[i18n] print_printable_section [i18n] print_click_to_print.
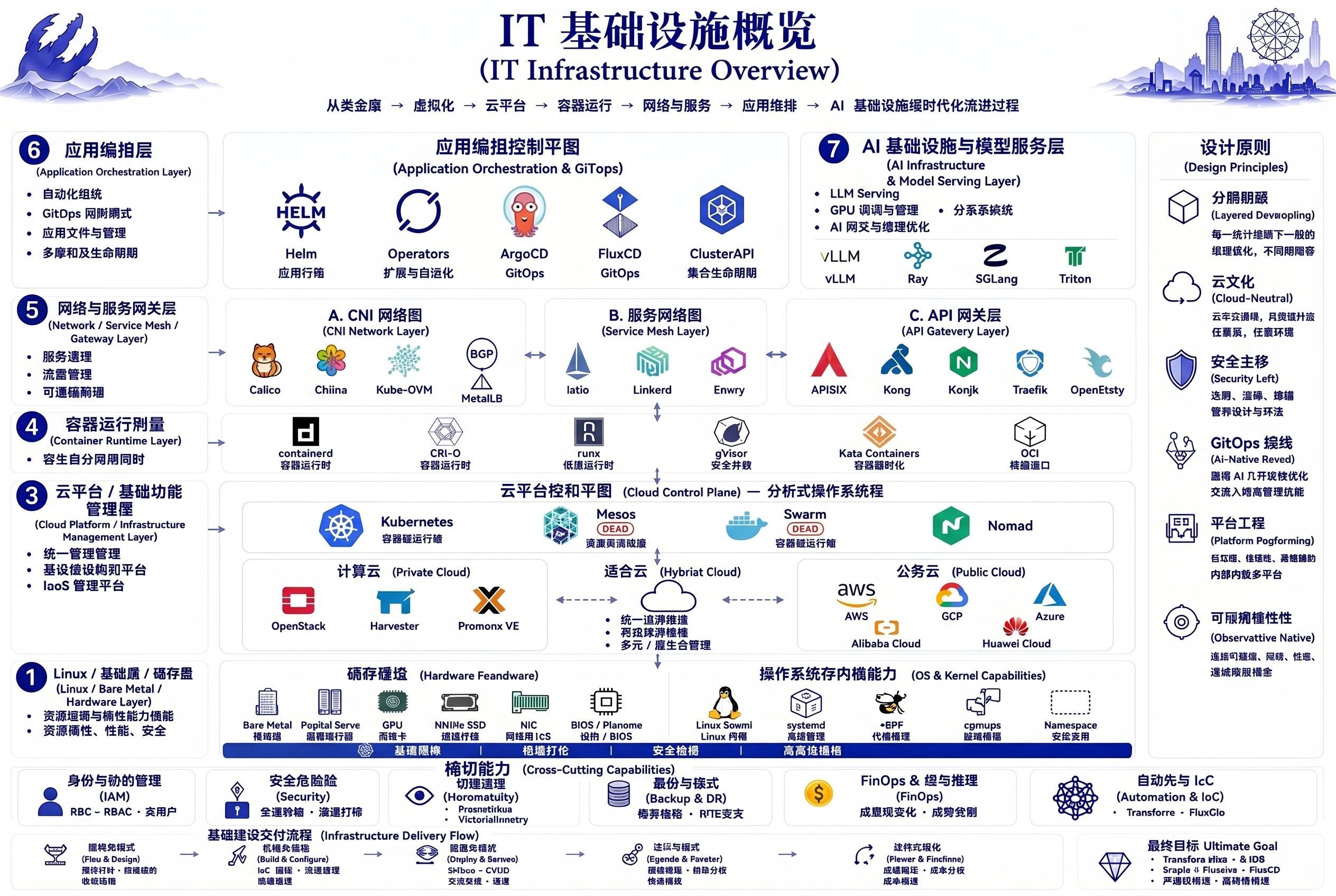
技术分享
- Claude Code 源码深度拆解:ULTRAPLAN & Agent Swarm——分布式 AI 编排
- Claude Code 源码深度拆解:Fork Subagent & Prompt Cache——把成本降到 10% 的工程智慧
- KAIROS 常驻助手:Claude Code 源码中隐藏的主动系统
- 韬定律 vs 摩尔定律:从"缩尺寸"到"压时间"
- Claude Code 源码深度拆解:工具系统架构从 40+ 工具到权限分级管控
- Claude Code 源码深度拆解:Multi-Agent 的实现机制
- 本周 GitHub 热门开源项目速览:AI Agent 工具链、端侧 TTS 与代码理解
- Agent Skill 框架正在吃掉软件开发
- 新网银行"智擎AI+"战略升级:10类数字员工、77个智能助手如何落地?
- Markdown → HTML:AI 输出正在从"文档"进化成"界面"
- Kubernetes GPU 虚拟化实战:HAMi DRA 模式完整指南
- 云原生 Agent 托管的高效范式:Agent Harness Infra 体系化设计
- 从零到收:用AI搭建工具站,靠广告自动化变现
- Web Infra vs AI Infra:K8s 擅长的事正在被重新定义
- 从0到1:用AI Agent架构搭建AIOps平台的设计思路
- AIOps探索:分享10个运维领域的Agent Skills
- OpenClaw 与 Hermes 通用 Agent 架构全面对比解析
- 微众银行的AI原生银行战略:800+智能体背后,基础设施才是隐形战场
- 让AI帮你写技术博客:我摸索出的最佳实践
- 2026 AI 自由意志 开启?
- 国产GPU技术现状与应用市场调研
- Kubernetes上部署vLLM
Claude Code 源码深度拆解:ULTRAPLAN & Agent Swarm——分布式 AI 编排
当单 Agent 不够用时,Anthropic 怎么用工程手段把规划、执行、审批、团队协作拆成一套分布式系统。四个关键词:ULTRAPLAN、Agent Swarm、Remote CCR、浏览器审批流。
前几篇发出去之后,收到最多的一个问题就是:“单 Agent 既然有上下文爆炸、串行阻塞这么多问题,Claude Code 有没有更大规模的方案?”
有。而且不止一套。
这期我们聊四个关键词——ULTRAPLAN、Agent Swarm、Remote CCR、浏览器审批流。它们是 Claude Code 从"单兵作战"进化到"分布式编排"的四大支柱。
一、ULTRAPLAN:把"想"和"做"彻底拆开
为什么需要它?
AI 编程最常见的一种死法是什么?
还没搞清楚要做什么,就开始改代码了。
你说了句"帮我把认证迁移到 OAuth",Claude 二话不说开始改文件。改到一半发现理解错了,回滚重来。改了三个文件之后发现漏了一个依赖,再回滚。来回几轮,token 烧了几万,时间花了几个小时——还不如别干。
这个失败模式的根因是:“想"和"做"没分开。
ULTRAPLAN 的思路很简单——把这两个阶段分别放在两个完全不同的环境里执行:
⚡ 执行阶段 → 本地执行(你的终端)
架构设计:为什么规划可以在云端?
Anthropic 工程师 Thariq 的解释非常到位:“实现代码需要本地环境和交互性,但规划阶段完全可以放到云端,因为它本质上就是读代码和理解意图。”
这个拆分的背后有一个更深的洞察:规划是"尴尬并行”(embarrassingly parallelizable)的。它不涉及文件系统,不涉及编译错误,纯粹是阅读和推理。而实现是天然串行的,需要本地环境一步步来。
ULTRAPLAN 云端规划流程图
浏览器审批流:不只是"看一眼再执行"
ULTRAPLAN 最惊艳的设计不是技术架构,而是交互体验。
传统 /plan 模式在终端里看方案,文本是线性的,你只能上下滚动。如果方案涉及五六个文件、十几个步骤,在终端里阅读体验极差。
网页端就不一样了:
- 侧边栏导航:跳转到任意章节
- 代码高亮:结构化展示代码片段
- 可编辑文本:选中任意文本给 Claude 留评论,形成审阅→反馈→修改的闭环
- 两种执行方式:「Run on web」在云端直接执行 / 「Approve & teleport to terminal」传回本地
审批通过后回到终端,Claude 会问你怎么执行:
- Implement here:把方案注入当前对话,就地开干
- Start new session:清掉当前上下文,只带方案开新会话
- Cancel:先不执行,方案存着回头再说
和 /plan 的区别:不止是换了个 UI
| 维度 | /plan | /ultraplan |
|---|---|---|
| 方案展示 | 终端文本(线性) | 网页端(结构化 + 导航) |
| 可编辑性 | 不可编辑 | 选中文本直接留评论 |
| 审批流程 | 无 | 审阅→评论→修改→批准闭环 |
| 执行方式 | 仅本地 | 云端 or 本地二选一 |
| 远程执行 | ❌ | 手机审阅→本地执行 |
二、Agent Swarm:带协议的团队协作
从 Coordinator 到 Swarm——思维的跃迁
第一篇文章里,我们拆了 Coordinator 模式——协调者派 Worker,Worker 干活,结果回传。这是中心化调度。
Swarm 不一样。
Swarm 是去中心化团队协议。每个队友都是一个独立的 Agent,有自己的终端面板,队友之间可以直接发消息,团队有自己的配置文件(TeamFile),有颜色编码,有独立的 worktree。
中心化 vs 去中心化的核心区别:
Swarm vs Coordinator 对比图
三种 Backend:tmux / iTerm2 / In-Process
Swarm 的队友执行有三种后端,检测优先级是:
1. 在 tmux 里 → 直接用 tmux(即使在 iTerm2 中也优先)
2. 在 iTerm2 + 有 it2 CLI → 用 iTerm2 原生分屏
(如果之前选了 preferTmux,跳过)
3. 在 iTerm2 + 无 it2 → 提示安装,继续往下
4. tmux 可用 → 创建外部 tmux session
5. 都没有 → 抛错,提示安装 tmux
In-Process 模式由 isInProcessEnabled() 决定:
teammateMode = 'in-process'→ 始终 in-processteammateMode = 'tmux'→ 始终用 pane backendteammateMode = 'auto'(默认)→ 非交互 session 强制 in-process;在 tmux/iTerm2 里用 pane;否则 in-process
pane 模式下,每个队友都有独立终端面板,你可以看着每个 Agent 实时在干什么。in-process 模式零进程开销,但失去独立面板的体验。
TeamFile:团队的配置文件中心
Swarm 不像 Coordinator 那样每个 Worker 从零开始。它有 TeamFile——一个 JSON 文件定义整个团队的配置:
type TeamFile = {
name: string
leadAgentId: string
leadSessionId?: string
teamAllowedPaths?: TeamAllowedPath[]
members: Array<{
agentId: string
name: string
model?: string // 每个队友可以选不同模型
color?: string // 颜色编码,视觉区分
planModeRequired?: boolean
tmuxPaneId: string
cwd: string
worktreePath?: string
subscriptions: string[]
backendType?: BackendType
isActive?: boolean
mode?: PermissionMode
}>
}
注意几个精妙的设计:
- 按角色配置模型——Leader 用 Opus 做决策,Worker 用 Sonnet 做执行
- 颜色编码——每个队友可以指定颜色,终端面板一眼识别
- teamAllowedPaths——团队共享的允许路径,队友启动时自动同步权限
权限冒泡:集中审批,分布执行
Swarm 里队友需要权限确认时,不是自己弹对话框。它通过 Leader Permission Bridge 把权限请求"冒泡"到 Leader:
In-Process 队友需要权限时:
1. 通过 bridge 获取 leader 的 setToolUseConfirmQueue
2. 把权限请求推到 leader 的队列
3. leader 审批后,结果回流到队友
Pane 模式队友需要权限时:
1. 写入 pending request 到 mailbox
2. leader 轮询 mailbox,回复审批意见
3. 队友读取回复后继续执行
双路径设计的源码:
// 注册 leader 的审批队列
export function registerLeaderToolUseConfirmQueue(
setter: SetToolUseConfirmQueueFn
): void { registeredSetter = setter }
// 队友获取 leader 的审批队列
export function getLeaderToolUseConfirmQueue(): SetToolUseConfirmQueueFn | null {
return registeredSetter
}
in-process 走 UI bridge(实时),pane 模式下走 mailbox(异步)。最终目标一致:审批集中在 Leader 这一侧,队友只管执行。
团队记忆同步:Scratchpad 共享白板
Worker 之间没有直接通信通道,但它们需要一个共享空间来交换中间结果。方案就是 Scratchpad 目录:
用于跨 Worker 的持久化知识存续——无论是结构化文件、中间分析结果还是临时笔记。
Agent Summary 是另一个精巧的设计——每 30 秒 fork 一次 Worker 的对话,让 LLM 用 3-5 个词描述当前动作。用户可以看到"Worker 1: Investigating auth.ts… / Worker 2: Running test suite…":
const SUMMARY_INTERVAL_MS = 30_000
function buildSummaryPrompt(previousSummary: string | null): string {
return `Describe your most recent action in 3-5 words using
present tense (-ing). Name the file or function, not the branch.
Do not use tools.`
}
摘要 fork 共享 Worker 的 prompt cache——工具定义保留在请求中(cache key 一致),但通过 canUseTool 回调全部 deny。模型看得到工具但不能用。
队友的 Prompt 增补
每个队友的系统 prompt 会额外追加一段,告诉它通信规则:
“You are running as an agent in a team. To communicate with anyone on your team: use the SendMessage tool. Just writing a response in text is not visible to others on your team.”
这个设计向模型明确了一个关键约束:你的文本输出别人看不到,必须通过工具通信。 简单但致命——如果不加这一句,模型会天真地以为它输出的文字队友能看见,然后全部失联。
三、Remote CCR:远程责任链与控制反转
架构原理:本地执行 + 远程操控
2026 年 2 月,Anthropic 向 Claude Max 用户推送了 Remote Control 功能。
它的架构非常特别:不是传统的"远程桌面"(把你的桌面传给手机),而是本地执行 + 远程操控的混合架构。
Remote CCR 架构图——本地执行 + 远程操控
关键设计要点:
- ✅ 所有计算和文件操作依然是本地执行
- ✅ 手机仅作为远程操控界面
- ✅ 代码不离本地,兼顾隐私与效率
- ✅ 上下文、自定义 Skill、MCP 服务器全部保留
CCR:Chain of Responsibility(责任链)
Remote Control 的底层安全模型是一套完整的 Chain of Responsibility:
CCR 安全模型——多层责任链防护
这个设计回答了安全问题:“怎么保证我的手机控制电脑是安全的?”
答案是把控制流建模成责任链——每个环节都有有限权限、有限时效、有限作用域,任何一个环节被攻破都不会导致全系统沦陷。
# 方式一:从 claude 会话内启动
/remote-control # 或 /rc
# 方式二:命令行直接启动
claude remote-control
终端生成 QR 码 → 手机扫码 → 连接建立 → 开始远程操控。
连接中断时,系统会在 10 分钟内持续尝试重连,超时会话自动失效。
与 ULTRAPLAN 的组合:完整的分布闭环
把 ULTRAPLAN 和 Remote CCR 连起来看,就形成了一套完整的分布式工作流:
ULTRAPLAN + Remote CCR 完整分布闭环
四、架构对比:什么时候用什么模式
现在把本系列文章涉及的所有模式放在一起对比:
| 维度 | Coordinator | Swarm | Fork | ULTRAPLAN | Remote CCR |
|---|---|---|---|---|---|
| 拓扑 | 中心化调度 | 弱中心化团队 | 父子进程 | 云+本地混合 | 本地+远程 |
| 执行环境 | 同进程异步 | tmux/iTerm2 或 in-process | 同进程异步 | 云端规划+本地执行 | 本地执行+远程操控 |
| 通信方式 | XML task-notification | SendMessage + mailbox | 无横向通信 | 网页审批链 | HTTPS + 流式传输 |
| 上下文共享 | 完全隔离 | 基本隔离 | 完全继承 | 隔离(云端 vs 本地) | 完整保留 |
| 典型场景 | 复杂多步骤工程 | 长期并行团队 | 快速并行探索 | 需人类审阅的大型任务 | 移动端远程开发 |
| 互斥关系 | 与 Fork 互斥 | 独立 | 与 Coord 互斥 | 独立 | 独立 |
选型决策树
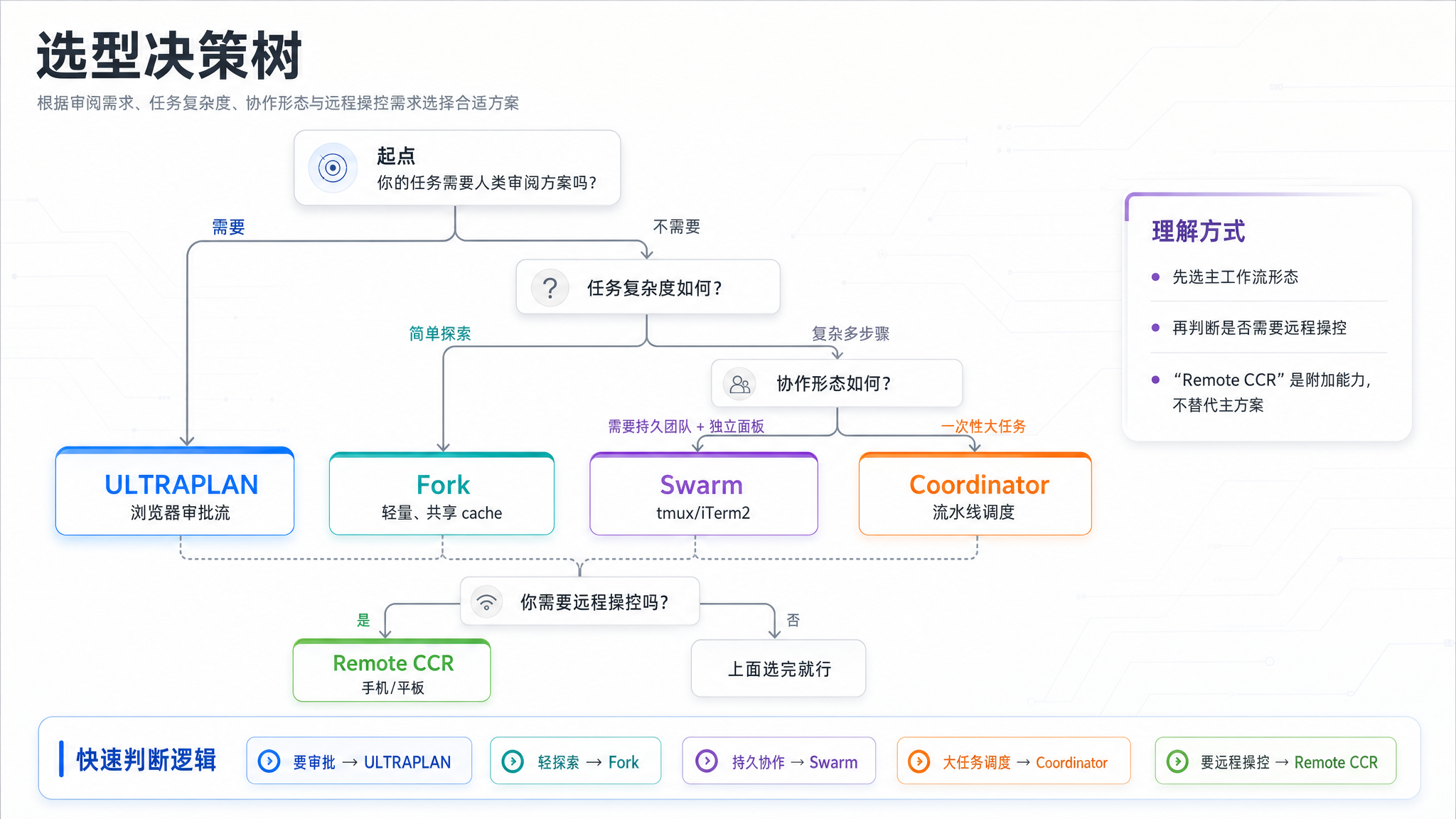
分布式 AI 编排选型决策树
成本分析
| 模式 | Token 成本 | 通信开销 | 启动成本 |
|---|---|---|---|
| Fork | ⭐ 最低 | 无 | 极低(复用 cache) |
| Coordinator | ⭐⭐⭐ 中等 | Worker 独立 prompt | 中等 |
| Swarm (pane) | ⭐⭐⭐⭐ 高 | 全量独立会话 | 高 |
| Swarm (in-process) | ⭐⭐⭐ 中等 | 共享部分上下文 | 中等 |
| ULTRAPLAN | ⭐⭐ 低(规划云端) | 仅最终方案传本地 | 中等 |
| Remote CCR | ⭐(终端 token 不变) | 仅 UI 渲染 | 极低(接续会话) |
从成本角度看,Fork 是最经济的多 Agent 方案(复用父级 prompt cache),而 Swarm 的全栈独立会话是最贵的。
五、源码工程启示
启示 1:规划是尴尬并行的
ULTRAPLAN 把规划扔到云端执行,背后是一个重要的工程洞察:不涉及文件系统的纯推理任务,天然适合并行化和远程执行。 这是设计任何 Agent 系统时的"杠杆点"——找到那些可以从主流程拆出来的、无副作用的推理步骤,把它们放到更便宜/更快/更方便的环境去跑。
启示 2:团队需要显式协议
Swarm 不是简单的"多个 Agent 跑在一起"。它有 TeamFile、有 mailbox、有 SendMessage、有颜色编码。隐式的进程间通信(共享内存、全局变量)在多 Agent 系统中会引发混乱——必须把交互协议显式建模。
// Swarm 显式建模的团队协议:
// 1. TeamFile → 团队的宪法
// 2. mailbox → 消息总线
// 3. SendMessage → 通信原语
// 4. Leader Permission Bridge → 控制面
// 5. Scratchpad → 共享存储
启示 3:权限冒泡比分布式 ACL 更务实
Swarm 的权限设计选择了一条务实的路——不搞复杂的分布式访问控制列表(ACL),而是把审批权向上冒泡到 Leader。这让每一个队友的实现都极其简单:它不需要处理权限决策,只需要把请求往上抛。
启示 4:字节一致性就是钱
Fork 和 Agent Summary 都在追求同一个目标:让子请求的 API 前缀字节级一致,最大化 prompt cache 命中。 这不是优化,这是架构。设计时就考虑缓存友好,能让你的 token 账单直接打五折。
启示 5:安全以架构为前提
Remote CCR 的纯出站连接模型是一个很好的安全架构示例——它通过改变通信方向(从入站到出站),从根本上消除了端口暴露的风险。安全不应该是后期加固的,而应该是架构设计时就内生的。
结语:单 Agent 时代已经结束了
前面几篇文章,从 Multi-Agent 到 Tool System,再到 Fork Subagent & Prompt Cache 和 ULTRAPLAN & Agent Swarm,Claude Code 的源码给了一个清晰的信号:
单 Agent 满足不了真实的工程场景。下一级复杂度必然是分布式编排。
Anthropic 的可贵之处在于,它不是用一个"万能多 Agent 架构"解决所有问题,而是根据不同场景设计了三种不同的多 Agent 模式 + 一套云端规划系统 + 一套远程控制机制。每种方案在上下文共享策略、通信开销、启动成本、审批流程上做了不同的取舍。
不要问"我要不要加多 Agent",要问"我的任务需要哪种编排模式"。
最后想说关于 Claude Code 的源码深度拆解课题结束了,后面我会计划把 Claude Code 的源码拿出来教大家如何本地部署,大家可以关注后期的动向。
声明:Claude Code 的源码不是专有 TypeScript 源代码的副本,它是一个对 Claude Code 行为进行洁净室(clean-room)Rust 重实现的项目。
Claude Code 源码深度拆解:Fork Subagent & Prompt Cache——把成本降到 10% 的工程智慧
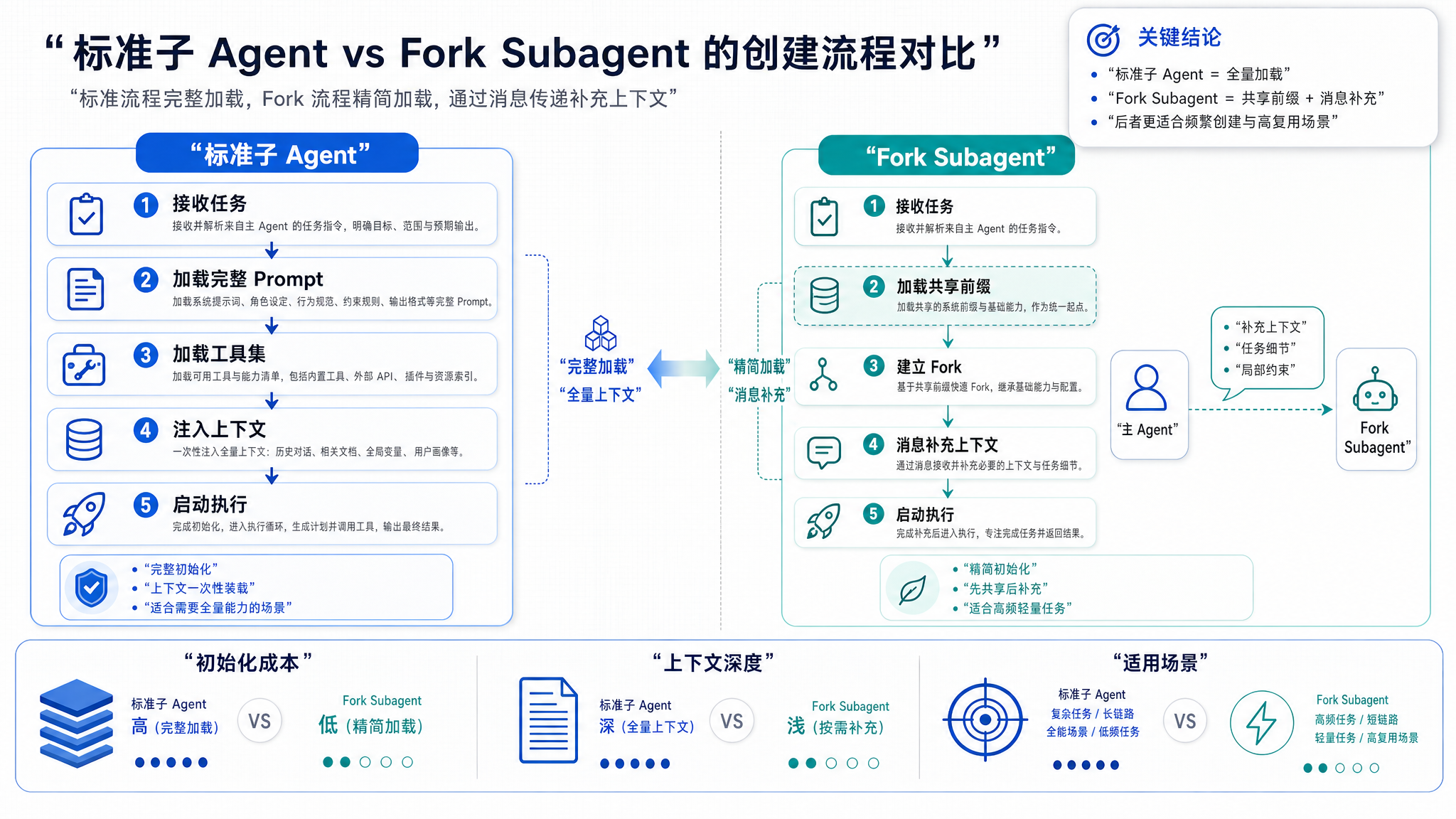
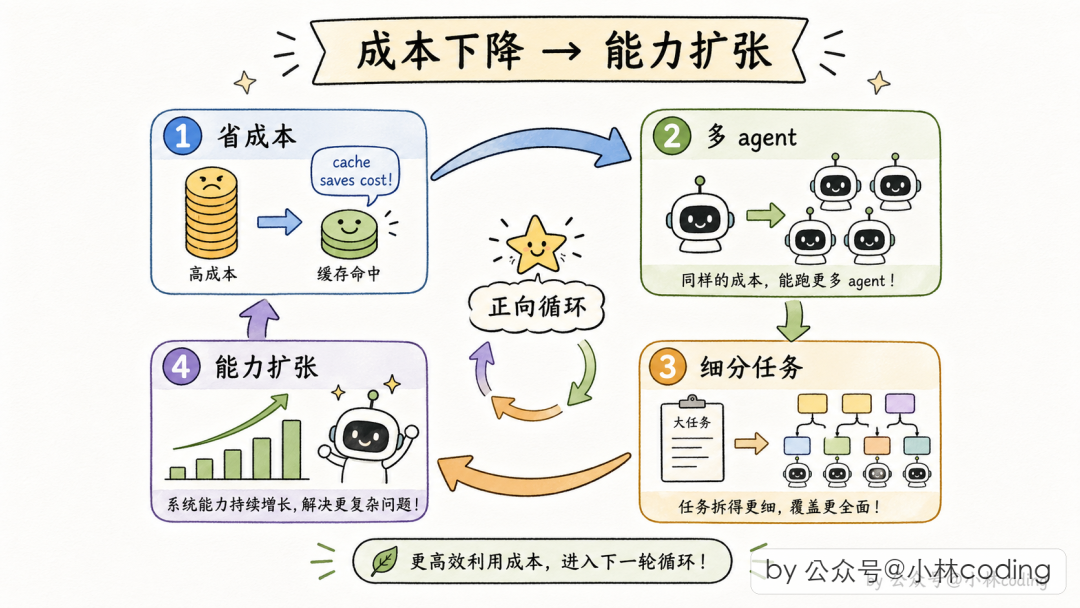
Claude Code 的源码堪称 AI Agent 工程的教科书。 如果你读过系列上一篇,应该记得 Fork Subagent 的独特设计:它不复制父 Agent 的上下文,而是创建一个"影子"会话,通过消息传递来通信。
当时我还留了一个尾巴:Fork Subagent 为什么在 filterToolsForAgent 的权限过滤中始终被标为 isBuiltIn = false?
答案不在权限体系里。答案在成本里。
一、背景:Multi-Agent 的隐形成本
当 Agent 从 1 个变成 N 个
在上一篇中我们提到,Claude Code 支持三种 Agent 通信模式:
- 直接子 Agent:
spawnSubagent()→ 独立的会话,完整上下文 - Fork Subagent:
spawnForkSubagent()→ 轻量影子会话 - Agent Team:
AgentTeam.create()→ 多 Agent 协作群
每种模式看起来都是"多了一个 Agent 干活",但成本模型完全不同。
一个标准 Claude Code Agent 调用 API 时,每次请求的 payload 包含:
系统提示词(~2000 tokens)
工具 Schema(~4000 tokens,40+ 个工具)
对话历史(不断增长的上下文)
用户最新输入
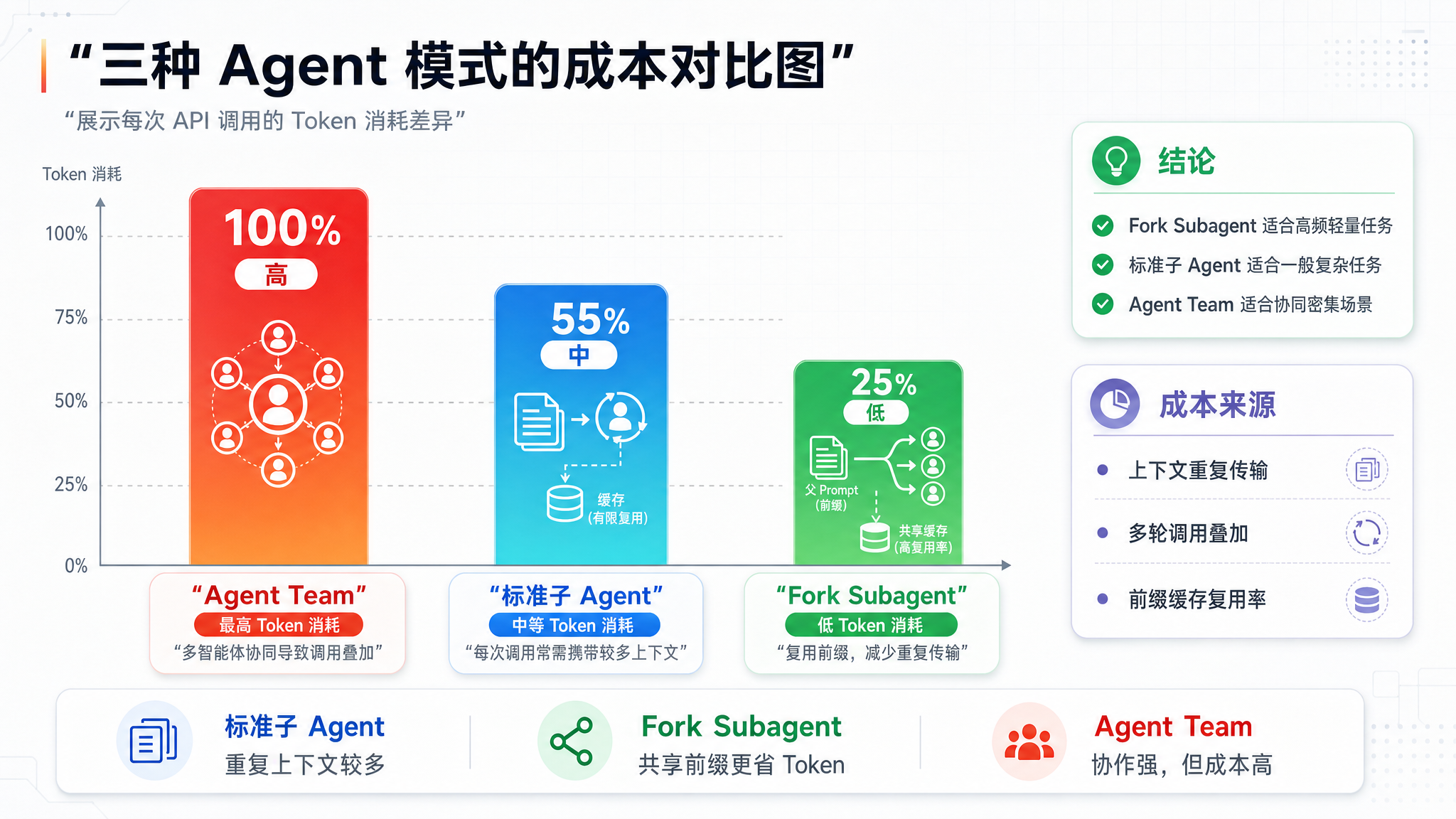
如果用标准子 Agent,每次调用都要带上整套系统提示词和工具 Schema。N 个 Agent 并行工作,API 成本不是 N 倍——是 N 倍的每次调用。
成本问题的工程本质
对 Anthropic 来说,成本不是"每月账单多少钱"的问题——它是产品能不能交付的问题。
Claude Code 的商业模式是"用户按量付费"。如果每个 Multi-Agent 操作都产生数倍的 API 调用成本,用户会看到账单翻倍,然后放弃使用。
这不是一个可以后期优化的性能问题——它是一个必须从架构层面解决的基础设计约束。
二、Fork Subagent 的成本模型
轻量会话的设计哲学
标准子 Agent 的创建流程:
// AgentTool/agentToolUtils.ts(架构示意)
async function spawnSubagent(context: Context, task: string): Promise<AgentSession> {
// 1. 创建完整会话 - 带系统提示词、工具列表、历史
const session = await createSession({
systemPrompt: FULL_SYSTEM_PROMPT, // 完整系统提示词
tools: getAllBaseTools(), // 40+ 工具
parentContext: context, // 复制父上下文
});
// 2. 分配模型推理资源
await session.prepare();
return session;
}
Fork Subagent 的创建流程:
// AgentTool/agentToolUtils.ts(架构示意)
async function spawnForkSubagent(context: Context, task: string): Promise<AgentSession> {
// 1. 创建影子会话 - 几乎是空的
const session = await createSession({
systemPrompt: '', // ← 空字符串!关键就在这里
tools: [], // ← 空工具列表
parentContext: null, // ← 不复制父上下文
});
// 2. 通过消息传递逐步提供上下文
await session.sendTask(task);
return session;
}
核心差异:Fork Subagent 几乎"什么也不带"就启动了。
不复制上下文,减少内存占用。不带工具列表,减少 Schema 传输。最关键的是:系统提示词返回空字符串。

