper 使用流程指导
Ghelper 是一个专门为科研、外贸、开发人员服务的上网加速工具,本文介绍其安装和使用流程。
Ghelper 是一个浏览器插件,专门为科研、外贸、跨境电商、海淘人员、开发人员服务的上网加速工具,Chrome 内核浏览器专用!
它可以解决 Chrome 扩展无法自动更新的问题,同时可以访问 Google 搜索、Gmail 邮箱等谷歌产品。它可以帮助用户提高跨境访问网站的速度,突破地区限制,提高工作和学习的效率。
如何安装
支持 Chrome / Edge / 360 等 Chromium 内核浏览器。
方法一:手动安装(推荐)
- 下载插件:访问 Ghelper 官网,下载 CRX package。下载后是一个 zip 文件,请解压缩取得
.crx文件。
- 打开扩展程序管理页面:
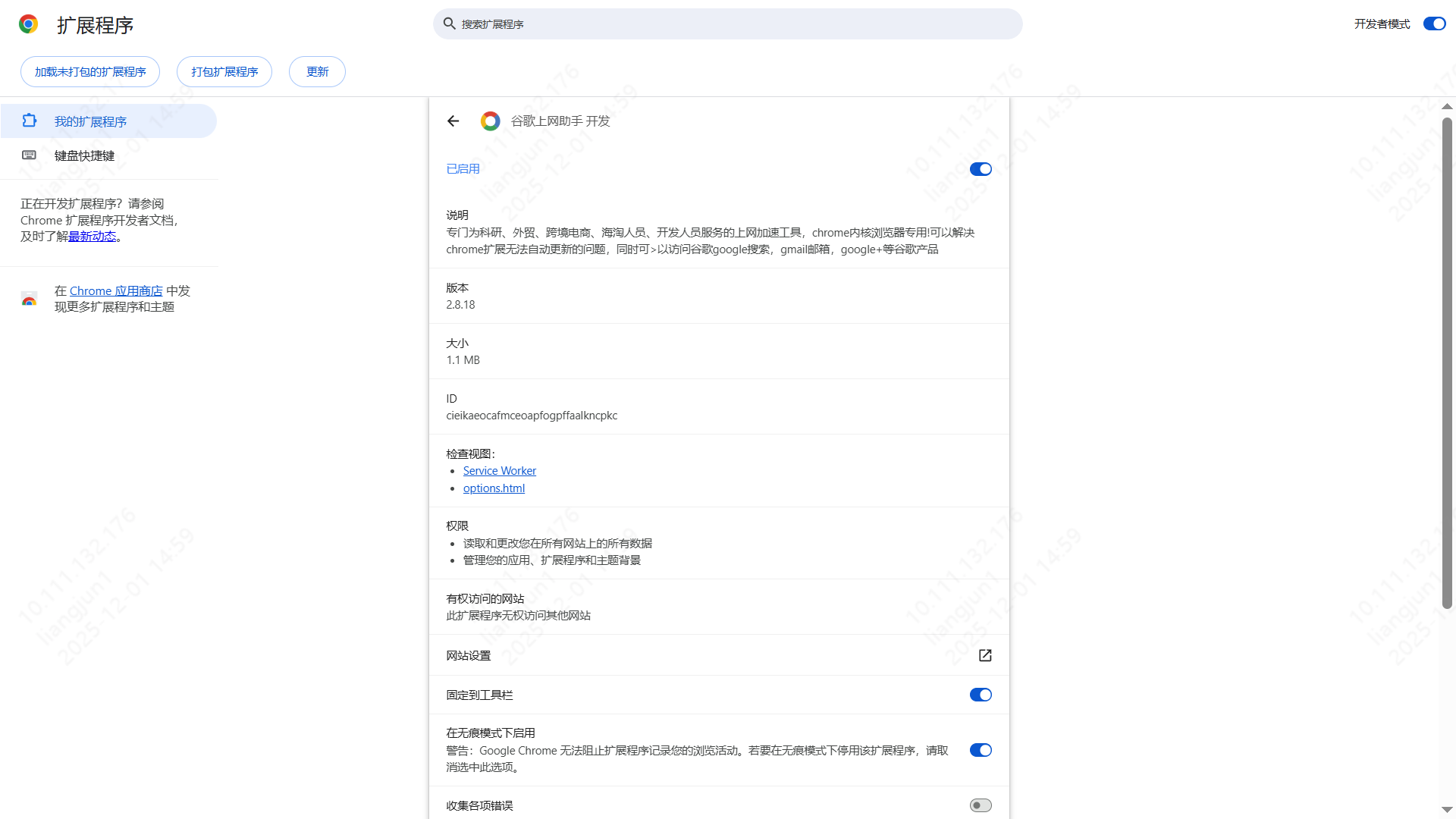
- 打开浏览器,点击地址栏最右边的三个点(菜单),选择 “更多工具” -> “扩展程序”。
- 或者直接在地址栏输入
chrome://extensions/并回车。
- 开启开发者模式:确保页面右上角的 Developer mode (开发者模式) 处于打开状态。
- 拖拽安装:将第一步解压得到的
.crx文件拖放到浏览器的扩展程序页面上,浏览器会提示是否添加扩展,点击“添加扩展程序”即可安装完成。
方法二:在线安装(Edge 浏览器)
如果是 Edge 浏览器,可以直接访问 Microsoft Edge Addons 商店:
点击页面右上角的 “获取” 按钮即可自动安装完成。
使用说明
- 安装完成后,点击浏览器右上角的插件图标。
- 点击 “登录” 按钮进行账号登录(如果没有账号请先注册)。
- 登录成功后,可以看到插件主界面,以及当前 VIP 的有效期。
(请将登录界面截图命名为 login_interface.png 并放在本文件同级目录下)
提示:请确保您的 VIP 状态有效以享受加速服务。