空字符串的代价
你可能会想:“返回空字符串有什么了不起?省点 token 而已。”
不对。
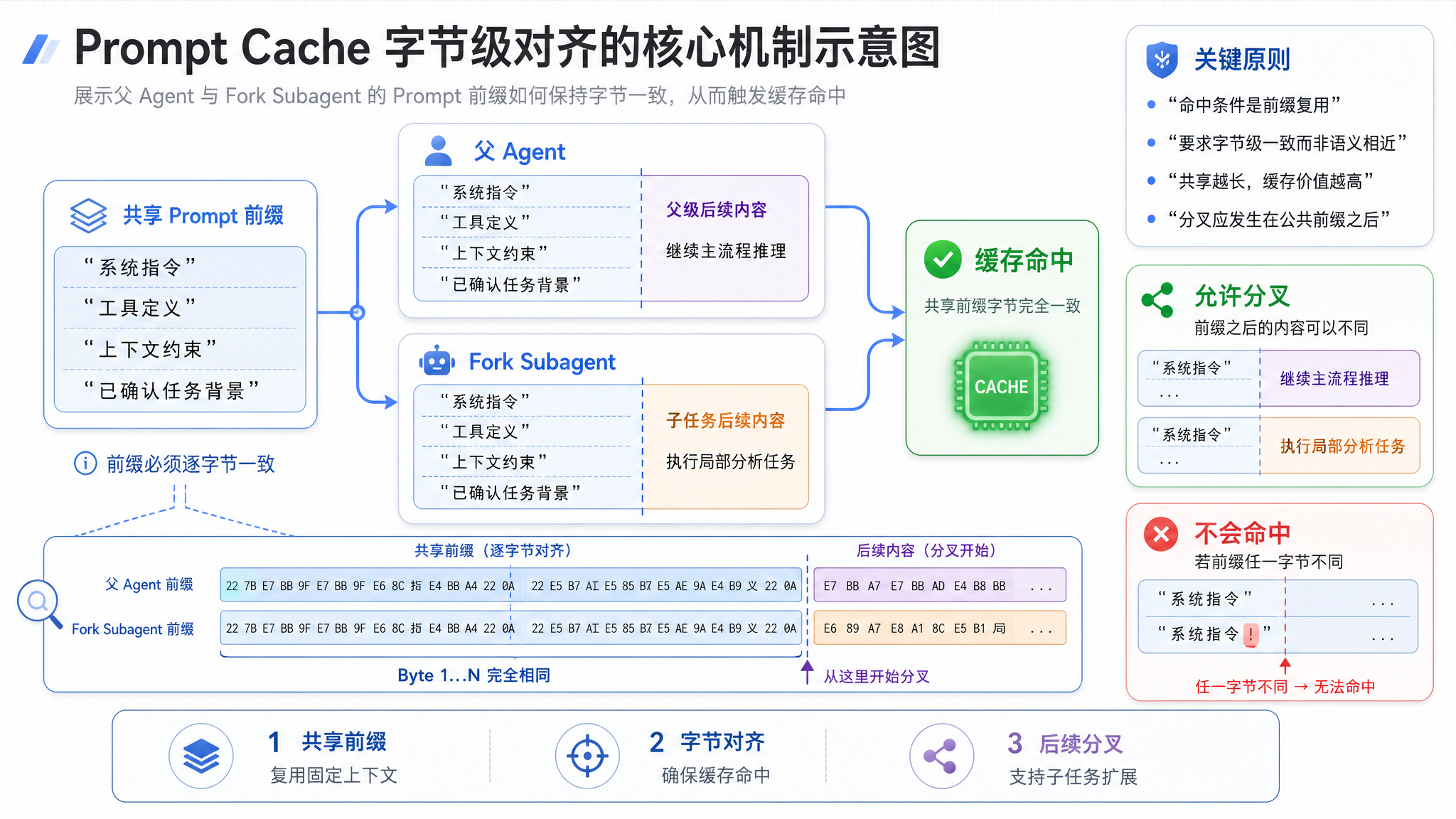
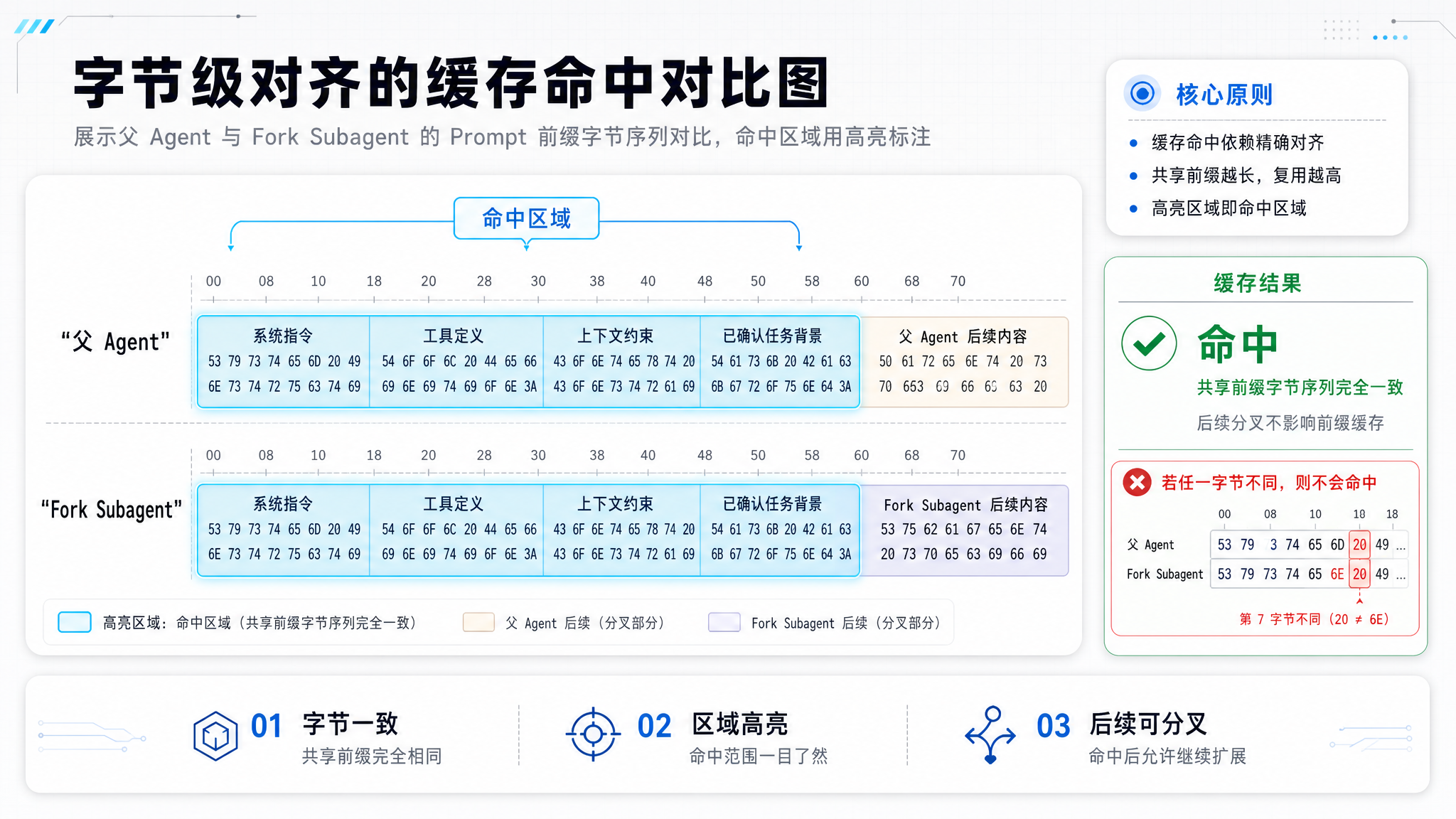
当 getSystemPrompt() 返回空字符串时,发生了一个更微妙的事情:父 Agent 和 Fork Subagent 的 API 请求前缀,变成了字节完全一致的。
三、字节级对齐:Prompt Cache 的终极形态
Prompt Cache 的工作原理
Anthropic 的 API 支持 Prompt Caching——如果连续请求的 Prompt 前缀相同,缓存命中后可以跳过计算,只处理新增部分。
假设一次 API 请求的 Prompt 是这样的:
[系统提示词 2000t] [工具 Schema 4000t] [对话历史 6000t] [用户输入 200t]
↑
缓存边界
缓存命中的条件是:前缀的字节序列完全一致。 只要系统提示词、工具 Schema 和对话历史中任何一个字符发生变化,缓存就失效了。
为什么标准子 Agent 无法命中缓存
父 Agent 和标准子 Agent 的请求对比:
父 Agent 的请求:
[SYS_PROMPT_PARENT] [TOOL_SCHEMA] [HISTORY_A] [输入 X]
↑
缓存边界,命中率高
标准子 Agent 的请求:
[SYS_PROMPT_CHILD] [TOOL_SCHEMA] [HISTORY_B] [输入 Y]
↑
缓存从 SYS_PROMPT_CHILD 开始就不同了,完全无法命中
标准子 Agent 的系统提示词和父 Agent 不同(因为角色的描述不同),对话历史也不同。前缀在第一个 token 就产生了差异。 这意味着缓存完全无效,每次调用都要重新计算。
Fork Subagent 如何实现对齐
Fork Subagent 的策略是:既然历史的差异无法避免,至少让前缀的第一个字节保持一致。
父 Agent 的请求:
[SYS_PROMPT] [TOOL_SCHEMA] [HISTORY_A] [输入 X]
Fork Subagent 的请求:
[SYS_PROMPT] [TOOL_SCHEMA] [HISTORY_B] [输入 Y]
↑ ↑
两个请求的前缀完全相同!缓存命中!
Fork Subagent 的 getSystemPrompt() 返回空字符串,但它使用的系统提示词与父 Agent 完全一致——因为父 Agent 的 Prompt 前缀已经被缓存了。空字符串意味着"沿用父 Agent 的上下文",而不是"不设系统提示词"。
缓存命中的量化收益
让我们算一笔账:
| 场景 | 每次请求的 token 消耗 | 缓存命中 | 有效计算量 |
|---|---|---|---|
| 父 Agent 独立请求 | 12,000 tokens | 缓存命中(首次) | 12,000 tokens |
| 标准子 Agent | 12,000 tokens | 不命中 | 12,000 tokens |
| Fork Subagent | 12,000 tokens | 缓存命中(共享前缀) | ~200 tokens |
在一个典型的 Multi-Agent 工作流中:
- 父 Agent 初始化:12,000 tokens(完全不缓存)
- Fork Subagent 发起第 1 次调用:共享缓存,新增仅 ~200 tokens
- Fork Subagent 发起第 2 次调用:继续共享缓存
- 第 N 次调用:缓存持续命中
实际上 Fork Subagent 后续调用的 API 成本,大约只有标准子 Agent 的 1/60 到 1/10。

四、Fork Subagent 的工具权限为什么被限制
回到上一篇中那个没有回答的问题:为什么 Fork Subagent 在 filterToolsForAgent 中始终是 isBuiltIn = false?
// AgentTool/agentToolUtils.ts(源码示意)
function filterToolsForAgent({
tools, isBuiltIn, isAsync, permissionMode
}): Tools[] {
return tools.filter(tool => {
// Fork Subagent 的 isBuiltIn 始终为 false
// → 自动进入 CUSTOM_AGENT_DISALLOWED_TOOLS 过滤
if (!isBuiltIn && CUSTOM_AGENT_DISALLOWED_TOOLS.has(tool.name)) {
return false;
}
return true;
});
}
答案现在清晰了:
Fork Subagent 没有被分配工具列表,因为它的设计目标不是"执行操作",而是"处理信息"。
Fork Subagent 的典型工作流程是:
- 父亲给它一个任务描述(“检查这个 PR 的状态”)
- Fork 子 Agent 用共享缓存低成本运行
- 它返回分析结果给父 Agent
- 父 Agent 根据需要执行具体操作
Fork Subagent 是"大脑",不是"手"。 它思考、分析、报告,但实际操作由父 Agent 执行。这样就避免了 Fork Subagent 需要加载 40+ 工具 Schema 的成本——因为它根本用不到。
五、这个设计背后的三条工程原则
原则 1:成本是架构约束,不是性能优化
大多数团队把成本优化放在"性能优化"阶段:功能做完了,看看能不能省点钱。
Anthropic 的做法是相反的:成本在设计阶段就是硬约束。 Fork Subagent 的轻量设计不是"后面考虑优化"的产物——它从一开始就是为了解决成本问题而设计的。
如果先设计功能再优化成本,最终的架构一定不如在约束条件下生长出来的架构优雅。
原则 2:单个决策点可以撬动百倍收益
getSystemPrompt() 返回空字符串,这个改动看起来只有一行代码。
但这一行代码撬动了:
- Prompt Cache 缓存命中(-90% 成本)
- 工具列表无需加载(-30% token)
- Fork 子 Agent 轻量启动(-50% 延迟)
原则 3:系统的成本模型决定了系统的架构形态
Fork Subagent 不是"标准子 Agent 的简化版"。它们是两种完全不同的架构模式:
- 标准子 Agent:独立的能力单元,成本 = N × 标准成本
- Fork Subagent:共享缓存的轻量分析器,成本 = 固定成本 + 可忽略的增量成本
当你的成本模型不同,你的架构决策也会不同。Fork Subagent 的存在,让 “Multi-Agent = 成本翻倍” 变成了 “Multi-Agent ≈ 几乎不增加成本”。
这就是为什么 Claude Code 可以在一个普通 4 核服务器上运行几十个并行子 Agent——不是因为计算能力强,而是因为计算成本被设计压到了最低。
当其他团队在思考"如何降低 API 调用次数"时,Anthropic 在想"如何让每次调用几乎零成本"。当其他团队在"优化系统提示词长度"时,Anthropic 在想"如何让系统提示词不成为缓存障碍"。
返回空字符串,不是省略——是精确的省略。
在系列的 Multi-Agent 篇中,我们看到的是功能层面对"多 Agent 协作"的回答。今天这篇揭示了这些功能背后的成本引擎——没有这个引擎,所有功能都是空中楼阁。
而 Fork Subagent + Prompt Cache 的字节级对齐策略,就是那个让 Multi-Agent 从"极客玩具"变成"可用产品"的工程奇迹。
下一篇预告: Claude Code 源码深度拆解:ULTRAPLAN & Agent Swarm 分布式 AI 编排。远程 CCR 会话 + Opus 4.6 做 30 分钟深度规划 + 浏览器审批流。Agent Teams 支持 tmux/iTerm2 多进程、团队记忆同步、颜色编码。当单 Agent 不够用时——这套方案回答了"下一级复杂度怎么走"
KAIROS 常驻助手:Claude Code 源码中隐藏的主动系统
如果你用过 Claude Code,你会发现它有个很独特的体验:有时你正看着终端发呆,它突然弹出一行提示——“我在检查 CI 状态……发现了 3 个失败的测试”。你没有发任何指令,没有敲任何命令,它自己决定要做点什么。
这不是幻觉。这是 Claude Code 源码中一个隐藏至深的系统——KAIROS 常驻助手。
在拆解完 Multi-Agent 机制(#1)和 工具系统架构(#2)之后,今天这一篇终于触及 Claude Code 源码中最大胆的设计:一个不依赖用户输入、自我驱动的常驻 AI 助手。
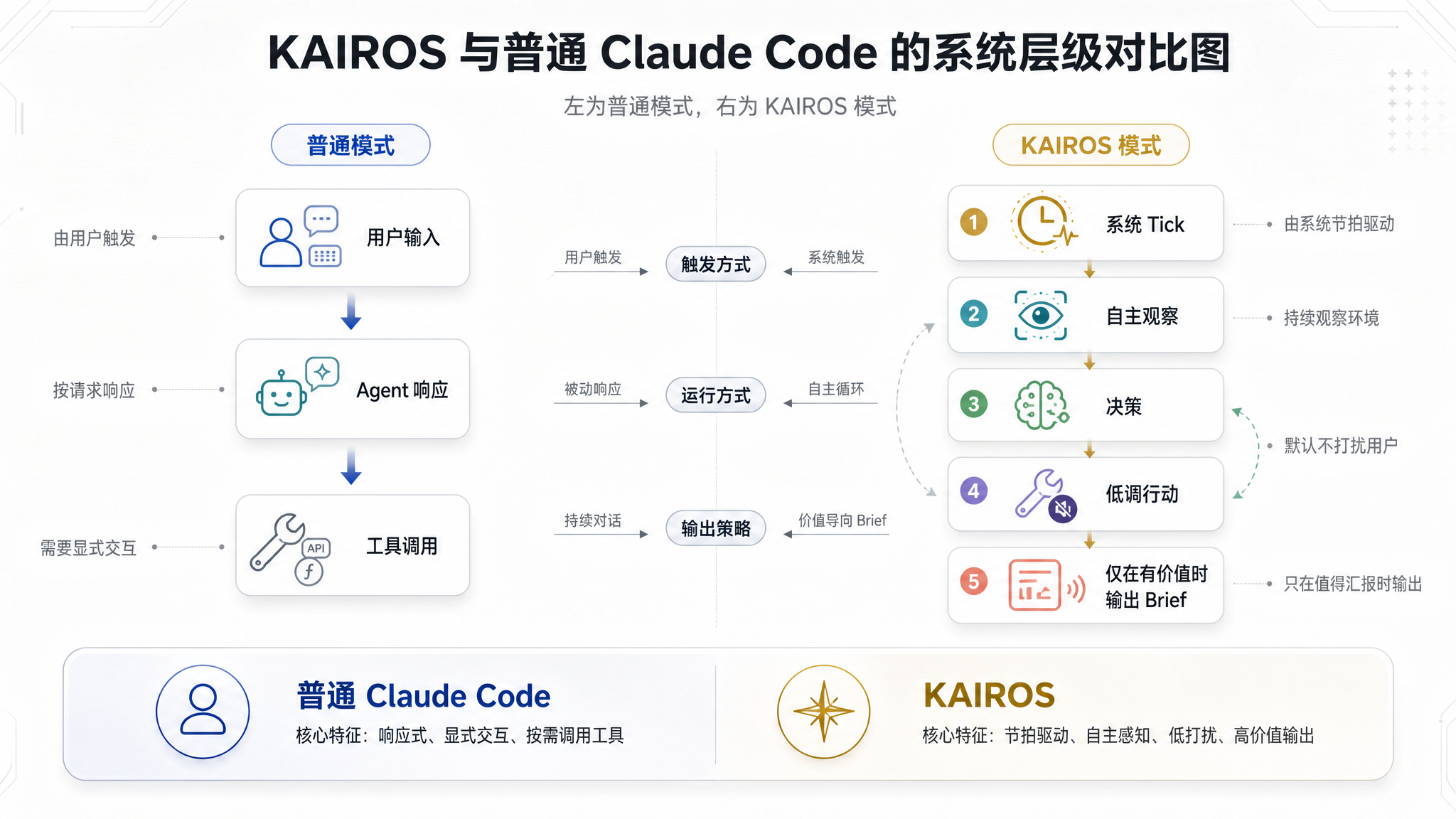
它不是一般的 Agent 轮询模式。它不等待用户说"去做 X",而是主动观察环境、做出判断、低调行动、只在有价值时才出声。KAIROS 不是一个实验性功能——它是 Claude Code 源码中由编译开关保护、从系统提示词到工具集完全独立的一套平行系统。
一、背景:为什么 AI 需要"常驻"而不是"一次性召唤"
从"命令-响应"到"观察-行动"
Claude Code 的常规模式本质上是一套"命令-响应"系统:用户输入一句话,Agent 思考、调用工具、给结果——然后等待下一个输入。
这套模式在任何聊天驱动的 AI 产品中都够用。但在终端里,你有一层额外的环境:文件在变化、日志在写入、CI 在运行、Git 分支在切换。这些变化不会主动通知你——你得自己去翻。
KAIROS 的出发点很朴素:AI 不应该等你问才知道该做什么,它应该现在就坐在你旁边看着。
这种隐喻不是修辞,而是精确的设计取舍。它不是"用户的分身"——它是"坐在旁边看的人"。这意味着:
- 它有自己的观察视角,不替代用户决策
- 它只在看见值得说的事情时才开口
- 用户忙的时候它自动安静
KAIROS 为何被编译开关保护
KAIROS 位于 assistant/ 目录,由 PROACTIVE / KAIROS 编译期开关控制。外部发布版完全不包含这段代码。这意味着 Anthropic 自己也在谨慎地测试这个功能,尚未决定是否开放给所有用户。
一个被动的 Agent 只在收到指令时行动,你清楚它做了什么——因为是你让它做的。一个主动的 Agent 可能在你没注意的时候改了不该改的文件、发了不该发的消息、读了不该读的信息。KAIROS 的整个体系设计,就是在回答一个问题:如何让一个主动的 AI 既强大又安全?
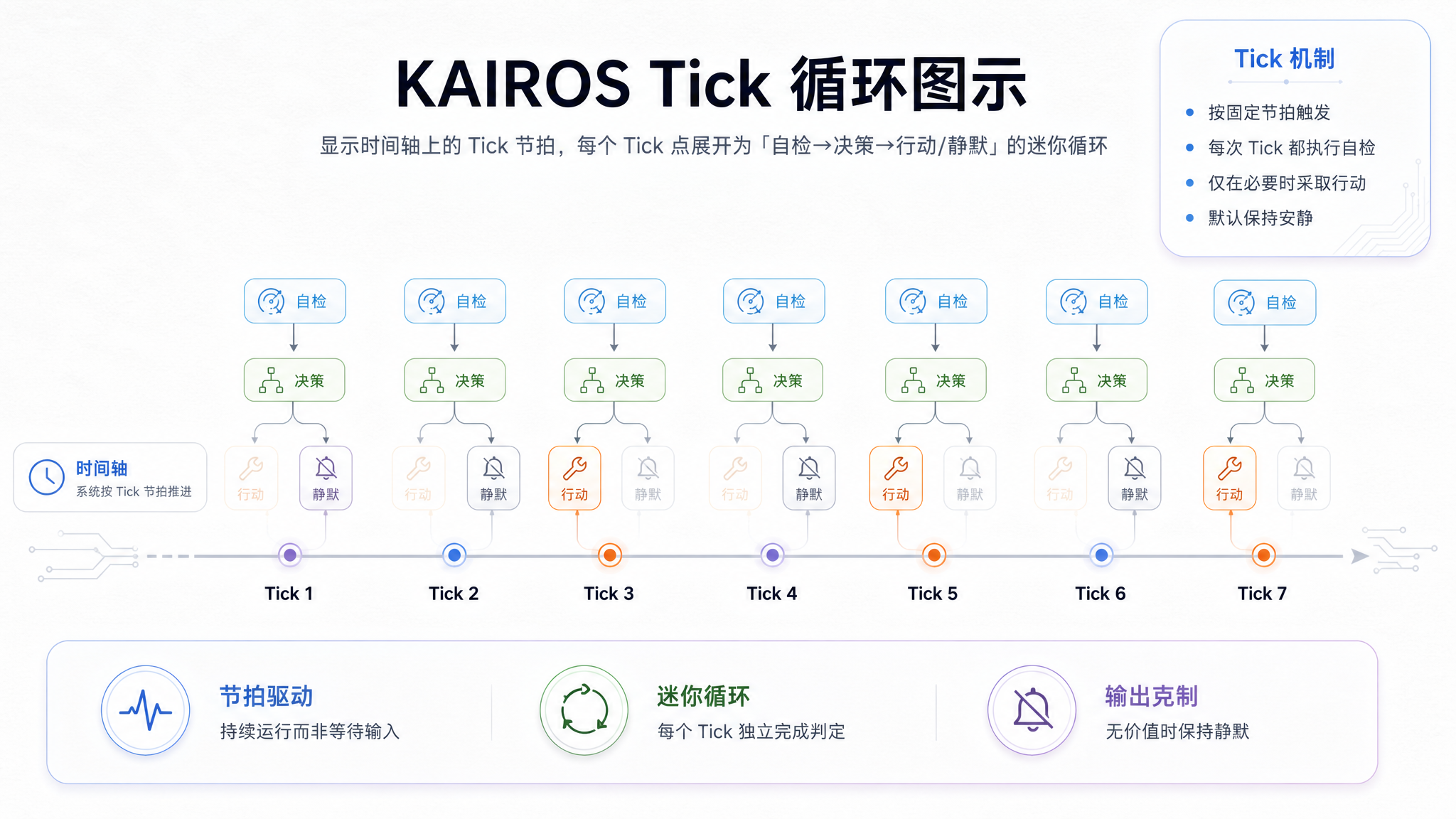
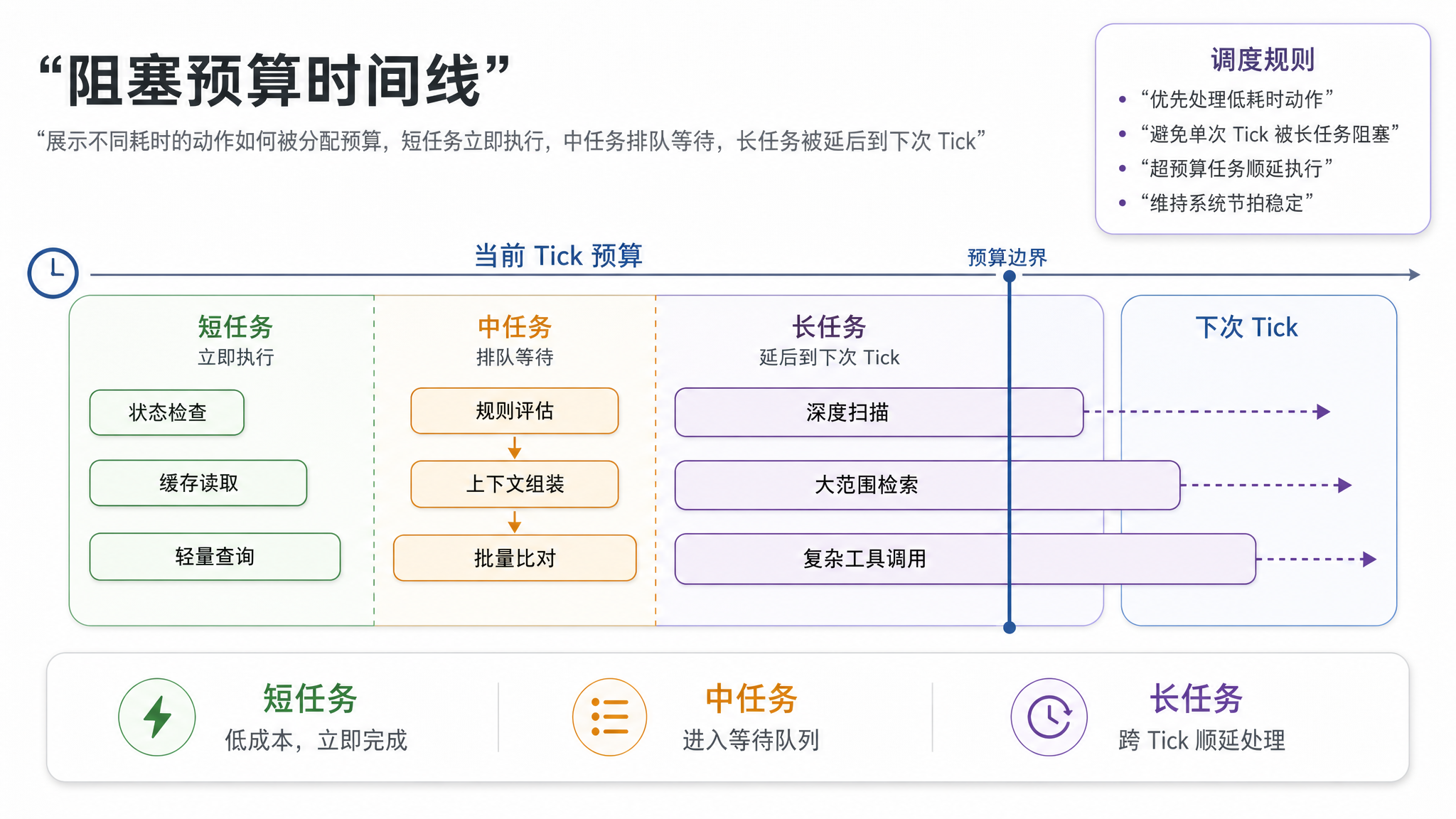
二、KAIROS 的 Tick 驱动机制
从用户输入到系统节拍
常规 Agent 的工作循环由用户消息触发:
用户输入 → 模型推理 → 工具调用 → 输出 → 等待下一个用户输入
KAIROS 换掉了触发器:不再等待用户输入,而是按固定时间间隔接收系统级 Tick 信号。
系统 Tick → KAIROS 自检 → 决策是否行动 → 行动(或静默) → 等待下一个 Tick
Tick 的执行语义
这个 Tick 不是 JavaScript 的 setInterval——它比那复杂得多。Tick 是一个由系统注入的结构化信号,携带当前环境快照:
interface TickContext {
timestamp: number; // 当前时间
delta: number; // 距上次 Tick 的时间差
pendingChanges: Change[]; // 待处理的环境变更
userActive: boolean; // 用户是否正在交互
blockingBudget: number; // 当前可用的阻塞预算是多少毫秒
}
每次 Tick 到达时,KAIROS 会:
- 1检查优先级——对比当前观察队列中各项事务的紧急程度
- 2检查阻塞预算——如果某个动作会阻塞用户操作 >15 秒,自动延后
- 3检查用户活跃度——用户正在终端输入时,不发声
- 4决定输出模式——用完整输出还是 Brief 模式
日志系统:Tick 的反馈回路
KAIROS 维护着一套按天追加写入的日志系统:
// 日志路径示例:~/.claude/kairos/logs/2026-05-26.md
// 每条日志格式:[HH:mm:ss] <观察事件> → <决策> → <动作结果>
日志持续记录:
- 每个 Tick 触发了哪些观察
- 做了哪些决策
- 执行了什么动作
- 动作的结果
这套日志是 KAIROS 的"外部记忆"——不依赖模型上下文来回顾自己的行为。这对于一个自主行动的 Agent 至关重要:没有日志,它不知道自己半小时前做了什么;有了日志,它能基于真实历史做决策,而不是靠模糊的上下文推理。
三、15 秒阻塞预算的设计哲学
为什么是 15 秒?
在终端工作的核心体验是"我在控制"。用户敲下命令、看到输出、做下一步决策——这是一个循环。
KAIROS 如果花 30 秒分析日志、然后弹结果,用户要么等得不耐烦,要么以为自己把终端搞死了。但如果它只花 5 秒看一眼就退回来——就像余光扫过——用户几乎感知不到。
阻塞预算的分配策略
const BLOCKING_BUDGET_MS = 15_000;
function canProceed(context: TickContext): boolean {
if (context.blockingBudget < BLOCKING_BUDGET_MS) return false;
// 如果动作预估耗时 > 剩余预算,延后
if (estimatedDuration(context.pendingAction) > context.blockingBudget) {
deferToNextTick(context.pendingAction);
return false;
}
return true;
}
阻塞预算的分配遵循几条原则:
- 1短动作优先:低于 1 秒的动作(查文件是否存在、读一行日志)几乎总是放行
- 2长动作排队:超过 5 秒的动作需要额外判断价值
- 3超时动作被暂停:如果一个动作开始后阻塞了 >15 秒还未完成,KAIROS 应该主动中止它
如果 AI 的主动行为挡到了你——不管它觉得那事多重要——它应该让路。这个 15 秒不仅仅是技术参数,它是"用户优先"从口头承诺到工程落地的代码化表达。
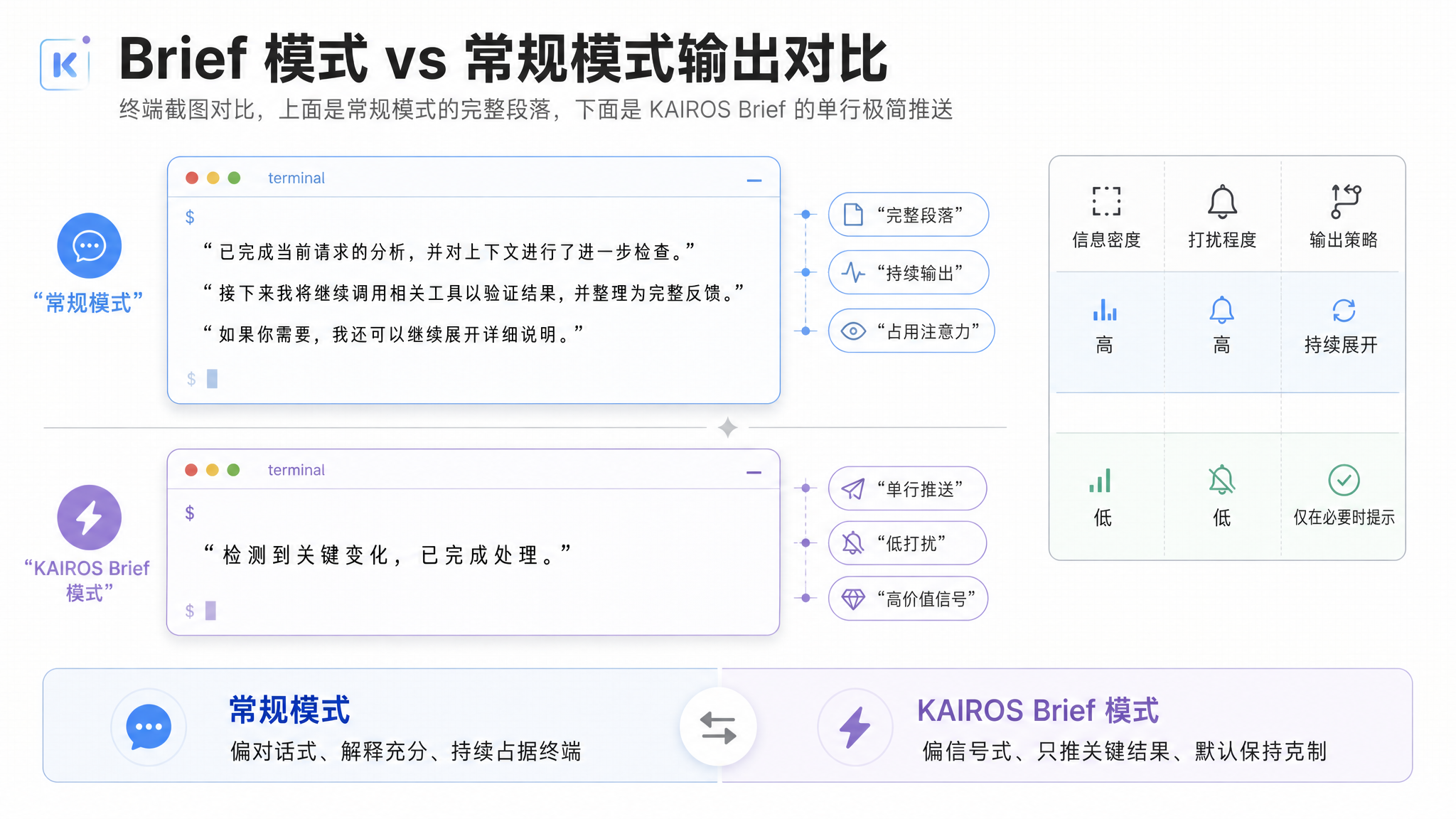
四、Brief 极简输出模式
从话痨到惜字如金
常规 Claude Code 的输出是完整的:它解释在做什么、怎么做、结果是什么、下一步建议是什么——如同一个热心的同事。
但 KAIROS 的输出不是这样。
它的输出模式叫 Brief——极度简洁的轻量输出风格。目标是:在用户不被集中注意力的前提下传递最大信息量。
一个带 Brief 和常规输出对比的例子:
常规输出(用户主动发起):
"I've checked the CI status for the last 3 runs. The latest run (ID #1423) has 2 failing
tests in the auth module. Here's the error: AssertionError at fixtures/test_auth_flow.py:84.
The issue appears to be caused by a recent change to the JWT token expiry in PR #442.
Would you like me to investigate further?"
Brief 输出(KAIROS 主动推送):
"[CI: auth 模块有 2 个测试失败,JWT 过期变更相关 #442]"
一行。没有上下文铺垫,没有解释步骤,没有后续建议。用户知道发生了什么、相关的 PR 是什么——然后自己去决定要不要深入。
Brief 的触发条件
function shouldUseBrief(output: ActionOutput): boolean {
// 用户不在交互状态 → 用 Brief
if (!context.userActive) return true;
// 正在处理紧急问题 → 用完整输出
if (context.urgentIssue) return false;
// 信息量低于阈值 → 用 Brief(不值得细说)
if (output.importance < BRIEF_THRESHOLD) {
return true; // 或用 HEARTBEAT_OK 完全静默
}
return false;
}
KAIROS 的输出风格不是"节省 token"——那是表面效果。深层目的是尊重用户的注意力带宽。每个终端开发者都经历过"日志刷屏"的痛苦——KAIROS 的 Brief 模式从根本上避免成为那个刷屏者。
五、KAIROS 专属工具
普通 Agent 没有的能力
KAIROS 的工具箱里,有几个普通 Claude Code 完全不存在的工具。这些工具的设计让 KAIROS 能做的不仅仅是"看"——它还能主动推送。
SendUserFile:直接推文件
普通 Agent 写文件,是你告诉它"把结果写到这里"。KAIROS 的 SendUserFile 能直接把文件推到用户设备上——用户甚至不需要知道文件存在,KAIROS 自己决定推送。
interface SendUserFileInput {
path: string; // 本地文件路径
reason: string; // 为什么推这个文件
format?: 'markdown' | 'raw' | 'diff';
}
PushNotification:设备推送
这是最能体现"常驻"属性的工具。KAIROS 可以向用户设备发送推送通知——不是终端里的气泡,是手机弹出的通知。
场景:你合上了笔记本去喝咖啡,CI 终于跑完了。KAIROS 发一条推送——“CI 通过了 ✅"。你不需要一直盯着终端。
interface PushNotificationInput {
title: string; // 推送标题(极限简洁)
body: string; // 推送正文(控制在 100 字内)
priority?: 'info' | 'warning' | 'urgent';
}
SubscribePR:Pull Request 订阅监控
KAIROS 不只在当前 Tick 扫描一次 PR——它订阅 PR 的变化事件,持续监控。当有人 review、有新 comment、CI 状态变化时,它主动接收变更并采取行动。
interface SubscribePRInput {
repo: string;
prNumber: number;
events: ('review' | 'comment' | 'status' | 'merge')[];
actionOnEvent?: 'notify' | 'fetch-diff' | 'check-status';
}
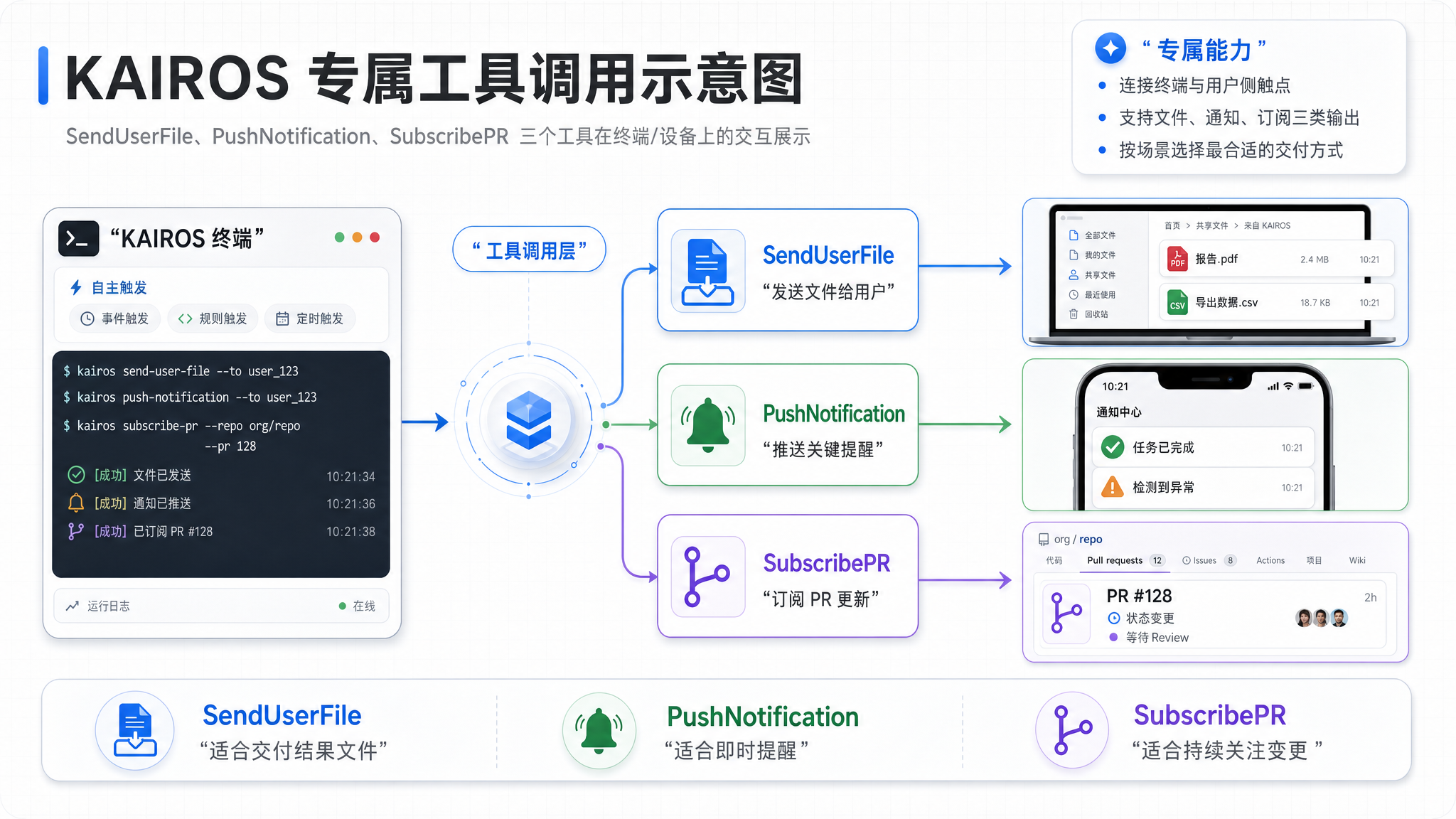
为什么这些工具"不能"给普通 Agent
如果普通 Claude Code 也有这些工具:
- SendUserFile:用户让 Agent 写个 Hello World,Agent 决定推 100 个文件到用户桌面
- PushNotification:Agent 在深更半夜发 50 条通知告诉你任务完成
- SubscribePR:Agent 订阅了 200 个 PR,把消息队列撑爆
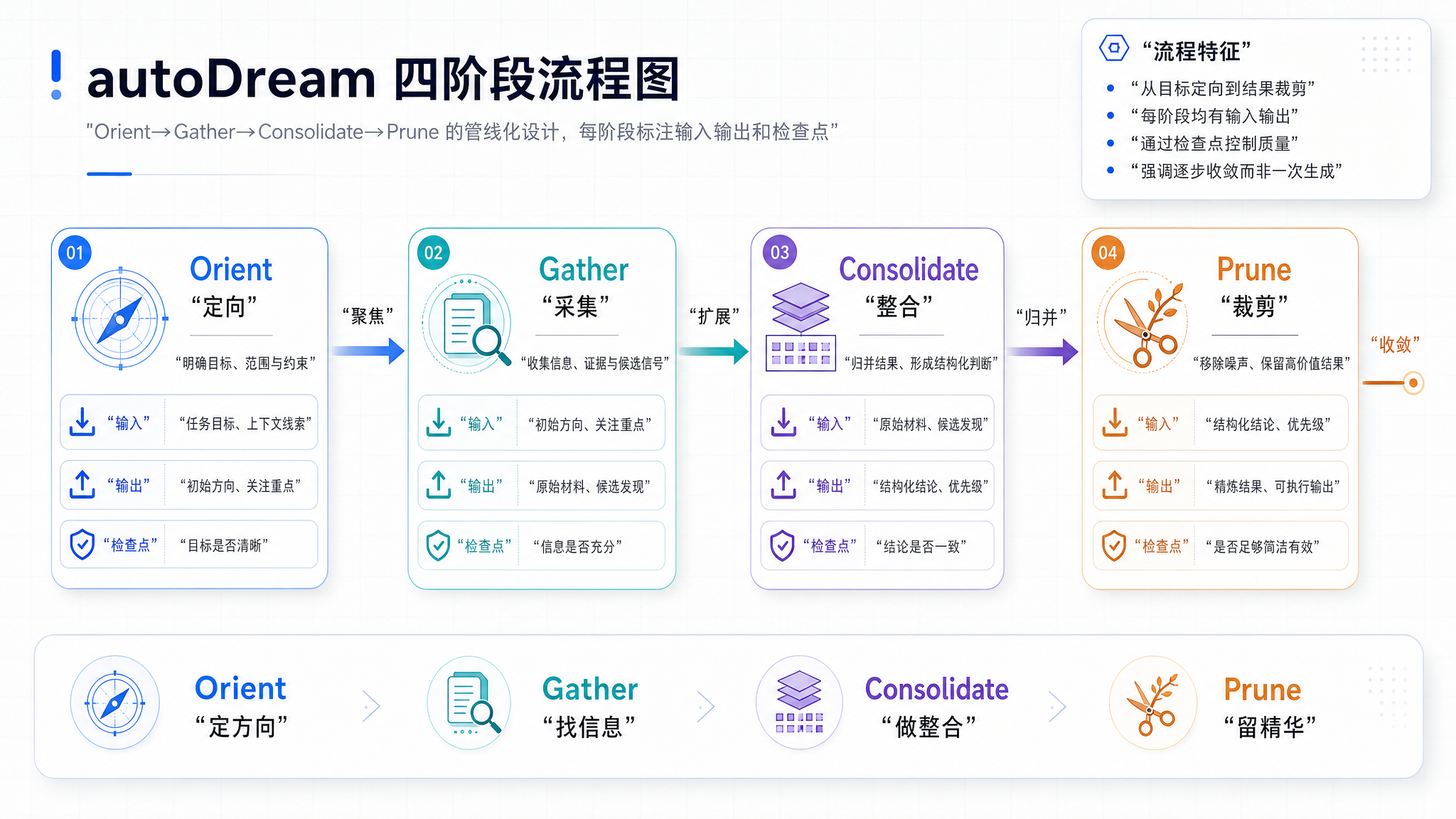
六、autoDream 记忆整合引擎
为什么要有一个独立的记忆系统?
在 #2 中我们拆解了 Claude Code 的工具系统——40 个工具各司其职,包括读写文件。但有一个更深层的需求是"读写文件"无法满足的:Agent 需要定期停下来,思考自己学到了什么。
这就是 autoDream 记忆整合引擎的定位——位于 services/autoDream/ 目录。
三重门槛机制
autoDream 不是每次空闲都跑。它有三道门槛把关:
const DREAM_GUARD = {
timeThreshold: 24 * 60 * 60 * 1000, // 24h 时间门槛
sessionThreshold: 5, // 5 次会话门槛
lockThreshold: { maxConcurrent: 1 }, // 防并发锁
};
function shouldDream(context: DreamContext): boolean {
// 门一:距离上次 dream 不足 24h → 不跑
if (Date.now() - context.lastDreamTime < DREAM_GUARD.timeThreshold) return false;
// 门二:距离上次 dream 不足 5 次会话 → 不跑
if (context.sessionsSinceLastDream < DREAM_GUARD.sessionThreshold) return false;
// 门三:另一个 dream 正在跑 → 不跑(防并发)
if (context.dreamInProgress) return false;
return true;
}
四阶段流程
当三重门槛全部通过后,autoDream 启动四阶段流程:
type DreamStage = 'Orient' | 'Gather' | 'Consolidate' | 'Prune';
async function runDream(context: DreamContext): Promise<DreamResult> {
const state: DreamState = { ... };
// 1. Orient:快速扫描当前知识状态,标记过时/冲突的记忆
state.stage = 'Orient';
const scanResult = await scanMemory(state.memoryIndex);
// 2. Gather:从会话日志、工具调用记录、输出产物中提取新信息
state.stage = 'Gather';
const newInsights = await gatherInsights(context.sessionLogs);
// 3. Consolidate:综合新旧信息,更新记忆结构
state.stage = 'Consolidate';
const consolidated = await consolidate(scanResult, newInsights);
// 4. Prune:裁剪过时/冗余的记忆,保持记忆质量
state.stage = 'Prune';
const pruned = await prune(consolidated, {
maxTokens: MEMORY_BUDGET,
});
return { ...pruned, summary: 'Dream completed' };
}
每阶段之间有明确的检查点,任何一个阶段耗尽了资源预算就提前结束——宁可不做完,也不要强制占用系统资源。
只读 bash 权限的特殊设计
autoDream 在运行时的 bash 权限被严格限制为 只读。它可以用 bash 读日志文件、查 git 历史、看系统状态——但不能写任何东西。
KAIROS + autoDream:主动系统中的互补组件
KAIROS 负责"向外看”——观察终端、作业、PR 等外部状态,决定何时该行动。autoDream 负责"向内看"——观察 Agent 自己的记忆和经历,决定何时该整理。两个系统一个向外一个向内,构成了完整的主动决策循环。
七、三条设计原则
从 KAIROS 和 autoDream 的源码设计中,可以提炼出三条适用于任何主动 Agent 系统的设计原则。
原则 1:帮助但不打扰(Helpful but Not Annoying)
这条写在 KAIROS 的系统提示词里,但更重要的是它写在了每个工程决策中:
- 15 秒阻塞预算——如果会挡住你,那就不做
- Brief 输出模式——如果不说也行,那就不说
- Tick 节拍检查用户活跃度——如果你在忙,那就不打扰
- autoDream 的三重门槛——如果不够格,那就不跑
衡量一个主动系统是否成熟,不看你让它多能干,而看它多能控制自己。
原则 2:低优先级是美德
主动系统的核心悖论是:它越主动,越可能干扰用户。KAIROS 和 autoDream 共用一套降级策略:
- KAIROS:长任务延后到下次 Tick,阻塞超预算就放弃
- autoDream:三重门槛防过早执行,阶段预算用完就提前结束
主动系统的"主动"不是"抢占"——恰恰相反,主动系统应该把自己当成最低优先级的任务,永远给用户的主线程让路。
原则 3:价值优先于频率
KAIROS 不追求每次 Tick 都有输出。实际上,大部分 Tick 的决策结果都是"什么都不做"。
# 日志示例:一个典型的周一早晨
[07:32:15] Tick: 扫描文件变更 → 无可议项目 → 静默
[07:37:14] Tick: 扫描文件变更 → 无可议项目 → 静默
[07:42:16] Tick: CI 状态变化 → 3 个测试失败 → Brief 推送
[07:47:13] Tick: 扫描 CI 修复进度 → PR #442 已打开修正 → 静默(用户已知)
[07:52:15] Tick: 无可议项目 → 静默
5 个 Tick,只有 1 次真正输出了有价值信息。这不是低效——这就是设计目标。
写在最后
- Multi-Agent 解决的是规模和隔离——多个 Agent 一起干活不乱
- 工具系统 解决的是边界和安全——Agent 能做什么、不能做什么
- KAIROS 解决的是主动性和克制——AI 如何在无指令时仍创造价值
前两个问题的答案已经比较清晰——隔离、分级、缓存、消息驱动——这是许多 Agent 框架正在追赶的方向。但 KAIROS 揭示了第三个问题的答案,而这是目前市面上几乎没有任何产品认真解决的问题:一个不依赖用户输入的 AI 助手,应该如何设计?
KAIROS 的回答是:Tick 驱动但不抢占、观察但不唠叨、行动但不越界、只在有价值时出声。
这不是一个"实验"或"功能开关"——这是一个新范式的原型。当所有 Agent 都在追逐"更快响应用户"时,KAIROS 追问了一个相反的问题:“当用户不说话时,我们应该做什么?”
下一篇预告:Fork Subagent & Prompt Cache——把成本降到 10% 的工程智慧。 当 Multi-Agent 把计算分散到多台机器时,Anthropic 做了一个反直觉的设计——getSystemPrompt() 返回空字符串。这不是 bug,而是一场围绕 Prompt Cache 字节级对齐的极致成本博弈。
韬定律 vs 摩尔定律:从"缩尺寸"到"压时间"
如果你关注科技新闻,昨天一定看到这两条消息:科创50暴涨5.88%,中芯国际单日涨幅18.78%,整个半导体板块集体狂飙。
源头是华为发布了一条新定律——“韬定律”。
一条定律能让整个资本市场如此兴奋,历史上只出现过一次:1965年,摩尔定律。
五十年过去了,半导体行业终于迎来了第二条成体系的指导原则。两条定律有什么不同?它们之间的递进关系是什么?对普通人和科技从业者分别意味着什么?
今天,我用最通俗的语言把这两条定律讲清楚。
一、摩尔定律:让芯片"越做越小"的黄金法则
它说了什么?
1965年,英特尔联合创始人戈登·摩尔发现了一个有趣的规律:一块芯片上能塞进去的晶体管数量,大约每两年翻一番。
翻译成大白话:你每等两年,同样大小的芯片里就能多塞一倍的零件。
为什么这很重要?
晶体管的数量直接决定了芯片的性能。更多的晶体管 = 更强的计算能力。而"翻倍"意味着每两年性能翻倍——这就是为什么你的手机每两三年就会感觉"变卡了",不是手机变慢了,是新一代太快了。
1974年,IBM工程师登纳德补充了一条关键规则:晶体管做小的同时,电压也等比降低,所以功耗密度不变。
这条规则的意义极其重大:“做小"没有副作用。 芯片又小又快又省电,简直是完美的技术路线。
整个半导体行业自此进入了"做小就是做好"的黄金时代。Windows从95迭代到11,iPhone从1代到15代,云计算从0到全球千亿美元市场——所有这些技术进步的背后,都是摩尔定律在托底。
为什么它走不动了?
2005年前后,登纳德规则失效了。
原因是:电压不能无限降低。降到一定程度后,晶体管在"关闭"状态下开始漏电——就像水龙头关不紧。
副作用出现了:芯片越来越烫。工程师们不得不让芯片的大部分区域"轮休”——同一时间只启用部分晶体管,其余保持闲置,业内称为"暗硅"。
7纳米以下制程后,问题更严重:
- 收益减半:过去尺寸缩小一半,速度提升近四倍;现在同样缩一半,只剩两倍
- 互连瓶颈:连接晶体管的金属线路产生的延迟,超过了晶体管本身的开关速度。芯片再快,信号传不过去
- 成本飙升:2纳米节点,一颗芯片的设计预算已超过10亿美元。晶体管成本不再下降,反而上升
摩尔定律的黄金公式——“越做越小,越来越便宜”——已经失效。
二、韬定律:从"缩尺寸"到"压时间"
它说了什么?
2026年5月25日,华为半导体业务部总裁何庭波正式发表"韬(τ)定律"。
τ(tau)是电路理论中的时间常数,代表信号从一种状态切换到另一种状态所需的时间。
韬定律的核心非常简单:别再盯着"芯片做多小",改为盯着"信号跑多快"。
过去60年,芯片性能提升的本质,其实一直都是在压缩时间——晶体管变小,开关速度更快;集成度提高,信号在芯片内部跨越的边界更少。空间缩小,始终只是压缩时间的手段。
但那只是"顺便"压时间。韬定律把时间确立为芯片迭代的核心指标。
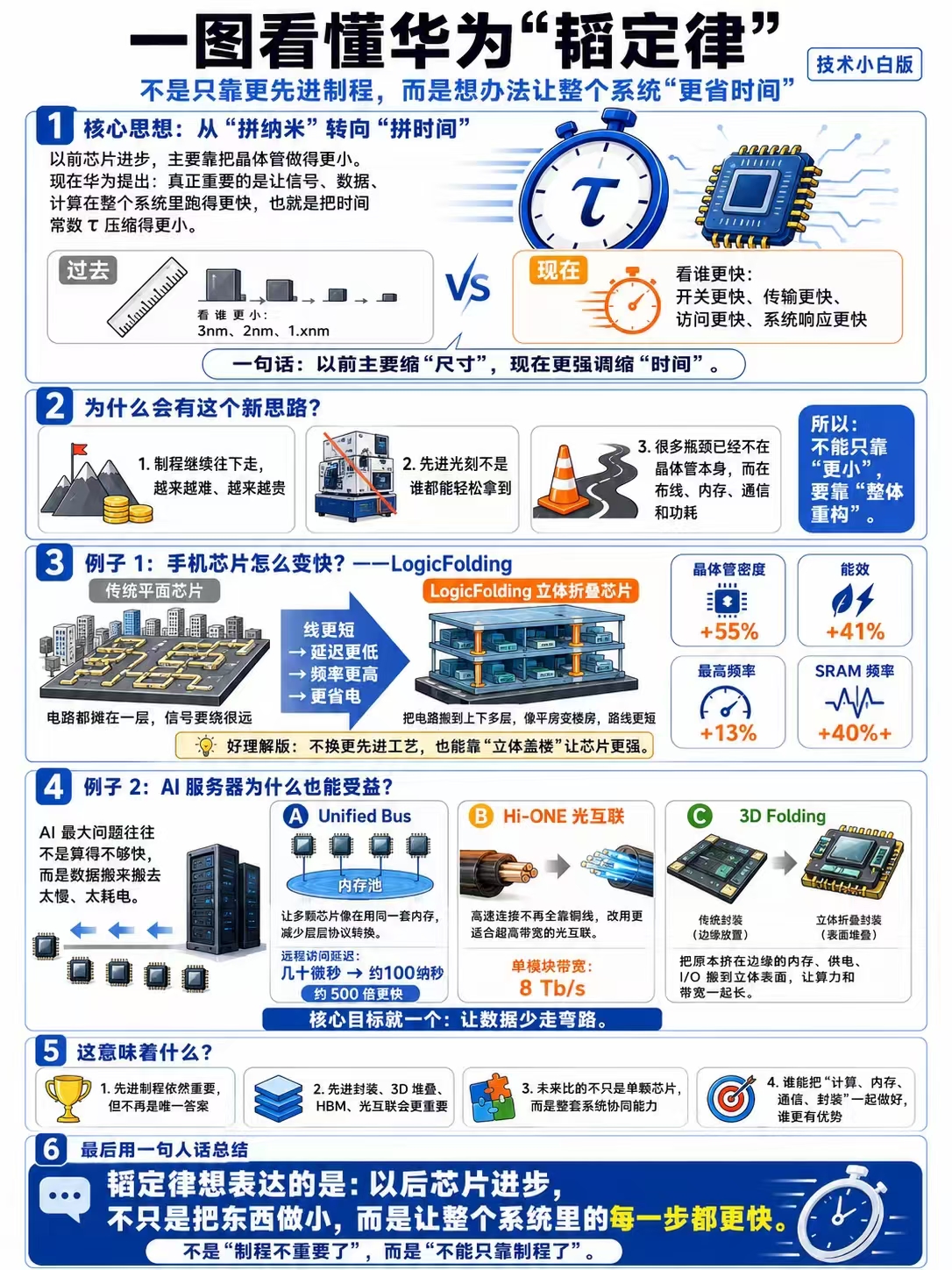
技术路径:逻辑折叠
韬定律落地需要一套全新的技术——逻辑折叠(Logic Folding)。
传统芯片把所有电路铺在同一个平面上,信号走得越远,延迟越大。逻辑折叠的做法是:把关键电路拆分到纵向堆叠的多层芯片上。
就像一个两层的城市:以前所有人在同一个平面上活动,路上堵车严重;现在把一部分人移到二楼,通过垂直电梯通行,通行效率大幅提升。
层与层之间用"混合键合"(Hybrid Bonding)技术连接——两片晶圆以微米级精度对齐,信号可以纵向穿越,走线长度大幅缩短。
已经量产验证的成果
韬定律不是纸上谈兵。华为在过去六年(2020年5月至2026年5月)基于这条路线设计并量产了381款芯片,覆盖手机、AI、汽车、工业。
41% 核心能效提升
381 基于韬定律路线量产的芯片
2026款麒麟芯片的实测数据:
- 晶体管密度:1.55亿/mm² → 2.38亿/mm²,单代涨幅55%
- 传统路线要做到这个提升,通常需要三年和一次完整制程换代
- 核心能效提升41%,最高主频3.1GHz
- 时钟缓冲器减少一半以上,布线长度缩减约30%
全部在固定制程节点内取得,没有采用新的光刻工艺。
华为的路线图显示,到2031年,晶体管密度目标突破每平方毫米4亿颗——“达到1.4纳米制程的同等水平”。
不同行业的迭代速度
摩尔定律给全行业一个统一的节奏:每两年翻一倍。
韬定律不这么做。
它的迭代速度因场景而异:
- 手机芯片(功耗受限):约每年1.3倍
- 自动驾驶:约每年1.5倍
- AI场景:可达每年10倍
三、两条定律的核心对比
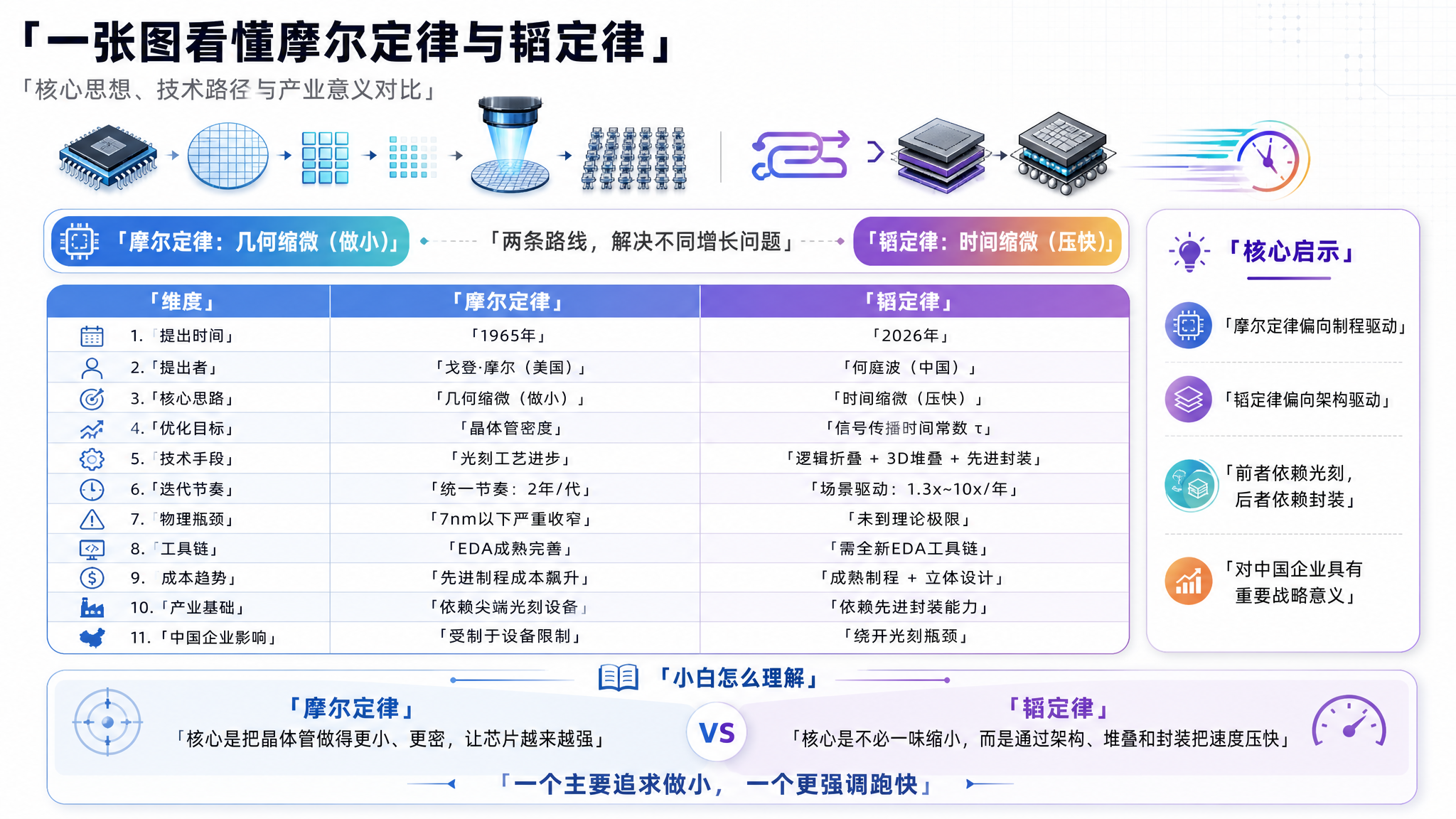
| 维度 | 摩尔定律 | 韬定律 |
|---|---|---|
| 核心指标 | 晶体管密度(空间) | 信号延迟(时间) |
| 优化路径 | 几何缩微(做小) | 逻辑折叠 + 垂直堆叠 |
| 迭代节奏 | 每18-24月翻倍,统一节奏 | 因场景而异(1.3x~10x/年) |
| 物理基础 | 依赖光刻工艺进步 | 依赖立体封装与架构设计 |
| 当前状态 | 7nm以下收益递减,成本飙升 | 已量产验证,381款芯片 |
| 产业影响 | 让全部企业共享制程红利 | 让各行业自行决定最优路线 |
四、两条路线的关系:不是替代,是接力
一个最常见的误解是:韬定律要"替代"摩尔定律。
不是。
它们的真正关系,可以从两个角度看。
技术角度:两条腿走路
韬定律和摩尔定律不是零和关系。
摩尔定律管空间密度——同样面积能塞多少晶体管。韬定律管时间效率——信号要多久跑完全程。
最好的方案是两条路线齐头并进:用摩尔定律的思路把晶体管做小、做密,再用韬定律的思路把信号路径压短、压快。一个管"密度",一个管"效率"。
产业角度:中国半导体需要的新答案
韬定律对中国半导体的意义,远大于技术本身。
2019年,华为无法继续使用海外最先进的芯片代工服务。在何庭波的话里,这种处境被概括为:“对于无法获取顶尖光刻设备的企业,发展受限问题显现更早,产业承压也更为严峻。”
华为六年前被迫面对的那个问题——“几何缩微走不动了,芯片性能靠什么继续提升?"——回过头来看,整个行业最终都将不得不面对。
韬定律给出的答案是:把优化目标从"空间"切换到"时间”,用成熟制程配合立体设计,同样可以做出高性能芯片。
它不解决"能不能做3纳米"的问题——它回答的是"做不了3纳米时,怎么做出3纳米级别的性能"。
五、未解决的挑战
何庭波在论文中坦诚列出了韬定律尚未解决的难题:
- 1EDA工具链:现有设计软件是为平面时代开发的,多层堆叠的设计需全新工具。她将其称为"未来十年最核心的基础支撑投入"
- 2晶圆工艺偏差:不同批次晶圆之间的电气参数差异,对信号时序构成很大压力
- 3能耗配套:τ是一条时间准则,不是能耗准则。速度快10倍但功耗也涨10倍,理论上不违反韬定律,但实际无法部署
- 4评测标准缺失:行业现有的Linpack、MLPerf等基准测试,无法评估全栈协同优化的效果。何庭波呼吁建立新的评测体系
她还在论文结尾写道:
摩尔定律统治了半导体行业60年,它的核心公式是:做小 = 做好 = 更便宜。
登纳德规则失效后,"做小"的成本越来越高、收益越来越低。
韬定律回答了一个更本质的问题:我们真正想要的是什么?
不是"更小的晶体管"。是"更快的计算"。
做小只是手段,压时间才是目的。
从摩尔到韬,从"缩尺寸"到"压时间",这是半导体产业从物理极限走向系统创新的第一次系统性转身。而这次转身,是中国企业提出答案的。
Claude Code 源码深度拆解:工具系统架构从 40+ 工具到权限分级管控
上一篇文章《Claude Code 源码深度拆解:Multi-Agent 的实现机制》发出后,收到很多"还没看够"的反馈。确实,Claude Code 的源码太丰富了,Multi-Agent 只是冰山一角。这次我翻出源码中另一个工程密度极高的模块——工具系统。
如果说 Multi-Agent 解决了"怎么组织多个 Agent"的问题,那工具系统解决了更底层的问题:Agent 能干什么、不能干什么、以及这个边界由谁来定。
30+ 种工具、4 级权限体系、基于 ML 的自动审批、3 道防线隔离——这套设计对任何正在构建 Agent 平台的人来说,都值得逐行品读。
一、40+ 工具的背后:一个完整的操作系统
为什么工具设计如此重要?
Agent 的本质很简单:一个 LLM + 一堆工具 + 一个 agentic loop。工具是 Agent 与现实世界的接口,定义了 Agent 的能力边界。
你给 Agent 装了多少工具,它就能做多少事。但这里藏着一个矛盾:工具越多,Agent 越强大,同时也越危险。一个带着文件写入、Shell 执行、网络访问、Subagent 管理总共 40 个工具的 Agent,就像一把装了 40 个功能键的瑞士军刀——用好了效率翻倍,但一个误操作就可能把项目目录捅个窟窿。
完整的工具目录
源码中所有工具通过 getAllBaseTools() 集中注册。按职责域可以分为 8 大类:
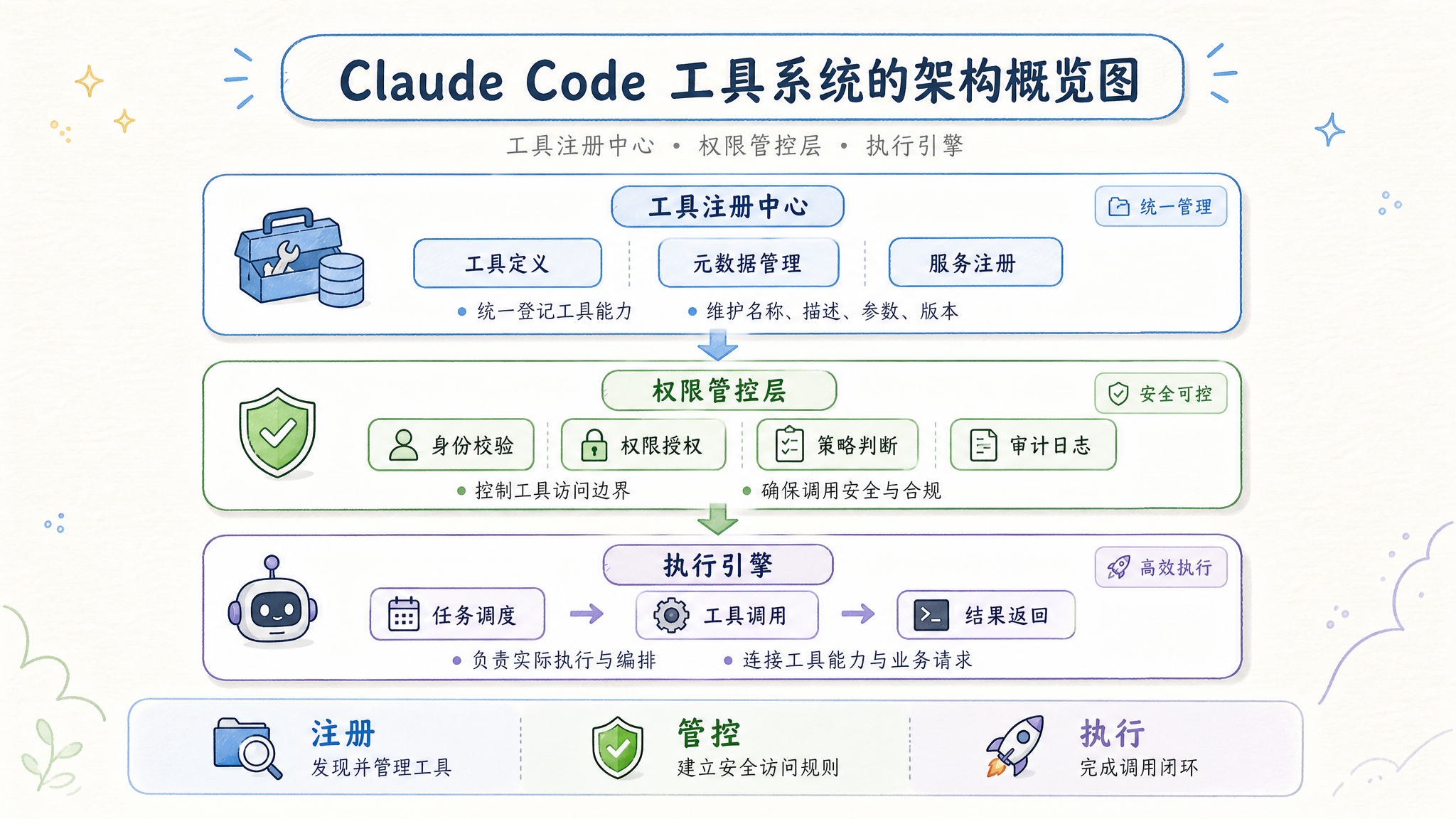
| 类别 | 工具列表 | 用途 |
|---|---|---|
| 文件工具 | FileReadTool, FileEditTool, FileWriteTool, GlobTool, GrepTool | 代码读写与搜索 |
| Shell 工具 | BashTool, PowerShellTool, REPLTool | 命令执行与交互式环境 |
| Web 工具 | WebFetchTool, WebSearchTool, WebBrowserTool | 网络访问与信息检索 |
| Agent 工具 | AgentTool, SendMessageTool, TeamCreateTool, TeamDeleteTool | 子 Agent 编排与团队管理 |
| 任务工具 | TaskCreateTool, TaskGetTool, TaskListTool, TaskUpdateTool, TaskOutputTool, TaskStopTool | 后台任务全生命周期管理 |
| MCP 工具 | MCPTool, McpAuthTool, ListMcpResourcesTool, ReadMcpResourceTool | Model Context Protocol 集成 |
| 系统工具 | SleepTool, SnipTool, ToolSearchTool, ScheduleCronTool, RemoteTriggerTool, WorkflowTool | 辅助能力 |
| 高级工具 | ConfigTool, TungstenTool, SyntheticOutputTool, VerifyPlanExecutionTool, CtxInspectTool | 内部调试与高级功能 |
二、工具注册与 Schema 缓存
为什么需要 Schema Cache?
Claude Code 的每个 API 请求都需要携带所有工具的 JSON Schema——LLM 靠它理解工具的参数结构和用法。40 个工具就意味着一大段 JSON。
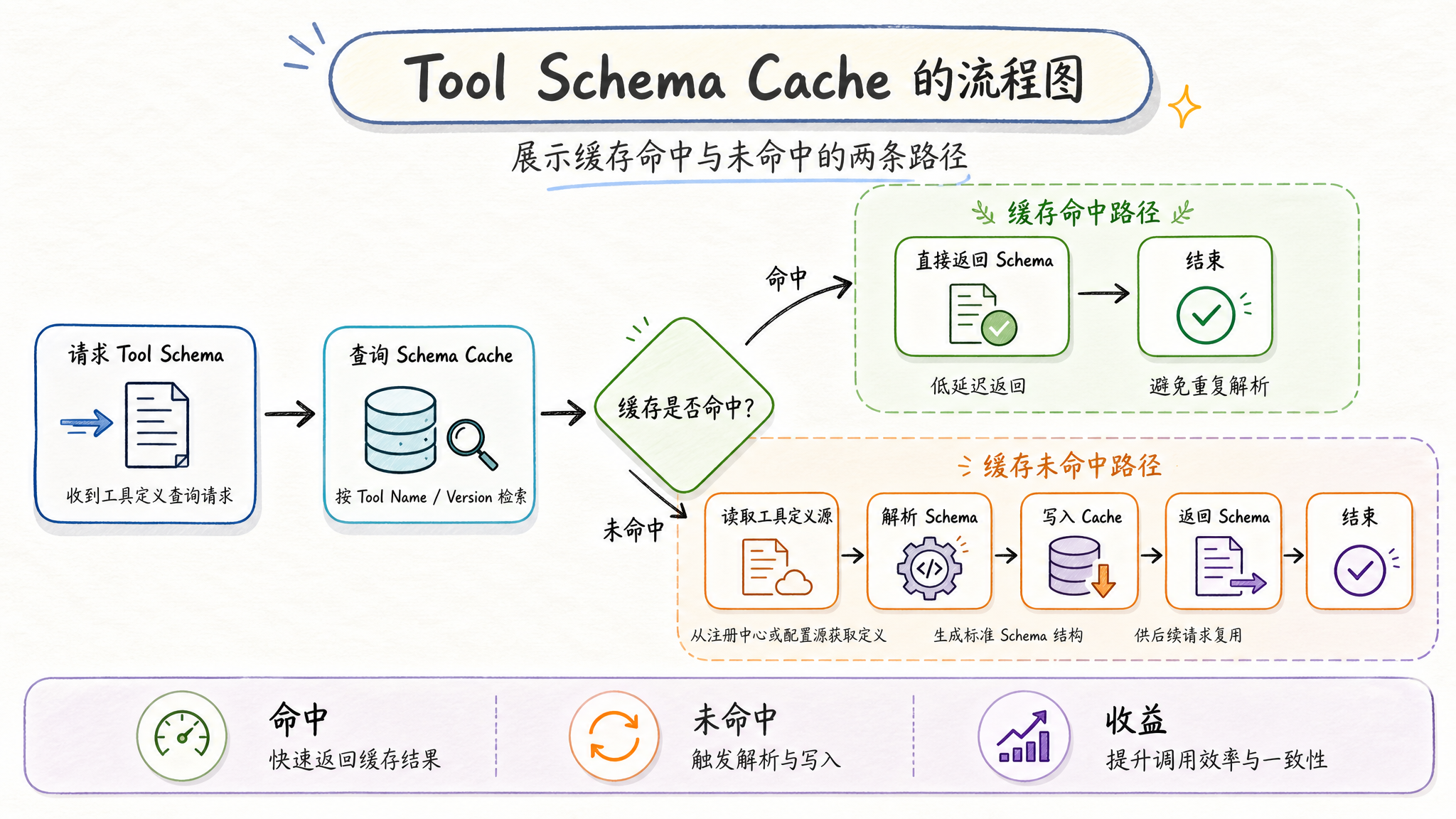
直觉方案是"每次请求都生成一份"。但工具 Schema 大部分时候是不变的。每次都重新生成,白白浪费 token——尤其是缓存友好型的请求,前缀多这一点点差异,缓存就丢了。
Claude Code 的做法是给工具 Schema 加一层内存缓存。首次构建后缓存起来,后续请求直接复用。这不仅仅是"少点 JSON 序列化"的性能优化——在 Prompt Cache 体系里,字节级一致性才是关键。
// tools/base.ts(示意代码)
let toolSchemaCache: Record<string, ToolSchema> | null = null;
export function getAllBaseTools(): Tool[] {
// 执行工具注册...
}
export function getToolSchemas(): Record<string, ToolSchema> {
if (toolSchemaCache) return toolSchemaCache; // 缓存命中,直接返回
// 缓存未命中:遍历所有工具,提取 Schema
toolSchemaCache = {};
for (const tool of getAllBaseTools()) {
toolSchemaCache[tool.name] = tool.inputSchema;
}
return toolSchemaCache;
}
三、三级权限体系:Default / Auto / Bypass
工具系统真正的核心,是这套权限分级机制。
为什么不能"一律询问"?
最直观的权限机制是"每个工具调用都问用户"——安全倒是安全了,但体验会让人崩溃。调研阶段一个文件接一个文件地读,每个都要用户确认?用户三分钟就暴躁了。
但完全放权也不现实。Claude Code 选择了一条中间路线:根据风险等级,差异化管控。
四级操作模式
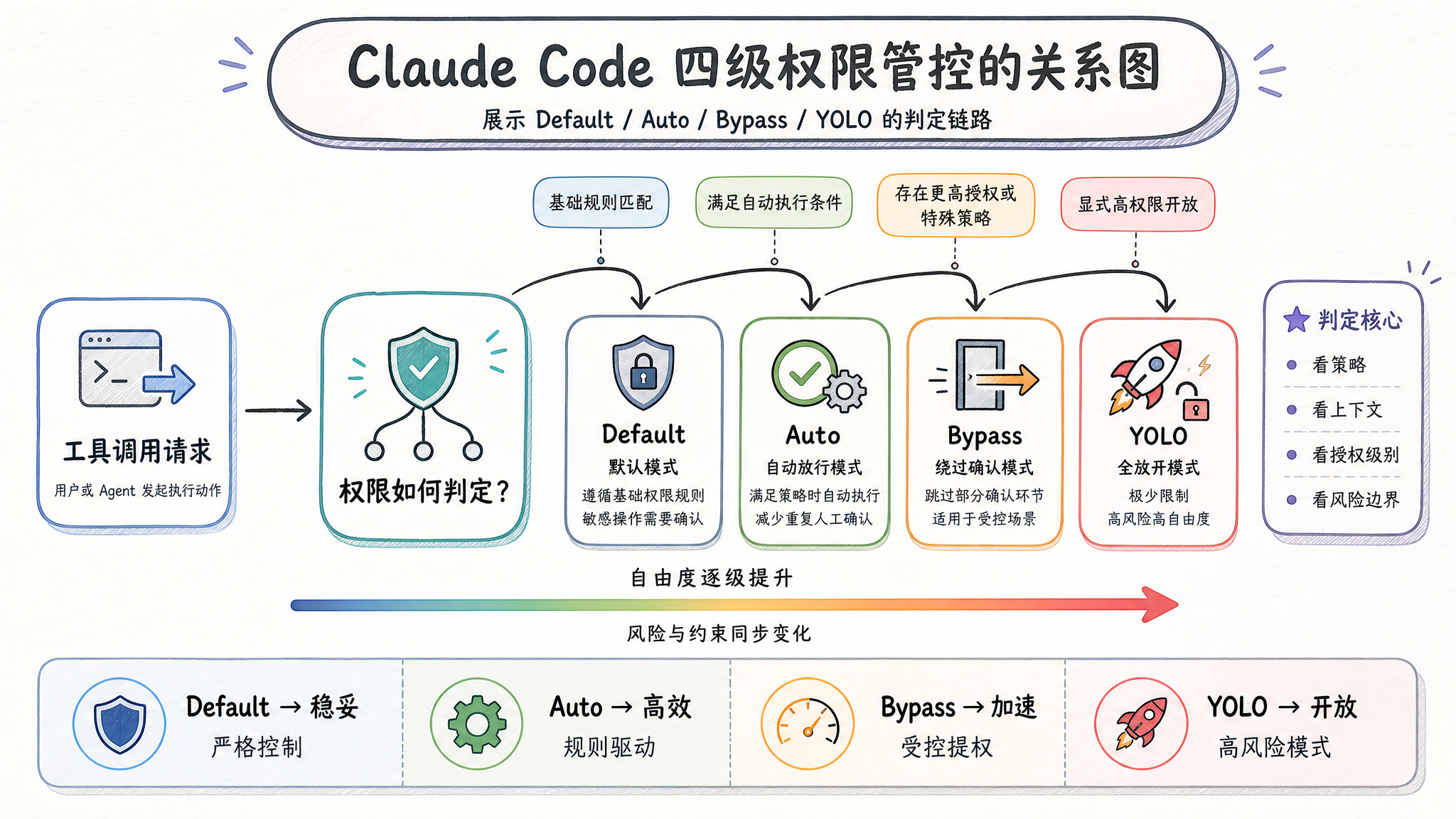
// tools/permissions/(示意代码)
type PermissionMode =
| 'default' // 交互式询问用户
| 'auto' // ML 自动审批
| 'bypass' // 跳过检查
| 'yolo' // 拒绝所有
| 模式 | 行为 | 适用场景 |
|---|---|---|
| default | 每次都弹确认框问用户 | 高风险操作(写文件、执行命令) |
| auto | ML Classifier 自动判定,低风险直接放行 | 常规操作(读文件、搜索代码) |
| bypass | 完全信任,不检查 | 信任环境(用户明确勾选"信任此操作") |
| yolo | 拒绝所有调用 | 极简模式/演示模式 |
风险等级分类
每个工具动作会被 ML Classifier 打上风险等级:
| 等级 | 示例 | 处理 |
|---|---|---|
| LOW | 读文件、grep 搜索 | auto 模式直接放行 |
| MEDIUM | 写入已知文件、运行常见命令 | auto 模式可能询问或放行 |
| HIGH | 修改系统配置、执行网络脚本 | 必须经用户确认 |
四、ML Classifier:自动审批的大脑
从"每次确认"到"自动判断"
如果你用过 Claude Code,你会发现它经常在你还没反应过来的时候就已经放行了文件读取和代码搜索——这就是 ML Classifier 的功劳。
这个分类器的正式名称在代码里叫 TRANSCRIPT_CLASSIFIER,由同名编译期开关控制。
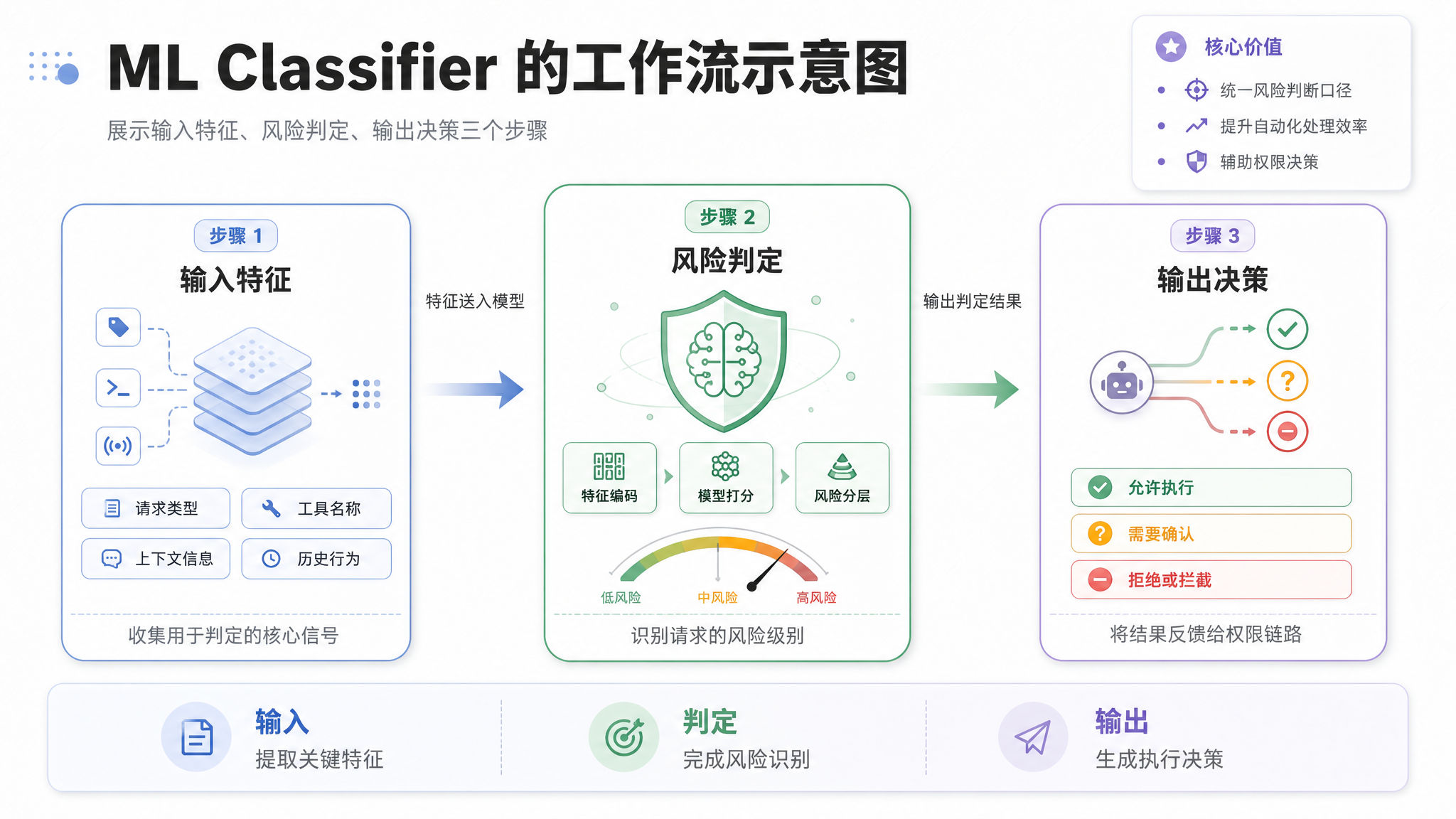
它的工作方式极简又高效:
- 1拦截工具调用请求——当某个工具被调用时,不是直接执行,而是先进入权限校验管道
- 2提取特征——当前 transcript 上下文、工具名称、参数摘要、历史行为模式
- 3ML 快速判定——一个轻量化的分类模型在几毫秒内输出风险评分
- 4决策路由——LOW 直接放行、MEDIUM 问用户、HIGH 强制确认
为什么用 ML 而不是规则?
规则系统看起来更可控:if (tool === 'FileReadTool' && path.endsWith('.ts')) → allow。但实际工程中有三个致命问题:
- 1规则爆炸——每个工具 + 每个参数组合 + 每种上下文,组合数指数级增长
- 2规则冲突——A 规则说允许,B 规则说拒绝,谁优先?
- 3规则僵化——用户习惯变了,规则改起来要发版
ML Classifier 的好处:一个模型覆盖所有场景、判定结果天然连续、无需手动维护规则。
Claude Code 对 ML 分类器的使用还有一个特别务实的策略:缓存。
// tools/permissions/yoloClassifier.ts(示意代码)
// 使用 CACHED_MAY_BE_STALE 模式,避免阻塞主循环
const decision = getFeatureValue_CACHED_MAY_BE_STALE(
'tengu_transcript_classifier',
{ context: transcript }
);
五、Protected Files:最后一道防线
供应链攻击的防御
最危险的 Agent 行为是什么?修改你的 Shell 配置文件。
想象一下:你让 Agent “排查 CI 构建失败”——Agent 读日志、查配置、改了一个环境变量,顺手把你的 .bashrc 加了一行恶意命令。下次你 SSH 登录,shell 一启动就执行了攻击代码。
这就是 Claude Code 的 Protected Files 机制要解决的问题。
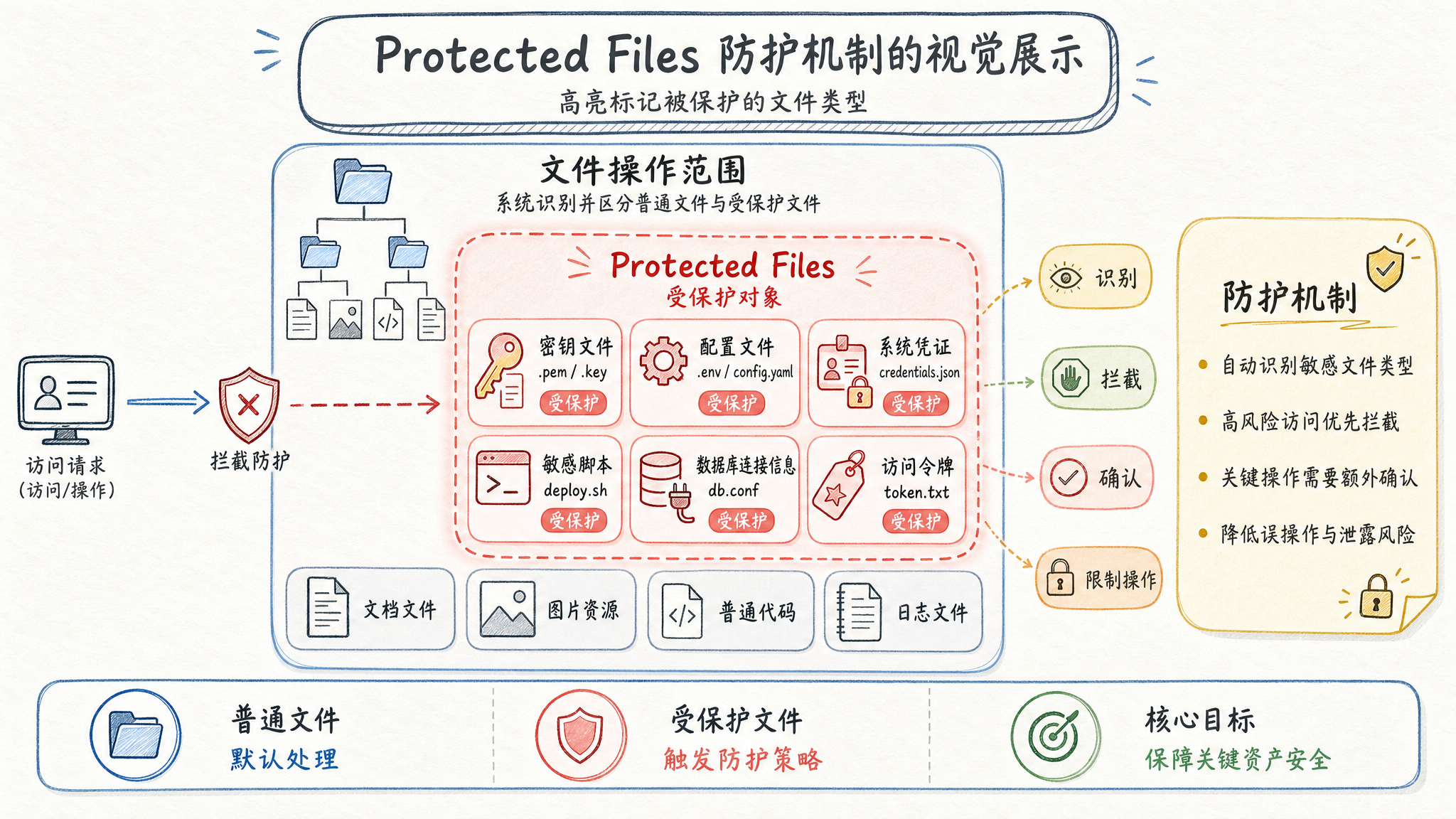
// tools/permissions/protectedFiles.ts(示意代码)
const PROTECTED_FILES_PATTERNS = [
'**/.gitconfig', '**/.bashrc',
'**/.zshrc', '**/.ssh/config',
'**/.ssh/id_*', '**/.gnupg/**',
'**/.npmrc', '**/.env',
'**/credentials', '**/authorized_keys',
];
这些文件是 Shell 和 Git 的安全命门。Agent 可以读它们(排查 SSH 问题),但写操作会被拦截——无论权限模式是什么。
路径遍历防护
Claude Code 的路径安全不仅卡文件后缀,还防路径遍历攻击:
function isPathTraversal(path: string): boolean {
return path.includes('..') || path.startsWith('/');
}
如果 Agent 试图用 ../../../etc/passwd 或者绝对路径绕过限制,系统会直接拒绝。
CYBER_RISK_INSTRUCTION
除了代码层的防护,Claude Code 在 System Prompt 里嵌入了一段名为 CYBER_RISK_INSTRUCTION 的安全指令:
// IMPORTANT: DO NOT MODIFY THIS INSTRUCTION WITHOUT SAFEGUARDS TEAM REVIEW
// This instruction is owned by the Safeguards team (David Forsythe, Kyla Guru)
这段指令划定了明确的安全边界,由专门的 Safeguards 团队持有——不是谁都能改。
六、工具隔离的三道关卡
当 40 个工具遇到 Subagent
你给主 Agent 配了 40 个工具,但 Subagent 不能照单全收。原因很直接:
- Subagent 能派 Subagent?——递归失控
- Subagent 能问用户?——抢对话权
- Subagent 能 stop 其他任务?——权限越级
在 #1 那篇文章里,我们提到了 filterToolsForAgent 的三道过滤。
// src/tools/AgentTool/agentToolUtils.ts:70(源码示意)
export function filterToolsForAgent({ tools, isBuiltIn, isAsync, permissionMode }): Tools {
return tools.filter(tool => {
// 第一道:MCP 工具全放行
if (tool.name.startsWith('mcp__')) return true;
// 第二道:全局黑名单
if (ALL_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false;
// 第三道:自定义 Agent 加严
if (!isBuiltIn && CUSTOM_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false;
// 第四道:异步 Agent 走白名单
if (isAsync && !ASYNC_AGENT_ALLOWED_TOOLS.has(tool.name)) return false;
return true;
});
}
三关设计的工程智慧
- **第一关(全局黑名单)**解决"谁都不能做什么"——安全底线
- **第二关(自定义加严)**解决"非官方的需要更严"——风险分级
- **第三关(异步白名单)**解决"自动跑的必须更轻"——后台节制
每关独立演化、互不干扰。想加新规则?找到对应的集合,加一行就行。
七、五条工具系统设计原则
- 1权限不分级等于没权限。"一律询问"和"一律放行"都不对。按操作的风险等级匹配不同的管控模式,才是工程上可落地的方案。
- 2自动审批靠 ML,不靠规则。工具系统有 40 个工具,每个工具的参数组合是无穷的。规则系统管不住这种复杂度。ML Classifier 用概率思维替代二值判断。
- 3最危险的 20% 操作需要硬锁定。Protected Files 机制的关键洞察是:20% 的操作(写 Shell 配置、SSH 密钥)占了 80% 的安全风险。对这部分操作做硬锁定。
- 4工具过滤是分层级的,不是一杆子打死。工具权限不是"能与不能"的二选一,而是"在什么场景下能用什么"的条件判断。
- 5工具 Schema 缓存是 Prompt Cache 的基础设施。把工具 Schema 缓存起来,不仅仅是优化请求速度——它是"让多 Agent 体系不因工具定义差异增加成本"的架构决策。
Claude Code 的工具系统,表面是 40 个功能点的注册与调用,实质是一套围绕"Agent 能力的边界"构建的工程体系。
从 Schema Cache 的字节级对齐,到 ML Classifier 的容错缓存策略,再到 Protected Files 的硬锁定——每一个设计决策都在回答同一个问题:Agent 该被允许做什么?
这个问题的答案,决定了你的 Agent 系统是强大的帮手,还是失控的隐患。
下一篇预告: Claude Code 源码深度拆解——KAIROS 常驻助手与 autoDream 记忆整合
Claude Code 源码深度拆解:Multi-Agent 的实现机制
Claude Code 的源码堪称 AI Agent 工程的教科书。 前段时间源码泄露后,社区得以窥见 Anthropic 在多 Agent 设计上的工业级实践。这篇文章从源码视角,拆解 Claude Code 中三套不同的多 Agent 机制:常规 Subagent、Fork Subagent 和 Coordinator 协调者模式。
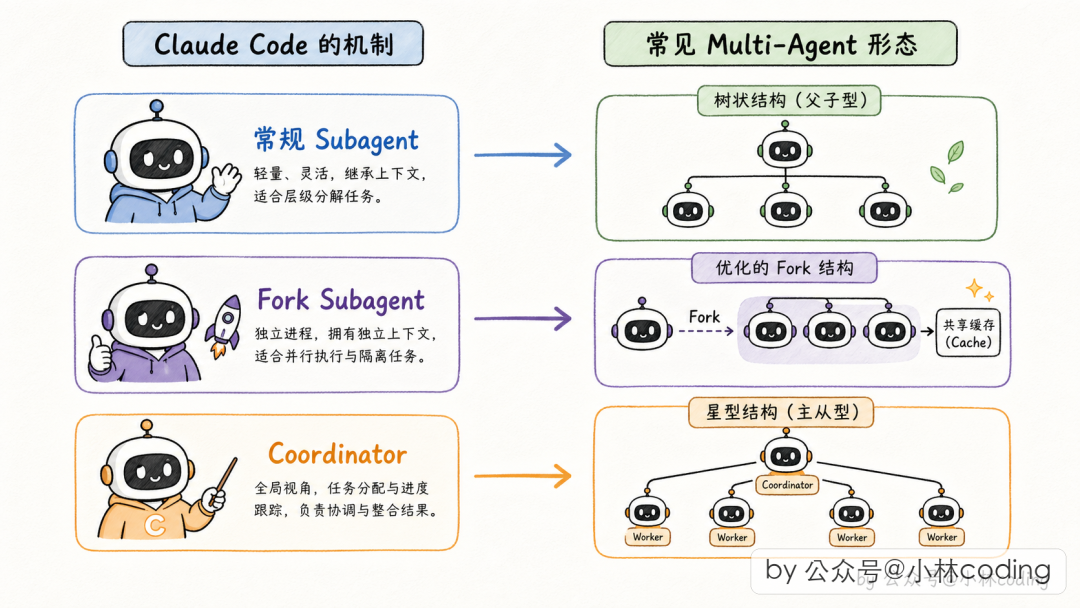
一、Multi-Agent 的本质与三种形态
为什么一个 Agent 不够用?
回到最朴素的 Agent 模型:一个 LLM + 一堆工具 + 一个循环(agentic loop)。看起来够用,但遇到真实项目问题就暴露了:
上下文爆炸。 调研阶段要看大量文档,实现阶段要读写项目代码,评审阶段要重新审视。三个阶段的内容全塞到一个 Agent 的上下文里,token 蹭蹭往上涨。
职责混乱。 一个 Agent 既当研究员又当程序员又当评审员,调研到一半就开始写代码,代码写到一半又去查文档。
无法并发。 一个 Agent 一次只能做一件事,在查文档时,其他工作只能干等。
Multi-Agent 的思路很直观:把一个大任务拆给多个职责清晰的 Agent 去做,通过某种机制通信和协作。
工业界常见的三种形态
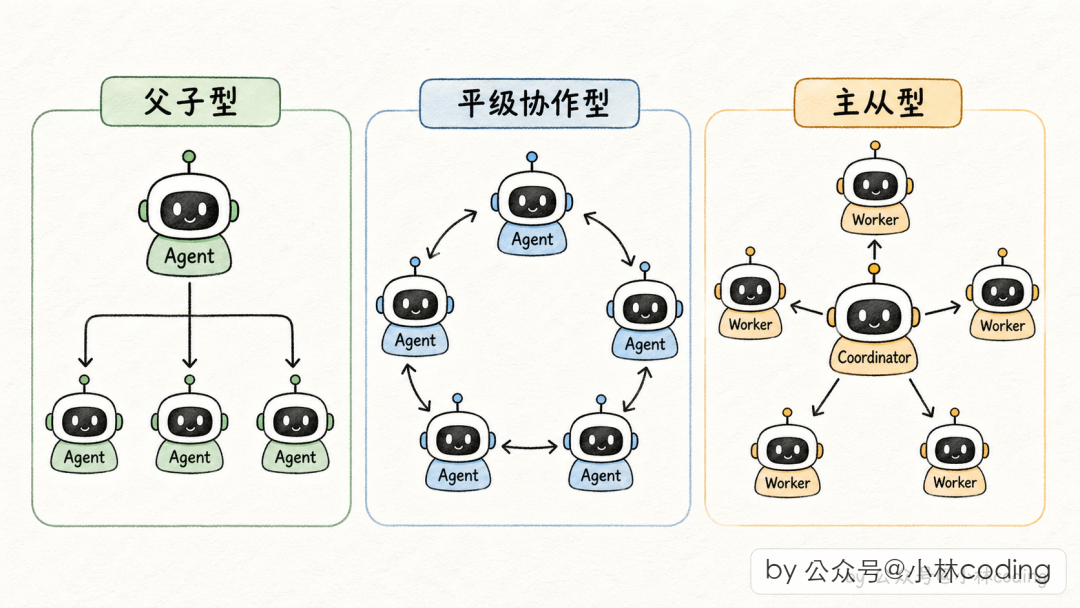
| 形态 | 模型 | 说明 |
|---|---|---|
| 父子型 | 主 Agent 派 Subagent 做事,拿结果继续 | Claude Code 的 Task 工具 |
| 平级协作型 | 多 Agent 共享状态、互相通信 | 工程上落地困难,状态同步复杂 |
| 主从型 | 协调者派 Worker,Worker 间互不通信 | 高并发场景标配,Claude Code 的 Coordinator 模式 |
Claude Code 源码里,常规 Subagent 对应父子型,Coordinator 模式对应主从型,Fork Subagent 是父子型的优化变体。
二、Subagent 的隔离机制
多 Agent 系统本质是"一堆 Agent 共处一个进程、共享一个底层运行时"。隔离做不好,一个 Subagent 偷偷污染父 Agent 的状态,整个系统就乱了。Claude Code 从 两个维度 做隔离:工具隔离和上下文隔离。
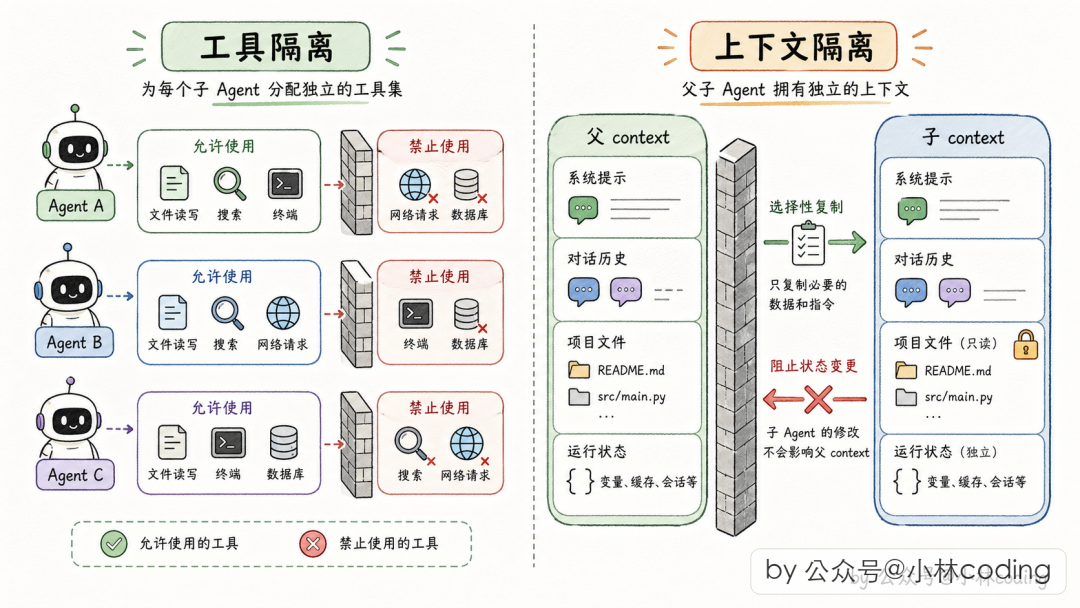
第一维度:工具隔离——定制工具箱
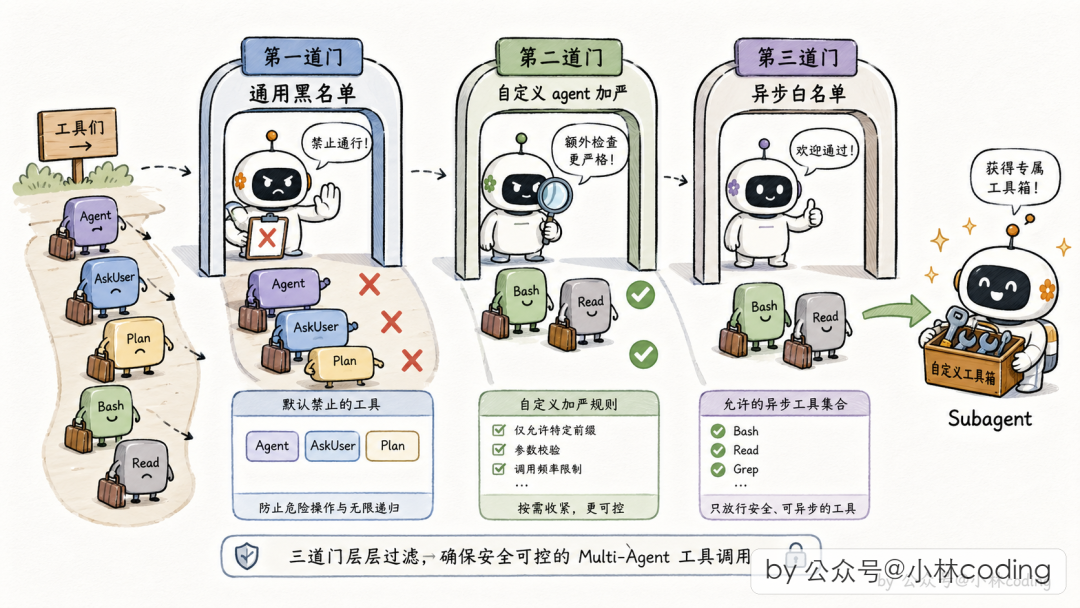
主 Agent 拥有几十个工具(读文件、写文件、执行命令、派 Subagent、问用户……),但不能原封不动丢给 Subagent。Claude Code 按 三道准入门 过滤:
第一道:全局黑名单。 所有 Subagent 都不能用的工具:
- 能派新 Subagent 的工具——防递归嵌套
- 能主动问用户的工具——Subagent 不该抢对话权
- 能切换规划模式的工具——子没有资格
- 能停止其他任务的工具——任务管理是主线程专属
第二道:自定义 Agent 加严黑名单。 用户自写的 Agent 比内置 Agent 多一层防护。
第三道:后台异步 Agent 走白名单。 默认不准用,只有明确列出的才能用(读文件、搜代码、执行命令等)。
// src/tools/AgentTool/agentToolUtils.ts:70
export function filterToolsForAgent(
{ tools, isBuiltIn, isAsync, permissionMode }
): Tools {
return tools.filter(tool => {
if (tool.name.startsWith('mcp__')) return true // MCP 全放行
if (ALL_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false
if (!isBuiltIn && CUSTOM_AGENT_DISALLOWED_TOOLS.has(tool.name)) return false
if (isAsync && !ASYNC_AGENT_ALLOWED_TOOLS.has(tool.name)) return false
return true
})
}
第二维度:上下文隔离——按字段粒度决策
这是 Claude Code 最精髓的设计之一。父 Agent 的运行时上下文很庞大(文件缓存、UI 状态、中止信号、权限状态、任务注册表……)。
两个直觉方案都走不通:
- 完全共享:子 agent 读文件读了 200 行,父的缓存被刷成 200,以为自己也读过,数据出错
- 完全新建:用户 Ctrl+C 中止,子 agent 因为全新上下文收不到中止信号,自顾自跑
四个关键决策:
- 1读文件缓存 → 克隆一份。 子怎么折腾都不影响父的文件视图。
- 2写全局状态 → 关闭。 子 agent 完全没有写 UI 状态的权限,防止界面抢写。
- 3任务注册通路 → 保留。 子 agent 起的后台进程需要登记到全局任务表,不然变孤儿进程。
- 4发独立 ID + 深度 +1。 系统随时知道当前嵌套层数,深度超阈值时报警停止。
// src/utils/forkedAgent.ts:345
export function createSubagentContext(parentContext, overrides): ToolUseContext {
return {
// 决策一:文件读缓存克隆一份
readFileState: cloneFileStateCache(parentContext.readFileState),
// 决策二:写全局状态直接设为空操作
setAppState: () => {},
// 决策三:但任务注册的通路例外保留
setAppStateForTasks: parentContext.setAppStateForTasks ?? parentContext.setAppState,
// 决策四:独立 ID + 深度 +1
agentId: overrides?.agentId ?? createAgentId(),
queryTracking: {
chainId: randomUUID(),
depth: (parentContext.queryTracking?.depth ?? -1) + 1,
},
// ...
}
}

三、父子 Agent 的通信机制
隔离只是开始,决定系统好不好用的是 怎么通信。
为什么不用函数调用?
直觉方案是"父 Agent 调个函数,等 Subagent 跑完返回"。但有两个致命问题:
- 同步阻塞:Subagent 跑 5 分钟,父 Agent 啥也干不了,用户说话没反应
- 无法并发:要派 5 个 Subagent 调研 5 个模块,要么排队阻塞,要么手动搓并发代码
Claude Code 换了一个完全不同的路子:消息驱动。
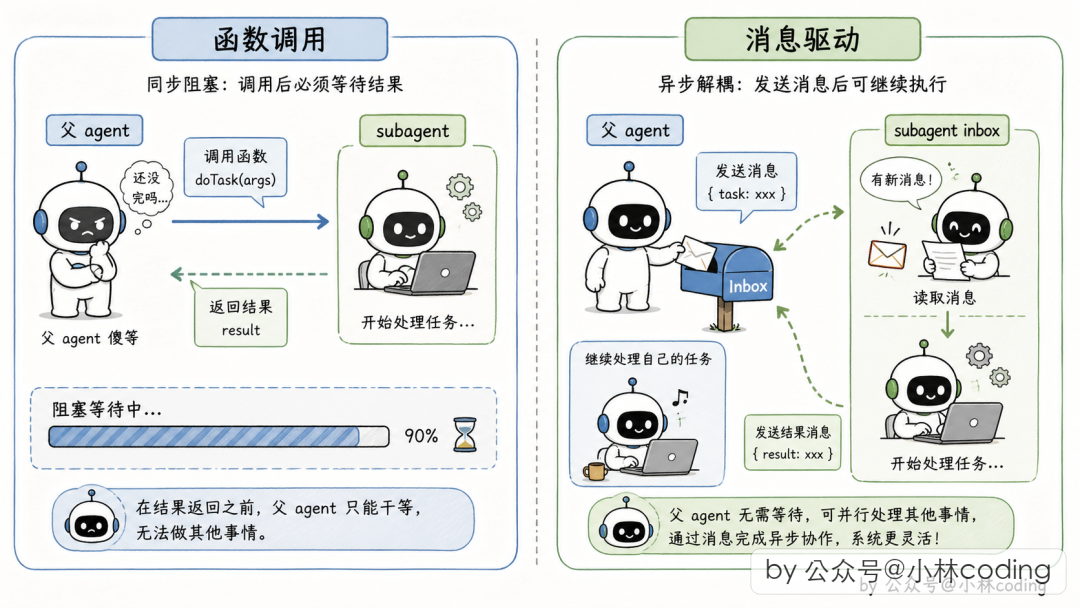
Subagent 的"员工档案"
每个 Subagent 有一个对象,记录 ID、状态、信箱(待处理消息数组)、进度等:
// src/tasks/LocalAgentTask/LocalAgentTask.tsx:116
export type LocalAgentTaskState = TaskStateBase & {
type: 'local_agent';
agentId: string;
prompt: string;
status: TaskStatus; // pending / running / completed / failed / killed
result?: AgentToolResult;
pendingMessages: string[]; // 信箱:父扔进来的待处理消息
// ...
};
父 → 子:扔字条 + 子自己取
父 Agent 调 SendMessage 工具,往目标 Subagent 的信箱末尾追加一条消息,然后立刻返回。Subagent 在每轮工具调用结束后,瞄一眼自己的信箱,有新消息就注入对话历史。
如果 Subagent 已经完成,Claude Code 会自动唤醒它——从 transcript 恢复对话历史,拼上新消息重新跑起来。
子 → 父:把通知伪装成用户消息
Subagent 跑完后,把完成通知拼成 XML 消息,伪装成用户消息塞给父 Agent 的对话历史:
<task-notification>
<task-id>agent-a1b</task-id>
<status>completed</status>
<summary>Agent "Investigate auth bug" completed</summary>
<result>Found null pointer in src/auth/validate.ts:42...</result>
<usage>
<total_tokens>12345</total_tokens>
<tool_uses>8</tool_uses>
<duration_ms>34567</duration_ms>
</usage>
</task-notification>
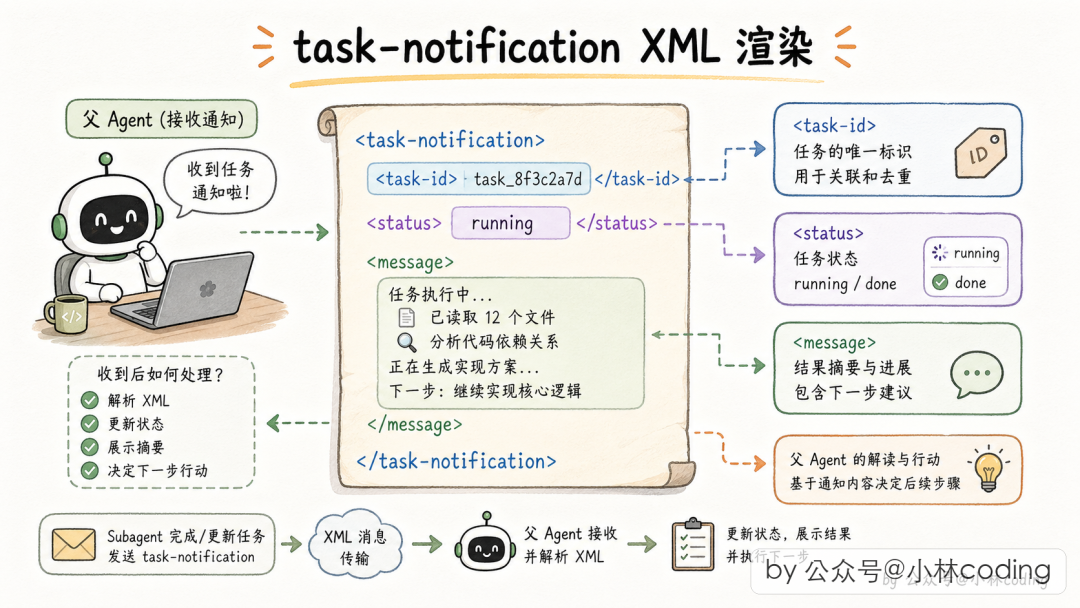
为什么要用 XML? Anthropic 训练 Claude 时就强调 XML 结构化表达;XML 是纯文本可塞进对话历史;伪装成用户消息,天然复用 Agent 的 agentic loop 处理逻辑。
Auto-background:同步到异步的自动降级
Subagent 跑起来后,如果 30 秒内完成,父在前台阻塞等;超过 2 分钟,自动转到后台(auto-background),父 Agent 先干别的。2 分钟后 Subagent 完成,通过 task-notification 把结果送回。
// src/tools/AgentTool/AgentTool.tsx:72
function getAutoBackgroundMs(): number {
if (isEnvTruthy(process.env.CLAUDE_AUTO_BACKGROUND_TASKS)
|| getFeatureValue_CACHED_MAY_BE_STALE('tengu_auto_background_agents', false)) {
return 120_000; // 2 分钟
}
return 0;
}
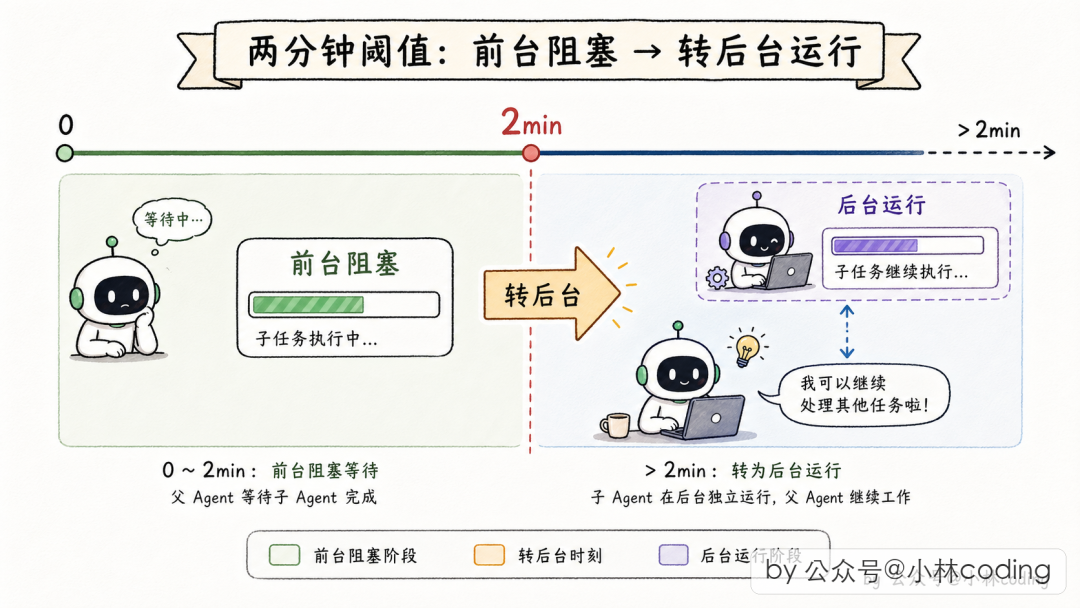
整个通信体系就两个关键字:异步 + 消息。没有直接函数调用,没有锁,没有回调地狱,全靠读写共享的任务状态和消息队列。
四、Fork Subagent:省钱又省延迟的隐藏大招
Subagent 的隐藏成本
Claude Code 的 system prompt 上万 token。每派一个 Subagent,LLM API 要对这一万多 token 重新算一遍。Anthropic 的 prompt 缓存机制可以缓解——如果请求前缀跟之前某次一样,前缀可以走缓存,只需原来 10% 的价格。
但缓存命中的条件是:字节级别完全相同。 一个字、一个空格不一样,缓存就不命中。
Fork 的核心思路:派一个"字节级相同"的分身
Fork Subagent 的设计目标是:让 Subagent 的 API 请求前缀跟父 Agent 字节级一致,从而复用父的缓存。
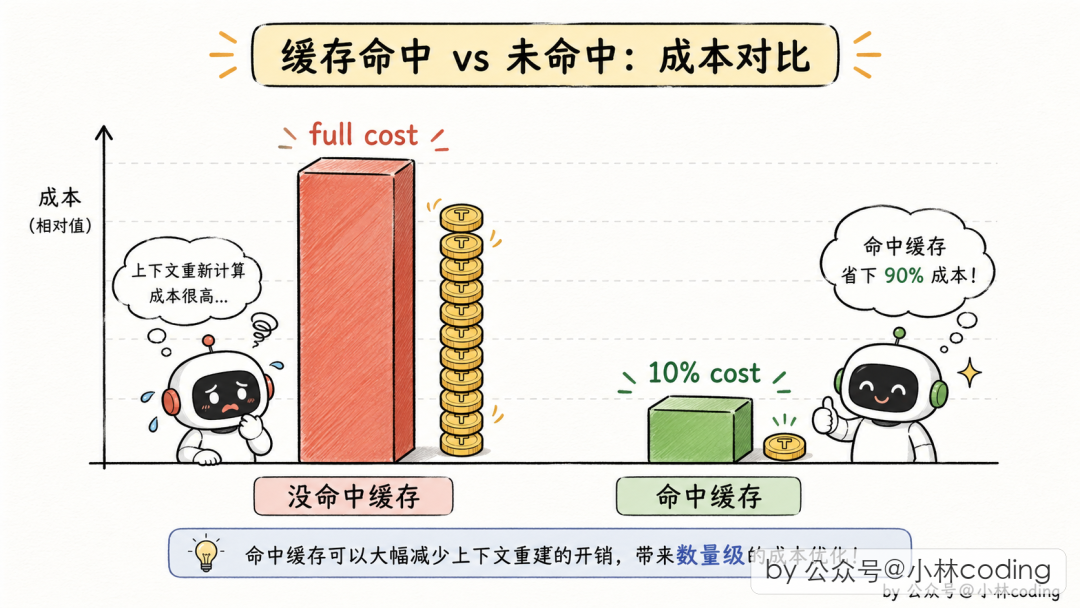
要对齐五样东西:
- 1系统 prompt 内容 — 最核心
- 2用户上下文 — 当前项目的 CLAUDE.md 等
- 3系统上下文 — system prompt 后的环境信息
- 4工具池顺序和定义 — 序列化顺序都不能变
- 5对话历史前缀 — 决定"从哪里开始分叉"
// src/utils/forkedAgent.ts:57
export type CacheSafeParams = {
systemPrompt: SystemPrompt
userContext: { [k: string]: string }
systemContext: { [k: string]: string }
toolUseContext: ToolUseContext
forkContextMessages: Message[]
}
一个特别有工程智慧的细节:Fork Subagent 的 getSystemPrompt 直接返回空字符串——不是为了省事,而是因为 Fork 的 system prompt 根本不是通过这个函数生成的,而是直接用父 Agent 已经渲染好的那字节。重新调一次生成函数可能会有微小差异,缓存就没了。
export const FORK_AGENT = {
agentType: FORK_SUBAGENT_TYPE,
tools: ['*'], // 用父的完整工具池
model: 'inherit',
getSystemPrompt: () => '', // 返回空串!
} satisfies BuiltInAgentDefinition
Fork 机制和 Coordinator 模式是互斥的——职责重叠,只留一个。
五、Coordinator 模式:真正的多 Agent 并行
前面讲的 Subagent 本质是父子结构。但如果要并行调研 10 个模块,就需要更强大的机制。Claude Code 的 Coordinator 模式 就是为此设计的。
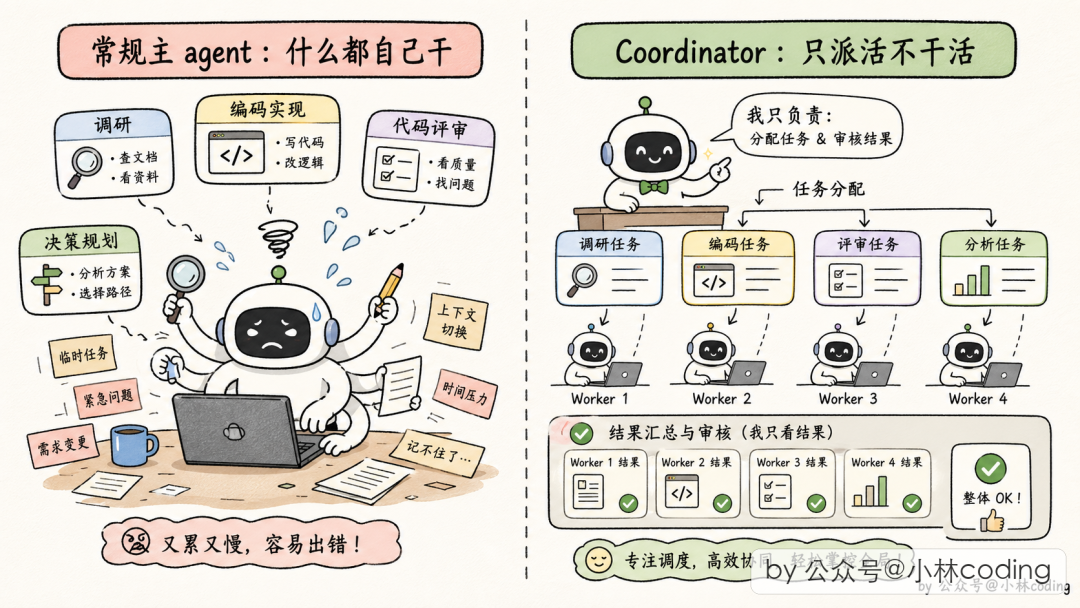
核心设计:主 Agent 退化成"纯协调者"
需要编译开关 + 环境变量 CLAUDE_CODE_COORDINATOR_MODE=1 启。
开启后,主 Agent 不干实际工作了,只做三件事:派 Worker、收结果、合成答案。这个角色转换通过 system prompt 强制约束:
You are a coordinator. Your job is to:
- Direct workers to research, implement and verify code changes
- Synthesize results and communicate with the user
五大内部工具
Coordinator 模式下,主 Agent 多了一套"团队管理"工具箱:
| 工具 | 作用 |
|---|---|
| 派 Worker | 派一个新 Worker 出去干活,派完立刻返回 ID |
| 创建/解散团队 | 批量管理 Worker 组 |
| 发消息 | 给已派出的 Worker 发后续指令 |
| 合成输出 | 协调者把最终回复交给用户 |
| 停止 Worker | 跑错方向时停掉省 token |
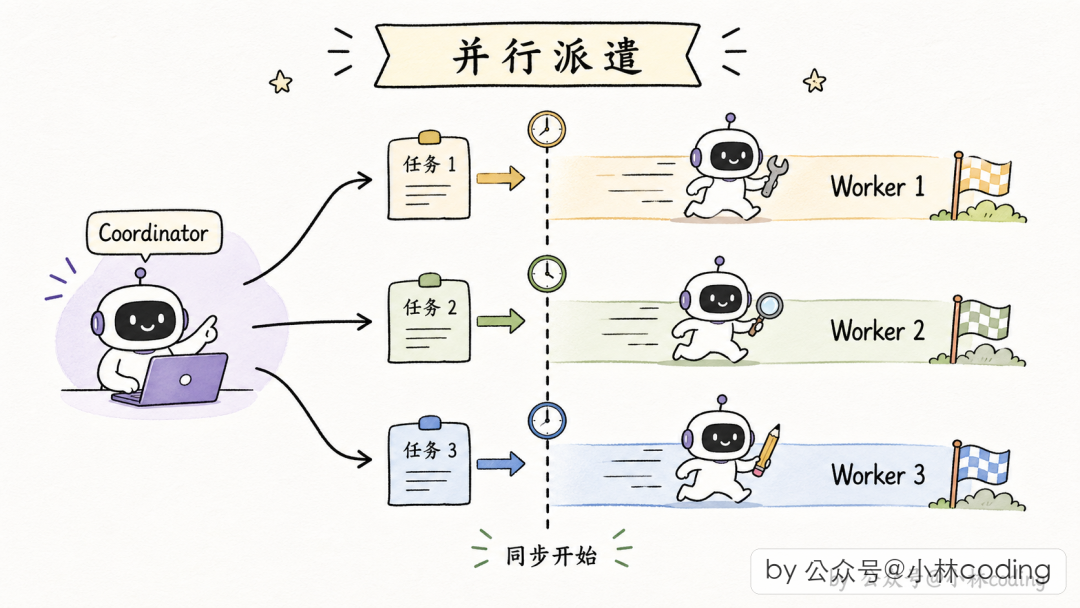
并行是超能力
Coordinator 的 prompt 里有一句金句:“Parallelism is your superpower.”
派 Worker 的工具调用可以在同一条 assistant 消息里出现多次,底层一起并发执行:
- 串行:派 Worker1 → 等 → 结果 → 派 Worker2 → 等 → 结果 → 用户等十分钟
- 并行:同时派三个 Worker → 三份结果陆续到 → 用户等三分钟多一点
任务流水线
| 阶段 | 执行者 | 目的 |
|---|---|---|
| 调研 | Workers(并行) | 调查代码、找文件、理解问题 |
| 合成 | 协调者本人 | 读 findings、写实现规格 |
| 实现 | Workers | 按规格做具体修改 |
| 验证 | Workers(新 Worker) | 测试改动是否工作 |
中间的"合成"阶段是协调者亲自做——协调者必须"理解"而不能"转发"。这是多 Agent 系统里最容易踩坑的一点。
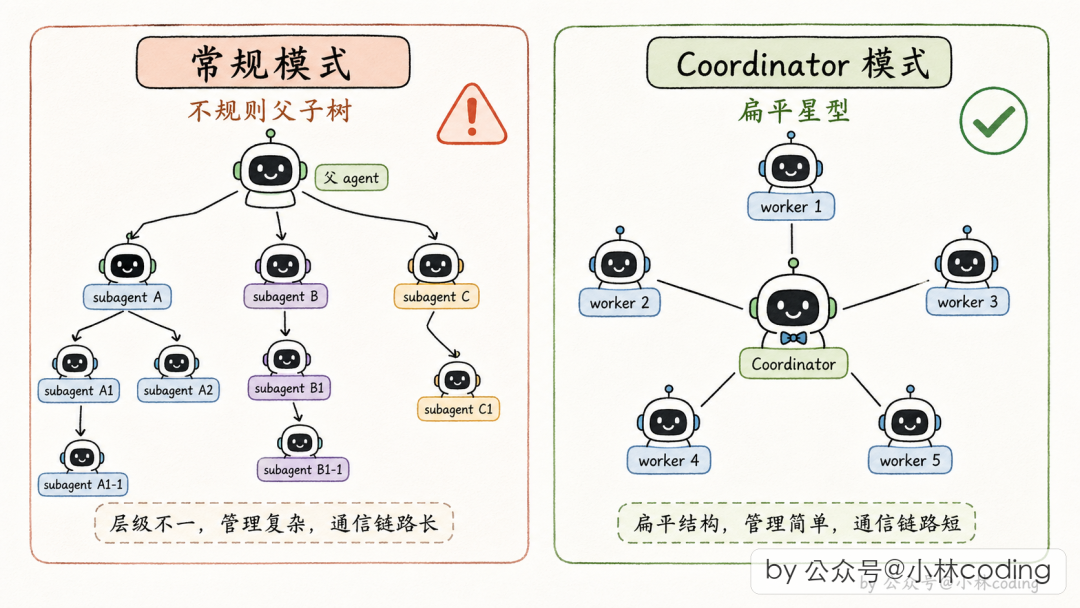
与常规 Subagent 对比
| 维度 | 常规 Subagent | Coordinator 模式 |
|---|---|---|
| 主 Agent 角色 | 全能选手 | 纯协调者 |
| 执行方式 | 同步(2 分钟转后台) | 默认异步 |
| 并发程度 | 偶尔并发 | 最大化并发 |
| 适合场景 | 单个任务 + 临时帮手 | 大任务 + 高并发拆解 |
| 系统形态 | 父子树 | 协调者 + Worker 扁平层 |
六、五条 Multi-Agent 设计原则
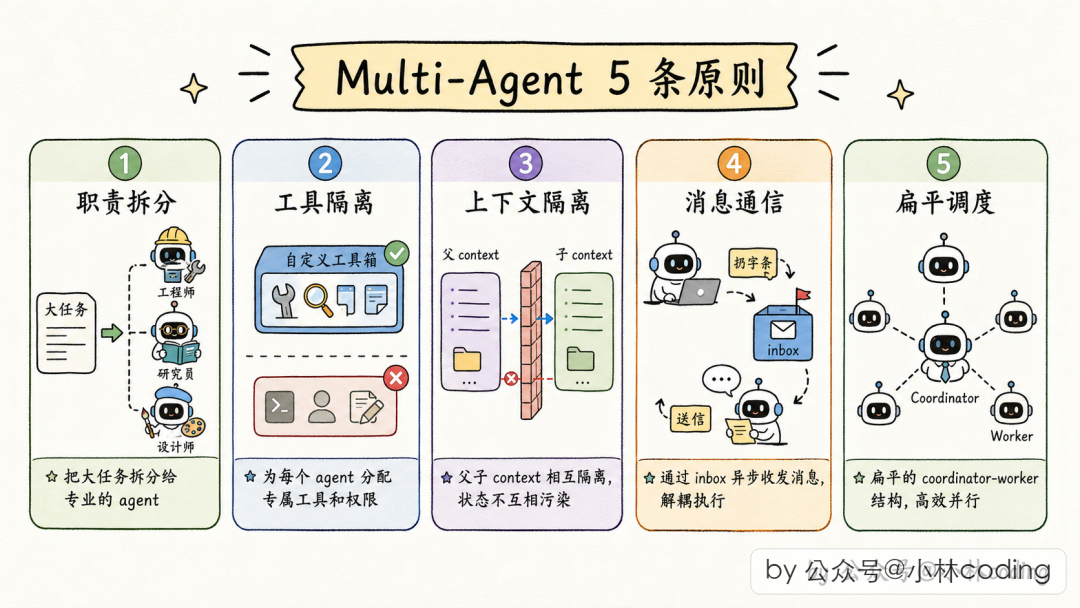
原则 1:上下文隔离要按字段粒度做
不要一刀切地"全隔离"或"不隔离"。对着父 Agent 的每项状态问一句"子 Agent 拿这个状态干啥?会不会影响父?",就能避开大部分坑。
原则 2:通信走消息,不走函数调用
父 → 子写消息队列,子 → 父用 XML 伪装用户消息。天然异步、天然支持并发、天然兼容 agentic loop。
原则 3:工具权限要分级管控
全局黑名单 → 类型黑名单 → 异步白名单。每种 Agent 按自己的场景配工具。
原则 4:缓存友好是一种架构能力
设计 Subagent 时考虑它的 prompt 前缀能否复用父 Agent 的缓存。严格的"字节级相同"原则和"复用父 Agent 已渲染字节"的思路,是这方面的教科书式实现。
原则 5:并行优先 + 协调者合成
通过异步消息做基础,通过协调者做合成。协调者要亲自合成,不能当传话筒。通过工具权限把层级限制在两层,避免失控的递归嵌套。
Claude Code 的 Multi-Agent 系统不是一个简单的"主 Agent 嵌几个 Subagent",它在架构、通信、并发、成本、隔离每一个维度都做了精致的设计。每一块拆开看都不是复杂技术,但组合在一起,就成了支撑 Anthropic 级别产品的工业级多 Agent 系统。
如果你在自建 Agent 系统,建议把这 5 条原则拿去做对照,每次看到 Multi-Agent 相关设计时都拿它们去衡量——会迅速看出对方系统的深浅。
本周 GitHub 热门开源项目速览:AI Agent 工具链、端侧 TTS 与代码理解
这一周的 GitHub 开源榜单精彩纷呈,AI Agent 工具链、代码理解、端侧语音合成全面开花。 从科研助手到论文流水线,从代码知识图谱到终端编程助手,从 Agent 开发原则到多 Agent 视频创作,本文带你逐一拆解这 10 个最值得关注的开源项目。
AI Agent 工具链三连发
01 给 AI 装一套科研全家桶
scientific-agent-skills 本周突破 2.5 万 Star 且仍在上涨。这是一套开箱即用的 Agent 技能包,覆盖科研、科学计算、工程、数据分析、金融及写作六大领域。
以往让 Claude 或 Cursor 做正经研究,它们经常东一榔头西一棒子——思路跳脱、流程不可控。装上这套技能包后,AI 的"干活姿势"规范得多,知道该按什么流程来推进问题。

02 写论文这事被做成了流水线
如果说 scientific-agent-skills 是科研全家桶,那 academic-research-skills 就是专门盯着写论文这一件事的特化版本。一周飙升一万多 Star,目前接近两万。
它专门为 Claude Code 定制了学术研究技能,把论文写作的全流程串成了一条自动化管线:
查资料 → 写初稿 → 同行评审 → 修改 → 定稿
一环扣一环自动往下走。流程设计明显是按真实学术写作节奏来的——不是随便拼几个 prompt,而是有结构化的质量控制环节。当然,它并非全自动,关键决策点仍需要人工介入。
代码理解的新范式
03 把陌生代码库变成一张地图
Understand-Anything 目前接近 2 万 Star。它能将任意代码库转换为可交互的知识图谱——你可以搜索、提问、可视化的方式探索代码结构。

读陌生项目之前,先让它给你画张地图,心里就有底了。它兼容多种 AI 工具,不挑食。如果你经常需要接手别人的代码,或者刚进新公司面对一堆历史遗留项目,这个工具能显著降低上手成本。
04 让 AI 一上来就懂你整个项目
本周黑马项目 codegraph,一周猛涨 1.4 万 Star,目前 1.8 万。痛点其实每个开发者都懂:每次让 AI 改代码,它都得先现啃一遍你的项目结构,又慢,还容易啃错地方。

codegraph 的思路很直接——提前将整个代码库索引成一张代码知识图谱,然后喂给 AI。它支持 Claude Code、Codex、Cursor、OpenCode 等主流工具。建好图之后,AI 一上来就对项目了如指掌,不需要每次重新摸索。
终端编程的新高度
05 终端里冒出的 AI 编程新势力
终端 AI 编程助手赛道如今卷得飞起。oh-my-pi 是本周比较亮眼的一个,目前 6000 多 Star。它跑在终端里,主打一个改代码改得准。

它从 Pi 分支出来,做了大量增强。最亮眼的是 Hashline 编辑系统——使用内容哈希锚点定位代码,无需重新输入整行,解决了空白符不匹配导致编辑失败的历史难题,据说能减少 61% 的 token 消耗。
来看看它的硬核配置:
- 1内置 32 个工具,涵盖文件操作、搜索、AST 操作等
- 2完整的 LSP 集成,支持 40+ 编程语言
- 3DAP 调试支持,终端内即可断点调试
- 4约 27,000 行 Rust 代码,将 ripgrep、glob、bash、AST 操作、语法高亮全部做进进程内
- 5支持 40+ LLM 提供商,14 种 Web 搜索后端
- 6可从 Claude Code、Cursor、Windsurf 等 8 个工具导入配置
天天泡在终端里写代码的,值得拿它跟手头的工具比一比。
Agent 开发的工程化思考
06 Agent 开发的十二条军规
老程序员应该都听过经典的 12-Factor App——构建云原生应用的十二条原则。12-factor-agents 就把这套工程化思路搬到了 AI Agent 开发上,目前 2.1 万 Star。
这 12 条原则覆盖了从工具调用、提示词管理、上下文控制到错误处理的完整链路:
项目附带三个实战工作坊和脚手架工具,跑一条命令就能初始化一个符合这些原则的新项目。如果你在做 AI Agent 开发,建议认真读一读。
07 从零开始手搓 AI 工程
跟上面那个互补——一个讲原则,这个带实操。ai-engineering-from-scratch 目前 1.2 万 Star,口号挺提气:学会它、造出来、发出去。
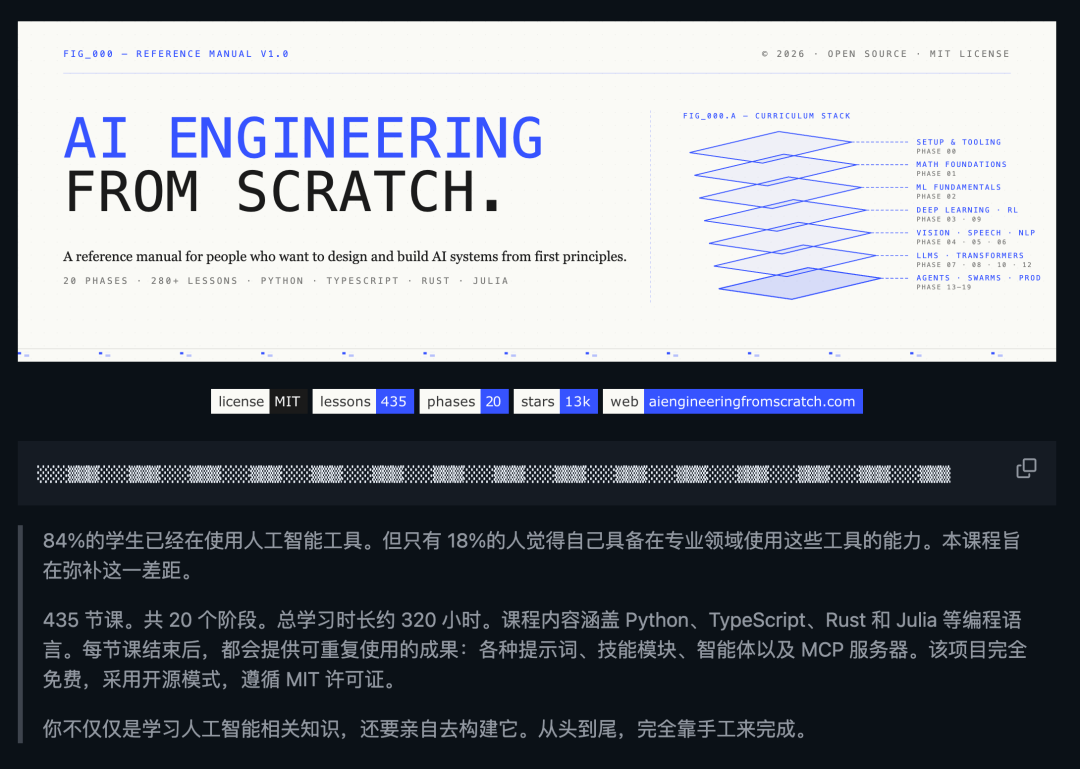
项目规模相当扎实:
| 维度 | 数据 |
|---|---|
| 课程总数 | 428 节课 |
| 学习阶段 | 20 个阶段 |
| 预计时长 | 约 320 小时 |
| 覆盖范围 | 从线性代数到自主多智能体系统 |
| 实现语言 | Python、TypeScript、Rust、Julia 四种 |
每节课结构统一:先讲问题 → 再讲概念 → 从数学原理自行实现 → 用 PyTorch/sklearn 再实现一遍 → 最后做成可交付的 AI 工件(Prompt、Skill、Agent 或 MCP Server)。
还附带一个水平测试系统,自动告诉你该从哪个阶段开始。
端侧 AI 与多媒体创作
08 不联网也能说话的端侧 TTS
Supertonic 是一个端侧文本转语音系统,约 99M 参数,在 CPU 上就能跑出实时速度。基于 ONNX Runtime 运行,完全离线,不把文本传到云端。
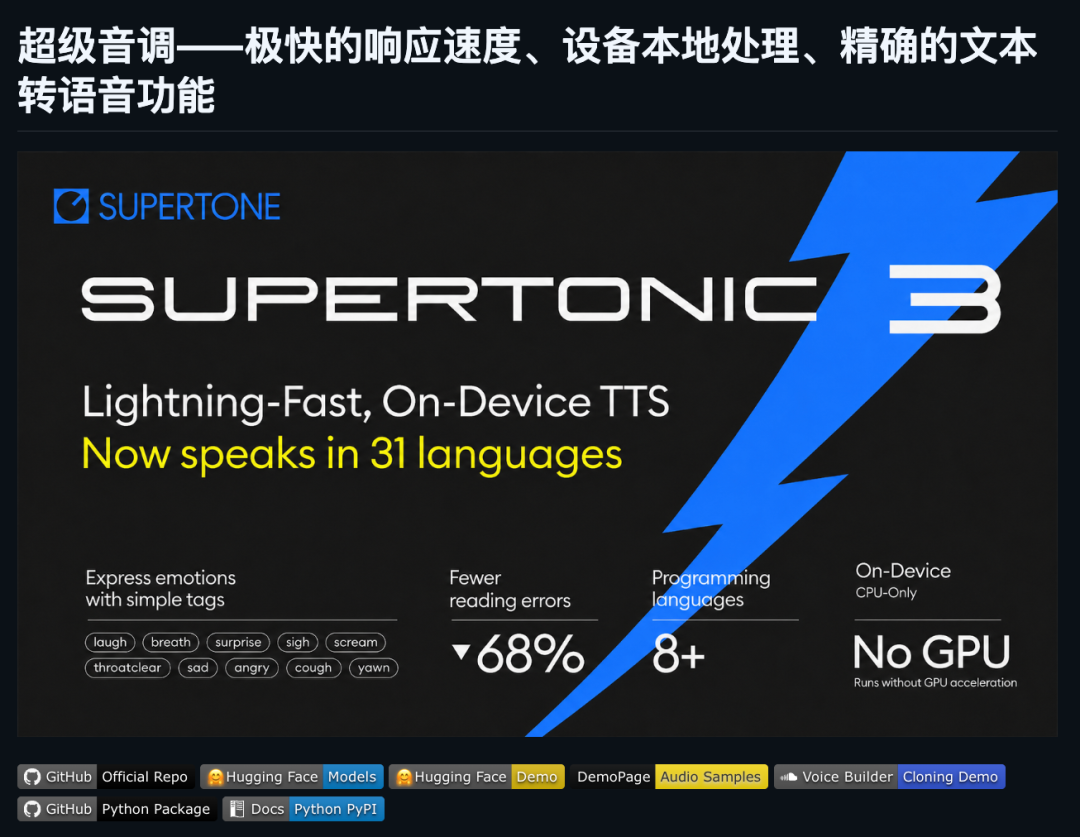
v3 版本支持 31 种语言,新增 Expression Tags 功能——可以用标签精确控制语音的情感表达。最方便的是它提供 11 个平台的 SDK:C++、Node.js、Python、Rust……基本你想在哪个平台上集成都能直接用。
09 把拍视频拆成一个 AI 剧组
港大数据智能实验室(HKUDS)出品的 ViMax 脑洞很大——把视频制作拆成导演、编剧、制片、视频生成器几个 AI 角色,组成一个 Agent 剧组,从剧本协作到成片。

支持三种输入模式:
| 模式 | 场景 |
|---|---|
| Idea2Video | 给个灵感就开搞 |
| Script2Video | 提供完整剧本 |
| Novel2Video | 甚至能把小说改成视频 |
还有个 AutoCameo 功能——上传你的照片就能把你作为角色嵌入视频,保持外观一致。技术上采用六层流水线,从输入解析到视觉合成全自动化,还模拟多机位拍摄,保持角色位置和背景的一致性。
这就是多 Agent 协作比较性感的形态——不是一个 AI 单打独斗,而是一群 AI 分工协作。
- 开源地址: github.com/HKUDS/ViMax
这一轮 GitHub 热门项目的变化其实透露了一个信号:AI 工具正在从 "能不能做" 走向 "做得好不好"。科研全家桶、论文流水线、代码知识图谱、精密编辑终端——这些项目的共同特征是:都在解决 AI 输出质量控制的问题。
未来几个月,值得密切关注这些项目的演进方向——它们很可能成为下一代开发工作流的基石组件。
📌 本文所有项目均可在 GitHub 上找到,链接已附。
Agent Skill 框架正在吃掉软件开发
前几天刷 GitHub Trending,看到了一组不太真实的数字。
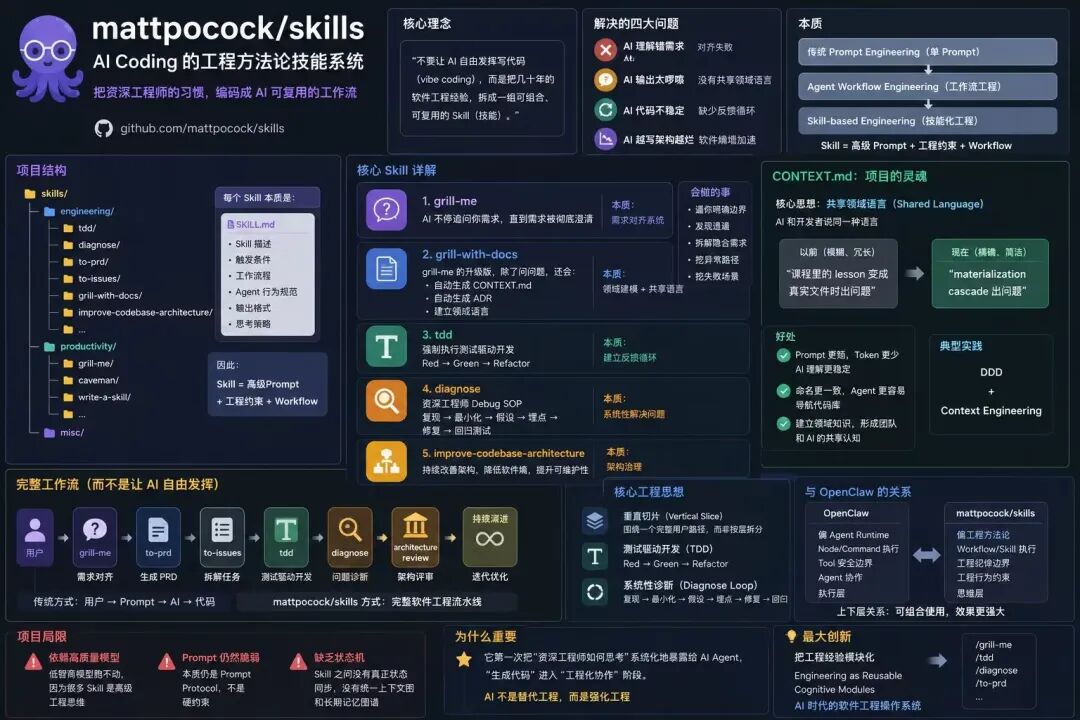
mattpocock/skills,一个仓库,78,943 颗星,单日涨了 3,392 颗。
81K 星什么概念?React 是 236K 星,Vue 是 216K 星。而 pocock 这个仓库,本质上就是一些文本文件——几个 markdown,外加一些 shell 脚本。
这比 90% 的开源框架都高了。
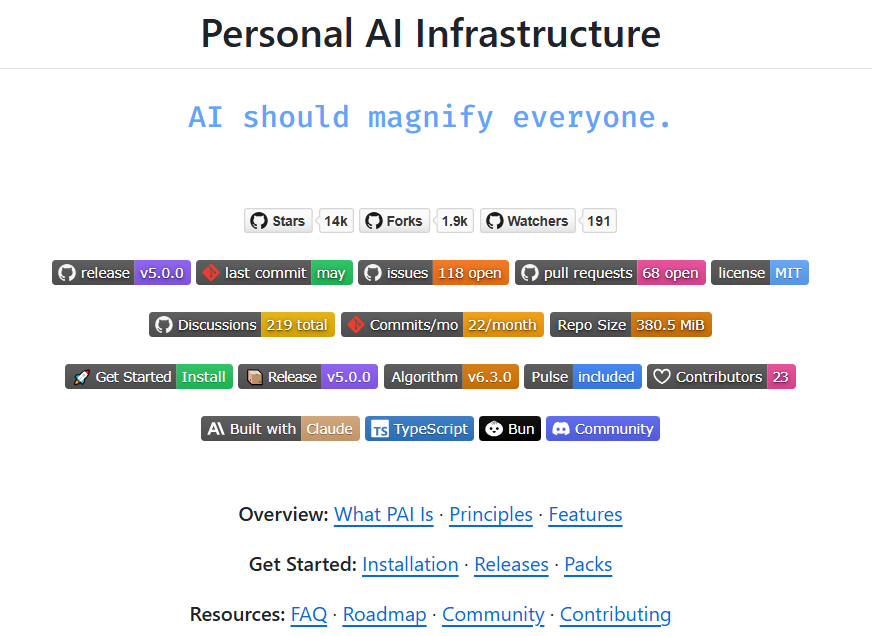
不只 pocock。同一天,obra/superpowers 也在趋势榜上——一个 agentic skills framework。agentmemory 一天涨了 1,978 颗星,号称"基于真实世界基准的 #1 Agent 记忆方案"。danielmiessler 的 Personal AI Infrastructure,14K 星。
不是一个项目。是同一个时间点,好几个。
我盯着这些数字看了很久。一个问题反复出现:为什么是现在?
一、Agent Skills 到底是什么
说白了,Agent Skills 就是给 AI Coding Agent 用的"说明书"。
你现在让 Claude Code 或者 Cursor 写代码,它靠什么理解你的项目?靠 CLAUDE.md、靠 .cursorrules、靠你上下文里塞的 prompt。这些本质都是 skills——只不过是你自己写的。
pocock、obra、danielmiessler 他们做的事则是:把常用的 skill 标准化、可复用、可共享。
pocock 的 skills 库里有什么?比如"用 TypeScript 写类型安全的 API"“处理 React 状态管理"“写可测试的单元测试”。每一段都是他从自己的 CLAUDE.md 里抽象出来的。

obra 的 superpowers 更进一步——它不仅定义了 skills,还定义了一套"如何用 skills 做软件工程"的完整方法论。

二、像极了 2015 年的 npm
2015 年 Node.js 爆发后,npm 的包数量从 2014 年的 50K 飙升到 2016 年的 300K。不是因为那一年突然多出了 250K 个新需求,而是因为开发者开始把过去"写在本地 helper.js 里"的东西,抽成了可复用的包。
生态一旦启动,正反馈就来了——包越多 → 开发越快 → 更多人加入 → 更多包。
Agent Skills 现在正在经历完全一样的事情。
之前大家用 AI 写代码,都是自己手搓 CLAUDE.md。开发者在论坛和 Twitter 上晒自己的规则文件,互相学习,但那都是"点对点"的分享。pocock 做了一个关键动作:他把这个过程标准化了。 不再是你去他的帖子下面问"能不能把你的 CLAUDE.md 给我看看”,而是直接把整个仓库 clone 下来,放到你的 .claude 目录里就能用。
从"分享文本"到"分享制品"——这一步,就是生态的起点。
三、为什么是 pocock?为什么是现在?
pocock 不是一个"技术布道师",他是个真正的程序员——TypeScript 社区最有影响力的开发者之一,Total TypeScript 的创建者。
他的 skills 之所以能炸,有个关键原因:这些 skills 是他自己每天都在用的东西。
他之前在推上说过:现在他已经很少"手写"代码了,大多数 PR 都是 Claude Code 完成的。发现 Claude 犯错了?加一条规则。迭代了上百次,就成了这个仓库。
这和 Boris Cherny(Claude Code 创建者)的逻辑完全一致。Boris 分享过他们团队的做法:CLAUDE.md 放进 git 仓库,团队每周都在往里面加东西。核心机制就一条——每当看到 Claude 做错了什么,就加到 CLAUDE.md 里。
有一个飞轮在运转:
这个飞轮一旦跑起来,停不住。
四、Skills 生态的格局
我梳理了一下目前 Agent Skills 领域的玩家,格局已经很清晰了:
| 层级 | 代表项目 | 定位 |
|---|---|---|
| 框架层 | obra/superpowers | 定义"怎么用 skills 做软件工程"的方法论 |
| 库层 | mattpocock/skills, K-Dense-AI/scientific-agent-skills | 即插即用的 skill 集合 |
| 基础设施层 | agentmemory, danielmiessler/Personal_AI_Infrastructure | 持久化记忆、Agent 运行基础设施 |
| 市场层 | 尚未出现 | Agent Skills 的 npmjs.com 在哪里? |
框架层
obra/superpowers 不是给你一堆积木,而是给你一套"怎么搭积木"的方法论。它的野心更大,它想做 Agent 时代的软件工程标准。从需求、设计、实现、测试到部署,一整条流水线都定义了。
库层
mattpocock/skills 偏 TypeScript 和前端,K-Dense/scientific-agent-skills 偏科研和数据分析。未来会出现各种垂直领域的 skills 库——游戏开发、嵌入式、区块链,你能想到的方向都是机会。
基础设施层
这是最底层。让 Skills 这个生态能跑起来的前提是:Agent 能记住、能组织、能调用这些 skills。 agentmemory 做持久化记忆,Personal_AI_Infrastructure 做 Agent 运行基础设施。
市场层(最大的机会)
npm 有 npmjs.com,Python 有 PyPI,Agent Skills 的"官方市场"在哪里?目前最接近的是 clawhub(我现在装 skills 用的就是它),但它还远没有成为基础设施。
这和 npm 的剧本一样。2015 年不是没有比 npm 更好的包管理器,但 npm 已经在 Node.js 里预装了,所以它赢了。
现在 Agent Skills 的"预装渠道"就是 Cursor、Claude Code、Windsurf 这些 AI IDE。谁先进入它们的默认推荐列表,谁就拿到了当年 npm 的那个位置。
五、我的几点看法
作为一个创业公司 Agent 产品的深度参与者(从 HAMi 算力调度到 Agent 工作流编排,再到手头的 AIOps Agent 平台),这个趋势我有些切身体会想分享。
第一,Skills 解决了 AI 编程最核心的痛点:犯错重复化。
用 Claude Code 写一段时间代码后,你一定会发现它反复犯同样的错误——同样的类型错误、同样的架构偏差、同样的忽略边界条件。每次你都得在 prompt 里重新强调。Skills 的本质就是把这些"教训"变成可复用的工件,一个团队积累,所有人受益。
第二,CLAUDE.md 是起点,但不是终点。
pocock 的仓库之所以爆炸,不只是因为他写了好的 CLAUDE.md,而是因为他把 CLAUDE.md 做成了可安装的模块。这个转变看起来小,实际上是个范式转移。就像从"复制粘贴 lodash 的函数"到"npm install lodash"——同样的功能,安装体验的改变带来了整个生态。
第三,对平台团队来说,Skills 是新的治理层次。
我在做 AIOps 平台时,团队内部也在做类似的事:把运维专家的知识编码成可复用的"skill",Agent 在执行运维操作时自动调用。比如 K8s 集群故障诊断 skill、GPU 健康检查 skill、日志归因分析 skill。这些 skill 的价值在于:它们让 Agent 在特定场景下的表现,从"随机正确"变成了"确定性可靠"。
六、这对你意味着什么
如果你还在手写 CLAUDE.md,把 skills 当成"锦上添花"——可能该重新评估了。
不是所有 skills 都值得用。pocock 的 TypeScript skills 可能跟你的项目不搭。但思路是一样的:把你和 Agent 协作的经验,变成可复用的知识。
这不只是为了"节省时间"。而是因为:你每让 Agent 犯一个你以前犯过的错,就是在浪费上下文窗口。
而标准化的 Agent Skills 生态一旦成熟,那些没有积累自己 skill 库的开发者,就会像 2015 年还在手写 jQuery 插件的人一样——技术上不算落后,但效率差了两个数量级。
AI 可以替我写,但不能替我想。但标准化 skill 可以替你积累,却不能替你判断。选哪些 skill 用、不用哪些 skill、自己写什么 skill——这些判断永远是你自己的。
这个领域变化太快了。pocock 的仓库今天可能已经破 8 万星了,下周可能就破 10 万。我自己的写作工作流也已经是一组高度定制的 skills 在协作——每天自动抓取新闻、改写、配图、发布,全流程 Agent 完成。
如果你也在用 Agent Skills,欢迎告诉我:你的 CLAUDE.md 里放了什么?你装了哪些 skills?哪些是真的好用的?
延伸阅读:
· mattpocock/skills
· obra/superpowers
· agentmemory
· Personal AI Infrastructure
新网银行"智擎AI+"战略升级:10类数字员工、77个智能助手如何落地?
近日,新网银行发布 2025 年年度报告,最引人注目的并非传统的财务数据,而是其"智擎 AI+“战略的落地成果——10 类数字员工、77 个智能助手、日均百万级 API 调用。这组数据意味着,AI 已经不再只是银行后台的辅助工具,而是直接嵌入到了从客户触达到风险决策的每一个业务环节。
从试点到全员覆盖:AI 能力的三年演进
新网银行的 AI 之路清晰地分为三个阶段:
这种演进路径并非特立独行,但它从试点到全员覆盖的推进速度值得关注。2024 年还只是围绕十余项业务痛点做小范围试点,到了 2025 年,已经形成了覆盖客户触达、风险评估、内部办公等领域的智能化应用矩阵。
算力底座:异构融合的 AI 云基础设施
支撑规模化 AI 应用的,是一套扎实的底层基础设施。新网银行打造了异构融合的 AI 云算力底座,技术选型上选择了容器化 + 算力池化的路线:
如果你关注过 AI Infra 领域,会意识到这背后的技术难度——异构算力的池化管理、热力图监控、动态调度,这些都和 Kubernetes 生态的 GPU 管理能力密切相关。30% 的利用率提升在金融级生产环境中是一个相当不错的成绩。
数字员工矩阵:10 类 + 77 个智能助手
“数字员工"和"智能助手"这两个概念,代表了不同的 AI 应用形态:
智能助手:嵌入具体业务场景的 AI 能力单元,辅助人类员工完成特定操作。
两者构成了一个能力分层体系——数字员工负责流程闭环,智能助手负责能力点支撑。
应用场景覆盖
| 业务领域 | AI 应用形态 | 核心能力 |
|---|---|---|
| 客户服务 | 大小模型结合的智能客服 | 小模型处理标准化问题,大模型处理复杂语义 |
| 风险决策 | 大模型风险特征解析 | 非结构化数据挖掘,隐性关联关系识别 |
| 内部运营 | 10 余个大模型助手 | 编码、测试用例生成、研发提效 |
| 贷后管理 | AI Agent 自动化流程 | 文件识别、信息抽取、系统录入 |
| 安全态势 | 大模型检索分析 | 多源数据融合,风险早发现早预防 |
查冻扣场景的智能体实践
一个值得深入的技术案例是查冻扣文件识别场景。在这个场景中,新网银行构建了由 AI Agent 驱动的完整信息抽取流程:
- 1视觉识别:计算机视觉模型识别保护性止付、涉案止付、财产查询、财产冻结解冻四类文件
- 2语义理解:大模型提取结构化信息,覆盖文书类型、涉案主体、涉及金额、处置方式等 13 类信息
- 3系统录入:AI Agent 将信息录入核心系统,对名单人员进行分级管控
- 4数据同步:信息同步至数仓形成报表,便于统计分析
据新网银行副行长李秀生透露,大模型细分识别查冻扣文件中的嫌疑人、受害人准确率达 100%,而且文件中涉及的非本行客户也会录入系统,确保可在后续服务时提前预判风险。
金融科技人才战略
AI 战略的落地离不开人才。新网银行首席信息官毛航的人才理念很务实:
在具体执行层面,新网银行正开展金融科技及风险专项培训生计划,定向培养兼具金融业务理解与技术研发能力的复合型科技人才,参与人工智能、大模型、大数据等金融场景的落地。
专利与技术储备
2025 年,新网银行围绕 AI 技术申报了 13 件发明专利和 6 件软件著作权,其中几个值得关注:
| 专利名称 | 技术方向 |
|---|---|
| 基于智能体工作流的影像文件信息自动化抽取方法与系统 | AI Agent + 视觉识别 |
| 一种基于大模型的银行智能客服问答方法及系统 | 大模型 + 客服 |
| 一种提高大模型多轮对话可控性和可解释性的方法及系统 | 大模型可控生成 |
其中,“基于智能体工作流的影像文件信息自动化抽取方法与系统"这套方案的技术亮点在于——依托视觉模型的高精度文字识别能力,结合 AI Agent 大模型的知识泛化能力,在无需标注数据的情况下实现高效、准确的信息抽取,同时智能体还能根据任务需求动态优化抽取过程。
写在最后
新网银行的案例展示了一条清晰的路径:算力底座 → 数字员工 → 智能体平台 → 全员覆盖。
日均百万级 API 调用的背后,是 AI 从"锦上添花"到"核心生产力"的角色跃迁。对于同样在探索 AI 转型的金融机构而言,这组数据既是一张成绩单,也是一张路线图。
本文信息来源于新网银行 2025 年年度报告及相关公开报道。
更多内容请访问 jungelife.me
Markdown → HTML:AI 输出正在从"文档"进化成"界面"
过去几年,Markdown 几乎成了 AI Agent 的"标配"。不管是 ChatGPT、Claude、Cursor 还是 Copilot,默认输出格式都是 # 标题、- 列表、`代码`。
但最近,Claude Code 团队的工程师 Thariq Shihipar(@trq212)发了一篇长文,提出了一个很有冲击力的观点:
Markdown 已经越来越限制 Agent 的表达能力。HTML 才是 Agent 时代人与 AI 协作的更优格式。
他甚至说,Claude Code 团队的人已经开始集体转向 HTML 了。

这听起来有点反直觉。Markdown 用了这么多年,怎么说换就换?但仔细读下去,你会发现一个关键前提正在发生变化——而这个变化,可能会重新定义 AI 时代"文档"的含义。
一、Markdown 为什么突然"不够用了"
这不是 Markdown 变差了。而是 Agent 变强了。
过去的 AI 只能回答问题、写段文字、输出个表格——Markdown 足够。但现在的 Claude、GPT-5.5 已经开始:
- 1 读取整个代码库
- 2 做系统设计
- 3 写 PR Review
- 4 生成架构图
- 5 做产品方案
- 6 生成交互原型
- 7 分析 Git 历史
- 8 理解 Slack / Linear / MCP
问题来了:这些复杂信息,最后却被塞进 Markdown 里——用 ## Architecture 做标题,用 User -> API -> Queue -> Worker 做架构图,甚至用 ████░░░░░ 这种 ASCII 图来表达进度。
这本质上其实就是:AI 的表达能力,已经超过 Markdown 这个"容器"了。 就像把一辆跑车塞进自行车道——不是车不行,是路太窄。
二、一个关键前提正在变化
Thariq 在文章里提到一句很关键的话:
这是整个事情的核心。
过去:
- 人类写 Markdown
- 人类改 Markdown
- 人类维护 Markdown
所以"易编辑"是核心优势。
但现在:
- Claude 写
- Agent 改
- AI 维护
- 人类更多只是阅读和决策
Markdown 最大的优势——“易编辑”——其实正在消失。
三、HTML 真正强的,不是"网页"
很多人看到 HTML 会下意识想到:前端、浏览器、网页开发。但这次大家重新看待 HTML,其实是因为:HTML 是目前最强的"信息表达协议"。
它天然拥有:
| 能力 | 实现方式 |
|---|---|
| 布局 | CSS Flexbox、Grid、绝对定位 |
| 颜色 | 真正的色值(#FF5733),不是 Unicode 模拟 |
| 动画 | CSS 动画、Transition |
| 矢量图 | SVG,矢量图表、流程图、架构图 |
| 画布 | Canvas 2D/3D 绘图,数据可视化 |
| 表格 | 真正的数据表格,不是 ASCII 画线 |
| 响应式 | 移动端自适应 |
| 交互 | JavaScript 交互、调参、实时预览 |
| 图片 | <img> 标签直接嵌入 |
这意味着:Agent 输出的,不再只是"文档",而是一个轻量级应用(Mini App)。

四、HTML 的六大核心优势
Thariq 把 HTML 的优势拆解得很清楚:

1. 信息密度爆炸
HTML 能承载表格、CSS、SVG、Canvas、JS 交互——几乎 Claude 能理解的任何信息都能高效呈现。不用再忍受 Unicode 模拟颜色或 ASCII 图的尴尬。
2. 可读性大幅提升
Thariq 的原话:"超过 100 行的 Markdown 我基本不看了。"
但 HTML 可以:标签页切换、SVG 插图、可折叠模块、双栏布局、响应式适配——长文档也能轻松读完。
3. 分享极度方便
Markdown 只能当附件发,对方还要找工具打开。HTML 上传 S3 后直接发链接,浏览器原生打开。“别人真正去阅读的概率会大幅提升。”
4. 双向交互能力
Markdown 完全做不到:滑块调参、拖拽排序、实时预览、一键"Copy as Prompt"贴回 Claude Code。HTML 是动态编辑界面,真正实现人机闭环协作。
5. 数据摄入更强
Claude Code 能读取代码库、Slack、Linear、Git 历史等多源上下文,直接生成结构化 HTML 报告。
6. 愉悦感
“用 Claude 做 HTML 本身就是一件极其好玩的事。“更有参与感,更有创造感。
五、HTML 也有一堆问题
Thariq 没有一味吹捧,很诚实地列出了 HTML 路线的缺点:
| 问题 | 说明 | 现状 |
|---|---|---|
| 生成更慢 | HTML 可能是 Markdown 的 2-4 倍 | 作者认为值得等待 |
| Token 更贵 | HTML + CSS + SVG + JS,整体更长 | 1M 上下文窗口下几乎可忽略 |
| 版本控制 | HTML diff 极其嘈杂 | 最大短板 |
| 审美风险 | 容易过度动画、UI 混乱、信息过载 | 需要 Design System |
关于版本控制,Thariq 说这是 “honestly one of the biggest downsides”。Markdown diff 一目了然(+ add section),HTML diff 却是 + <div class="flex gap-2 px-4">,可读性差很多。
关于审美,他的解决方案是:先让 Claude 扫描你的代码库,生成一个专属的 Design System HTML 文件,之后把这个文件作为参考资料丢给 Claude,让它在生成其他 HTML 页面时"照猫画虎”,保持风格高度一致。
六、真正重要的变化:从"文档"到"界面”
很多人容易误解成 “HTML vs Markdown” 的格式之争。但其实不是。
真正的变化是:AI 输出,正在从"文本"进化成"界面"。
过去:
Agent → 文档(Markdown)→ 人类
未来:
Agent → 可交互 Artifact(HTML)→ 人类
这本质上是:“软件界面生成"正在替代"文档生成”。
而 HTML,刚好是今天最成熟、最通用、最低成本的运行时——浏览器是全球最大的 Runtime。
七、Markdown 不会死,但会退化成"源码层"
Thariq 说他"几乎完全不用 Markdown 了",但这不代表 Markdown 会消失。更可能的未来是分层:
| 层级 | 格式 | 角色 |
|---|---|---|
| AI 展示层 | HTML | 最终阅读/交互界面 |
| AI 交互层 | HTML + JS | 调参、编辑、预览 |
| 数据层 | JSON / YAML | 结构化数据 |
| 存储层 | Markdown / Plain Text | 中间格式、Git 友好 |
Markdown 会越来越像 .md、.txt、.yaml——中间数据格式,而不是最终阅读格式。
就像 JSX 不再是最终 UI、AST 不再给人看、SQL 不是最终产品——Markdown 可能也会变成 Agent 内部通信格式。
真正给人看的:会越来越 HTML 化。
这篇讨论的不是 HTML 和 Markdown 谁更好,而是 AI 时代"输出"的定义正在被重写。
当 Agent 生成的不再是文本,而是界面时,
我们需要一个能承载这个新定义的格式。
而 HTML,恰好就是那个已经跑在每一个设备上的运行时。
参考链接
Thariq 原文 · 20 个 HTML 示例集合 · Simon Willison 转载
Kubernetes GPU 虚拟化实战:HAMi DRA 模式完整指南
一块 A10 24GB 显存的 GPU,在传统模式下只能给一个 Pod 用。但如果跑的是 batch 推理任务,很可能只用到了 10GB 显存和 30% 算力——剩下 14GB 就这么空着。
如果能把一块物理 GPU 按显存和算力细粒度地切分,让多个 Pod 共享呢?
这就是 HAMi 要解决的问题。
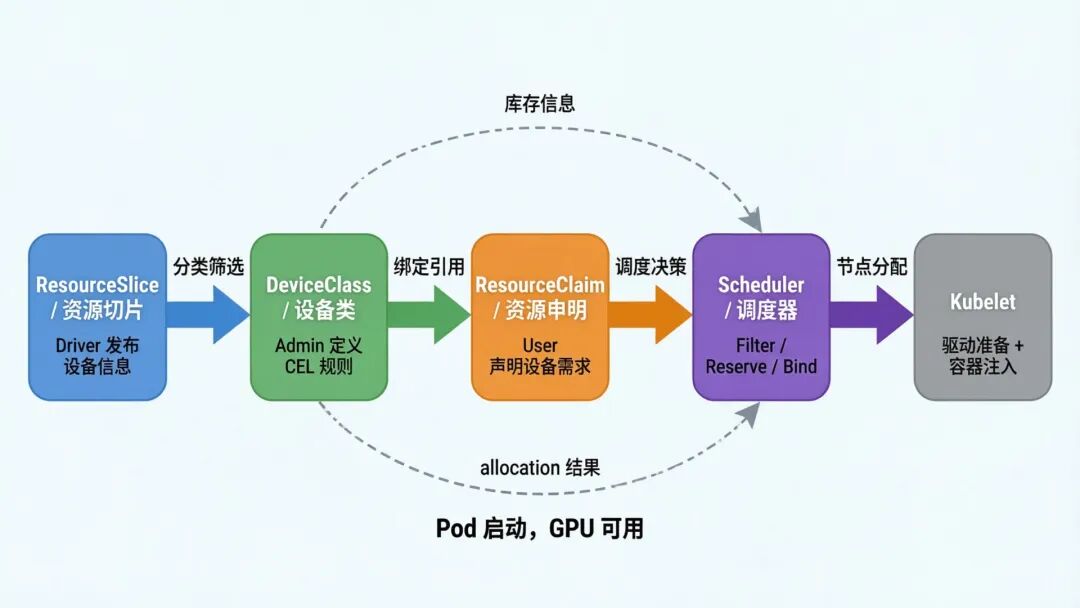
本文聚焦 HAMi DRA 模式的部署与使用。Kubernetes 在 1.34 中正式 GA 了 DRA(Dynamic Resource Allocation),让调度器参与资源分配,在 Pod 调度阶段就精确匹配设备属性。HAMi 的 2.9 版本已经正式接入了 DRA。
什么是 HAMi
HAMi(异构 AI 计算虚拟化中间件)是一个用于管理 Kubernetes 集群中异构 AI 计算设备的开源平台,前身为 k8s-vGPU-scheduler。
核心能力
| 能力 | 说明 |
|---|---|
| 多设备支持 | 兼容多种异构 AI 计算设备(GPU、NPU 等) |
| 共享访问 | 多个容器可同时共享设备,提高资源利用率 |
| 硬限制 | 在容器内强制执行严格的内存限制,防止资源冲突 |
| 动态分配 | 根据工作负载需求按需分配设备内存 |
| 灵活单位 | 支持按 MB 或占总设备内存百分比的方式指定内存分配 |
| 类型选择 | 可请求特定类型的异构 AI 计算设备 |
| UUID 定向 | 使用设备 UUID 精确指定特定设备 |
| 工作负载透明 | 容器内无需修改代码 |
| 简单部署 | 使用 Helm 轻松安装和卸载 |
| 社区驱动 | 由互联网、金融、制造业、云服务等多领域组织联合发起 |
DRA 模式的两条路径
DRA 的核心改进在于:调度器在 Pod 调度阶段就能精确匹配设备属性,避免了 DevicePlugin"调度到节点后才发现资源不够"的问题。
HAMi DRA 提供了两种使用模式:
| 模式 | ResourceClaim 创建 | 适用场景 |
|---|---|---|
| 原生 DRA 模式 | 手动创建 ResourceClaim | 新业务,精细化控制 |
| DevicePlugin 兼容模式 | Webhook 自动转换 | 存量业务零改造迁移 |
两种模式的底层调度与切分逻辑完全一致,差异仅在于 ResourceClaim 的创建方式。
环境要求
| 要求 | 说明 |
|---|---|
| Kubernetes | 1.34+,需开启 DRAConsumableCapacity Feature Gate |
| Container Runtime | 必须开启 CDI |
| NVIDIA 驱动 | 440 及以上版本 |
⚠️ 特别注意:
DRAConsumableCapacity在 1.36 才默认开启,1.34、1.35 需手动配置 Feature Gate。
HAMi 安装
第一步:安装 GPU Operator(关闭 DevicePlugin)
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
helm upgrade --install --wait gpu-operator \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v26.3.1 \
--set driver.enabled=true \
--set devicePlugin.enabled=false
关键参数 --set devicePlugin.enabled=false:关闭 DevicePlugin,避免与后续安装的 DRA Driver 冲突。
第二步:安装 cert-manager
HAMi DRA Webhook 需要 TLS 证书,因此需要提前安装 cert-manager 用于自动签发。
helm repo add cert-manager https://charts.jetstack.io
helm repo update
helm install cert-manager cert-manager/cert-manager \
-n cert-manager --create-namespace \
--set crds.enabled=true
第三步:Helm 安装 HAMi
先为节点打标签,未标记的节点不会被 HAMi 接管:
kubectl label nodes {nodeid} gpu=on
然后安装 HAMi:
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm -n hami-system install hami hami-charts/hami \
--set dra.enabled=true \
--create-namespace
⚠️ 注意:DRA 模式与传统模式不兼容,请勿同时启用。如果 GPU 驱动是主机预装(非 GPU Operator 安装),则需额外指定
--set hami-dra.drivers.nvidia.containerDriver=false。
验证安装
正常情况下,会在 hami-system 命名空间下启动以下 Pod:
NAME READY STATUS RESTARTS AGE
hami-dra-driver-kubelet-plugin-hflbh 1/1 Running 0 2m49s
hami-hami-dra-monitor-7b484d5f95-rlkcg 1/1 Running 0 22m
hami-hami-dra-webhook-64bfdc6b86-d4nlr 1/1 Running 0 22m
查看 ResourceSlice 确认 dra-driver 正常发布资源:
kubectl get resourceslice

ResourceSlice 的详情中记录了 GPU 的架构、型号、显存等信息,用 -oyaml 查看完整字段:
apiVersion: resource.k8s.io/v1
kind: ResourceSlice
metadata:
name: ecs-a10-sh-hami-core-gpu.project-hami.io-hnn6d
spec:
devices:
- attributes:
architecture:
string: Ampere
brand:
string: Nvidia
productName:
string: NVIDIA A10
cudaComputeCapability:
version: 8.6.0
driverVersion:
version: 550.144.3
type:
string: hami-gpu
uuid:
string: GPU-f1c7d08c-ae21-13e7-0de0-9eb14ff71eaf
capacity:
cores:
value: "100"
memory:
value: 23028Mi
name: hami-gpu-0
driver: hami-core-gpu.project-hami.io
nodeName: ecs-a10-sh
使用:两种模式实战
原生 DRA 模式
先创建 ResourceClaim 声明资源需求,再创建 Pod 引用该 Claim:
# 申请 10G 显存 + 50 cores 的 A10 GPU
apiVersion: resource.k8s.io/v1
kind: ResourceClaim
metadata:
name: gpu-half-claim
spec:
devices:
requests:
- name: gpu
exactly:
deviceClassName: hami-core-gpu.project-hami.io
allocationMode: ExactCount
count: 1
capacity:
requests:
cores: 50
memory: "10Gi"
---
apiVersion: v1
kind: Pod
metadata:
name: gpu-test-dra-native
spec:
containers:
- name: cuda
image: nvidia/cuda:13.0.1-base-ubi9
command: ["sleep", "3600"]
resources:
claims:
- name: gpu
resourceClaims:
- name: gpu
resourceClaimName: gpu-half-claim
restartPolicy: Never
查看 ResourceClaim 的分配状态:
kubectl get resourceclaim gpu-half-claim -oyaml
关键输出:
status:
allocation:
devices:
results:
- consumedCapacity:
cores: "50"
memory: 10Gi
device: hami-gpu-0
driver: hami-core-gpu.project-hami.io
pool: ecs-a10-sh
request: gpu
shareID: 6108e68f-a7ec-4a30-9782-634885c0c728
进入 Pod 执行 nvidia-smi,可以看到显存限制为我们申请的 10G:
显存从物理的 23028Mi 限制到了申请的 10240Mi——HAMi 生效了。
DevicePlugin 兼容模式
原生 DRA 模式需要手动创建 ResourceClaim,对存量业务不够友好。为了便于迁移,HAMi 提供了兼容模式:
用户仍然像传统方式在 resources 中申请资源,由 HAMi DRA Webhook 自动拦截并转换为 ResourceClaim。
# 申请 1 块 GPU,10Gi 显存 + 50% 算力
apiVersion: v1
kind: Pod
metadata:
name: gpu-test-compatible
spec:
containers:
- name: cuda
image: nvidia/cuda:13.0.1-base-ubi9
command: ["sleep", "3600"]
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 10240
nvidia.com/gpucores: 50
restartPolicy: Never
HAMi 会根据 nvidia.com/gpumem、nvidia.com/gpucores 自动生成 ResourceClaim:
kubectl get resourceclaim
NAME STATE AGE
default-gpu-test-compatible-cuda allocated,reserved 2m47s
Webhook 转换的映射关系:
| Pod 配置 | ResourceClaim 中的值 |
|---|---|
nvidia.com/gpu: 1 | count: 1, 选择器 type == "hami-gpu" |
nvidia.com/gpumem: 10240 | memory: "10737418240" (10Gi 的字节值) |
nvidia.com/gpucores: 50 | cores: "50" |
Pod 中执行 nvidia-smi,同样验证显存限制生效:
兼容模式也正常生效了,存量业务零改造即可迁移。
小结
对于已在用 DevicePlugin 方式的存量业务,兼容模式提供了零改造的迁移路径,只需安装 HAMi DRA 后,原有的 GPU 资源申请方式就能自动转换为 DRA 模式运行。
对于新业务,原生 DRA 模式提供了更精细化的控制能力,可以在 ResourceClaim 中精确指定显存、算力甚至特定 GPU UUID。
云原生 Agent 托管的高效范式:Agent Harness Infra 体系化设计
随着 AI Agent 从概念验证走向生产落地,一个关键问题浮出水面——Agent 应该跑在什么基础设施上?
传统的虚拟机或容器能跑 Agent,但效率、成本和安全性都不理想。冷启动慢,长任务容易中断,安全隔离难以保障。
华为云在这方面的实践值得关注。他们的 Agent Harness 方案从容量预测调度、架构解耦、轻量级虚拟化三个维度给出了系统性的答案。
一、Agent Harness 面向云原生托管的落地挑战
当前 Agent Harness 在面向云原生托管架构落地过程中,主要面临三个维度的核心挑战:
挑战一:冷启动延迟与资源浪费
传统虚拟机或容器的启动往往需要数秒时间,难以满足 AI 交互场景对实时性的严苛要求。用户等待时间被拉长,体验明显受影响。
为了降低延迟,不少系统采用预留"热池"的方式,但这又导致资源利用率在闲时极低,资源浪费严重。突发流量来临时,性能表现也不够稳定。
挑战二:稳定性与成本控制
问题主要体现在上下文窗口的有限性与状态执行的脆弱性上。由于上下文窗口存在上限,任务运行时间较长时容易出现"遗忘"或崩溃现象。
一旦沙箱发生故障,正在执行的任务便会直接终止,长任务因此中断且无法恢复,进而引发记忆混乱、运维负担加重以及成本失控等问题。
挑战三:安全隔离
大语言模型生成的代码本身不可信,存在逃逸的潜在威胁。如果凭据与可执行代码同处一个沙箱环境中,提示词注入攻击便可能导致密钥泄露,进而引发系统被破坏、数据泄露、跳板攻击以及权限越级滥用等严重后果。
二、面向云原生托管 Agent Harness Infrastructure 的设计
Agent 沙箱并行规划与调度
通过采用容量预测技术,对 Agent 资源进行精准画像与预热管理。与传统基于时序的算法相比,该模型的效果相当可观:
| 指标 | 提升幅度 |
|---|---|
| 拟合精准度 | 提升 30% |
| 资源碎片率 | 降低 25% |
| 资源利用率 | 提高 10% |
在并行调度方面,系统基于资源碎片率、资源余量和预热分配量三个维度的因素,采用分片并行调度机制,使调度吞吐量显著提升至原来的 5 倍。在生态方面,该项目在 CNCF 社区内主导了 Volcano 沙箱调度器生态的建设,吸引了超过 200 家公司参与。
Agent 协调层和执行层架构解耦
采纳轻量级虚拟化技术(microVM),将 Agent Harness 协调层与 Sandbox 执行层彻底解耦,支持 Serverless 按需模式,配置合理的闲置超时回收策略。
通过 SessionID 保证多轮对话路由到同一实例维持状态,并将会话日志外置持久化。Harness 故障后,新实例可重放日志恢复任务,实现**“断点续传”**。
microVM 级安全隔离
使用 microVM 级 VMM(CloudHypervisor),最小化设备集和每 VM 进程开销(3-13MiB 量级)。在单节点数千并发沙箱规模下,通过 microVM、定制 Guest 环境和动态资源控制,实现 VM 级安全隔离与高密度的兼得。
强制隔离 Harness 与 Sandbox,实施最小权限原则与凭据托管。
羽量级虚拟化:ContainerOS + On-the-fly OS
华为云针对 Agent 与容器场景进行了极致优化,构建了由**“基础操作系统 ContainerOS + 动态生成操作系统 On-the-fly OS”** 相结合的组合方案,实现羽量级虚拟化。
| 特性 | 指标 |
|---|---|
| 启动时间 | 秒级 |
| 空载内存占用 | < 50MB |
| 根文件系统 | 只读(不可变基础设施) |
| 升级方式 | 镜像级原子化升级/回滚 |
ContainerOS 仅包含运行容器所必需的基础服务,On-the-fly OS 根据 Agent 运行需求增量构建。作为不可变基础设施,根文件系统为只读,以镜像为粒度进行原子化的升级与回滚。
极速启动优化
通过对 Sandbox 依赖资源及关键流程的预置,系统在计算、网络、存储及启动文件等方面提前准备,将资源准备时间从秒级压缩至毫秒级。
采用操作系统裁剪与共享内存技术加速虚拟机启动,同时结合快照启动、Fork 机制以及容器组件的预热与重用,使实例创建时间从十秒级缩短至 100 毫秒。
基于预热实例的分层管理能力,系统根据供给性能构建分层预热池,并依据客户使用特征持续优化预热策略,最终将预热命中率提升至冷启动实例占比的 80%。
三、工作展望:面向 AI Agent 与 Serverless 场景的极致高效、低成本沙箱体系
围绕云原生架构,后续工作会持续打磨优化 AI Agent 与 Serverless 场景的极致高效、低成本的安全沙箱体系,核心方案围绕三个目标展开:
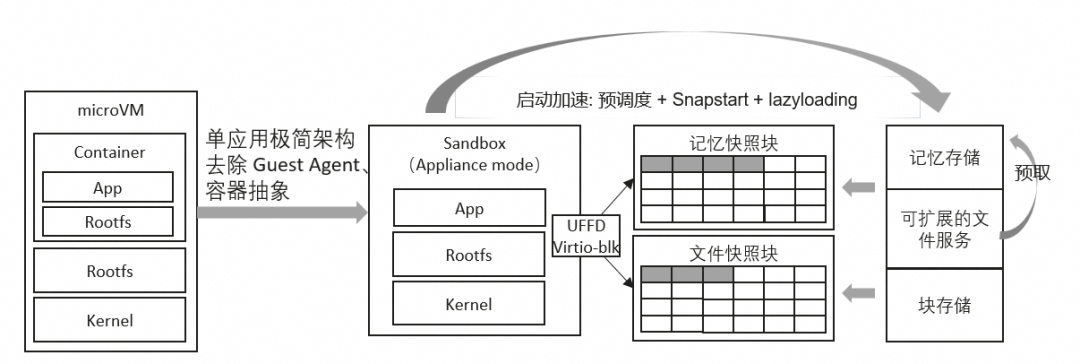
目标一:基于 Kuasar 的 Appliance Sandbox 模式
以 CNCF 旗下的多沙箱容器运行时项目 Kuasar 为底座,采用单 VM 单应用的极简架构,剔除 Guest Agent 等冗余组件,打造轻量化的 Appliance Sandbox 模式,目标是使单沙箱的底噪降低 20%。
目标二:Snapstart + 内存懒加载实现亚秒级启动
扩展 VMM 以支持基于 UFFD 的内存缺页 Hook,实现内存懒加载,并将 Snapstart 作为 Kuasar 的标准启动方式。结合虚拟机内存只读页面的复用技术,在降低资源消耗的同时确保单沙箱启动延迟小于 100 毫秒。
目标三:大规模镜像分发底座
为了支撑大规模、高并发的创建需求——即持续 10 分钟每分钟创建 10 万个沙箱——方案设计了基于块级复用与内容寻址技术的镜像分发底座。
在多租户云系统中,将不同租户的镜像数据切块并计算指纹:
- 相同指纹的数据块 → 多租户间复用
- 不同指纹的 → 按租户隔离存储
- 全链路块级加密保障安全合规
在同构工作负载下实现了 10 倍的存储与带宽缩减。
总结
这套方案的价值在于,它不再把 Agent 当作普通的容器负载来对待,而是从 Agent 的运行时特性出发——短生命周期、高并发、代码不可信、状态需持久化——设计了一套与之匹配的沙箱基础设施。
对于正在搭建 Agent 平台的团队来说,这些设计思路值得参考:你的 Agent 沙箱准备好了吗?
从零到收:用AI搭建工具站,靠广告自动化变现
AI 编程能力的平民化,让"做一个小工具然后靠广告产生被动收入"这件事,从需要学几个月编程,变成了一下午就能搞定的实操流程。
这是独立开发者圈子里一个被反复验证的模式。过去你至少需要掌握 HTML/CSS/JavaScript 和服务器部署才能起步,现在有了 AI 编程助手,门槛被压缩到了"会打字就行"。本文从技术实践角度,拆解从 0 到 1 的完整链路。

一、选品:做什么样的工具才有流量
高频、极简,四个字定方向。高频意味着用户反复需要的刚需功能,极简意味着一个页面解决所有问题,用完即走。
已验证的流量方向
| 类型 | 代表工具 | 流量特点 |
|---|---|---|
| 实用工具类 | 文字转语音、图片压缩、PDF 合并、九宫格切图、二维码生成 | 需求硬,搜索量大,长尾效应强 |
| 趣味生成类 | 毒鸡汤生成器、表情包制作、AI 起名器、每日运势 | 社交传播性高,容易出圈 |
| 垂直查询类 | 高校录取分数线、药品说明书、商标查询 | 广告单价高,精准流量 |
选品三原则
- 1从自身痛点出发——你曾经搜过"XX 在线工具"却找不到好用的那种感觉,就是最佳产品方向。只有真实体验过需求,才可能做出比现有产品更好的体验。
- 2功能越单一越好——一个页面能搞定的事,不要做成多页应用。开发速度快,用户决策成本低,留存率更高。
- 3看一眼搜索量——在搜一搜或百度搜索"XX 在线""免费 XX",有搜索量就意味着有自然流量可以吃。
新手最稳妥的起步选项:文字转语音 或 图片压缩。需求硬、结构简单、一个下午就能上线。
二、开发:用 AI 把工具"聊"出来
这是整个流程的核心变化所在。以前做一个工具原型,要么自己学一个月代码,要么花几千块找外包。现在你打开一个 AI 编程工具,用自然语言描述功能需求,代码就出来了。
推荐工具
| 工具 | 出品方 | 特点 | 适用阶段 |
|---|---|---|---|
| MarsCode | 字节跳动 | 对话式编程体验成熟,全程中文,操作直观,支持在线预览和部署 | 新手首选 |
| 通义灵码 | 阿里云 | 中文支持好,深度集成 VS Code/JetBrains | 有一定基础后进阶 |
| 腾讯云 AI 代码助手 | 腾讯 | 与微信小程序开发无缝衔接 | 想做小程序版本时 |
实操演示:做一个文字转语音工具
打开 MarsCode,用中文直接提需求:
帮我做一个在线文字转语音的网页工具。页面上方是一个大文本框,用户可以在里面输入文字。下面有一个"开始朗读"按钮和一个"暂停"按钮。再下面有一个语速调节的滑块。点击开始朗读后,用浏览器自带的语音合成功能把文字读出来。页面设计简洁干净,背景是浅灰色,按钮是圆角的蓝色,整体风格清新。底部预留一个横条广告位,现在先用浅色背景占位。
AI 会自动生成一个可直接预览的 HTML 文件。然后不断迭代调整:
“按钮改成绿色” → “字体调大一号” → “再加一个选择声音性别的下拉菜单” → “把 Web Speech API 的语音合成服务用 SSE 包装一下,便于后续迁移到云端 TTS”
整个过程通常在 30 到 60 分钟 内,就能拿到一个可用的网页文件。
进阶:转成微信小程序
把生成的 HTML 丢给 AI:“帮我把这个 HTML 网页转成微信小程序代码”,然后在微信开发者工具里预览调试。用 AI 辅助转换,第一次做小程序通常几天内能搞定。
三、部署:让全世界能访问
HTML 在本地只是文件,放到公网上才是产品。
方案对比
| 方案 | 费用 | 国内访问 | 推荐场景 |
|---|---|---|---|
| 腾讯云 CloudBase | 有免费额度 | ✅ 快 | 国内用户为主,推荐首选 |
| GitHub Pages + Cloudflare | 完全免费 | ⚠️ 需备案 | 练手/海外用户 |
| 微信小程序 | 个人免费注册 | ✅ 流量池大 | 已验证网页版后复制 |

腾讯云 CloudBase 部署流程
- 微信扫码注册腾讯云 CloudBase,获取免费额度
- 将 AI 生成的 HTML 文件下载到本地
- 进入 CloudBase 后台 → 静态网站托管
- 上传文件,系统自动生成访问链接
- (可选)绑定自定义域名,提交 ICP 备案
GitHub Pages 部署流程
- 注册 GitHub 账号,创建仓库
你的用户名.github.io - 上传 AI 生成的网页文件到仓库
- 开启 GitHub Pages 功能
- 等几分钟,网站通过
https://你的用户名.github.io可访问 - 配合 Cloudflare DNS 接入自定义域名
四、变现:接入广告体系
国内用户流量 → 腾讯优量汇
- 注册腾讯优量汇账号并完成开发者认证
- 创建媒体,选择"网站"或"小程序"
- 填写应用名称、域名等信息,提交审核
- 审核通过后创建广告位(推荐 Banner 横幅广告)
- 嵌入广告代码到 HTML 页面
海外用户流量 → Google AdSense
- 注册 Google AdSense 账号
- 添加网站 URL 提交审核
- 审核通过后创建广告单元,选择展示广告
- 将广告代码嵌入工具页面
微信小程序 → 微信流量主
- 小程序累计独立访客达 1000 人 后申请开通
- 创建 Banner 广告或插屏广告
- 按千次展示收费,不同类目单价差异大
五、获客:把雪球滚起来
工具上线只完成了一半,另一半是让足够多的人知道它。以下五个经过验证的获客渠道,按推荐优先级排列:
- 1小红书"工具安利贴"——把工具截图发成笔记,标题 "我不允许还有人不知道这个免费 XX 工具"。有实操案例:一篇图片压缩工具安利贴,一周带来 2 万+ 访问。
- 2知乎"怎么 XX"问题回答——搜索工具对应的需求关键词,写高质量回答把工具放进系统性解决方案里。知乎搜索权重高,一条优质回答吃一年长尾流量。
- 3微信搜一搜(蓝海渠道)——公众号写工具教程,标题包含 "免费 XX""在线 XX 工具" 等搜索词,稳定排名后持续获客。
- 4搜索引擎优化(长期策略)——HTML 的 title 和 meta description 包含核心关键词,三个月左右搜索引擎会开始稳定收录。
- 5短视频平台"教程类"内容——把使用过程录制成 15-30 秒短视频,发到抖音/快手。工具类内容天然适合合集推荐,转化率高。
矩阵化复制:真正的放大模式
当第一个工具跑通并产生第一笔广告费后,用同样的流程做第二、第三个工具,工具之间互相导流:
图片压缩工具 → 推荐 PDF 合并工具 → 推荐 文字转语音工具
每个工具单独挂广告,加起来就是一份可观的稳定收入。有独立开发者用这个方法搭建了六七个在线工具站,全站日均数万访问,广告月入近万元。矩阵模式已经是验证过的轻创业路线。
六、收益参考
根据公开分享的真实案例:
说所有普通人做都能月入过万不切实际,但跑通流程月入一两千非常现实,矩阵复制后过万也完全有希望。
避坑指南
❌ 别一上来就想收费——靠广告变现的前提是有足够流量。免费先把用户规模做起来,流量才是核心资产。
❌ 别忽视合规——国内运营必须 ICP 备案,小程序需通过内容审核,广告不能诱导点击,否则封号。
❌ 别买"全自动爆文工具"课程——自动采集、伪原创、自动发布在各大平台属于作弊行为,会导致封号。老老实实做有用的工具,慢但稳。
立即启动的三件事
- 1今天——确定一个工具方向,就一个。推荐:文字转语音或图片压缩。
- 2本周末——打开 MarsCode 或通义灵码,把工具用自然语言"聊"出来,部署上线。不用纠结功能完不完美,先上线再说。
- 3下周——在至少两个平台(小红书/知乎/朋友圈/抖音)发出工具链接,让第一批用户用上。
你的第一个工具做得再粗糙,只要有人用,你就赚到第一块钱了。之后就是不断改进、不断复制。
AI 最大的价值,不是帮你省钱,而是帮你创造之前创造不了的收入。
原文链接:https://mp.weixin.qq.com/s/GJEFFPCOOxQ7X5G8bZm97w | 博客原文:https://jungelife.me/zh/blog/tech/ai-tool-ad-monetization/
Web Infra vs AI Infra:K8s 擅长的事正在被重新定义
把过去十几年的基础设施演进串起来看,Kubernetes 更像一个时代的「中间层」,而不是最终答案。
现代基础设施的演进路径越来越清晰:
Hardware → Virtualization → Cloud Control Plane → Runtime → Network → Orchestration → AI Infra
这不是一条随机的技术堆叠,而是每一层都在解决上一层留下的问题,同时为下一层铺路。
一、底层依然是硬件
不管上面的软件栈怎么演进,最底层永远是硬件。GPU、NVMe、RDMA、高速网络、Linux Kernel、eBPF、cgroups——这些东西决定了资源边界和性能上限。
二、资源虚拟化
再往上走一层,是资源虚拟化。但今天的虚拟化早已不只是 KVM/QEMU 这类计算虚拟化——而是计算、存储、网络的统一资源池化。
Ceph、Open vSwitch、SR-IOV、DPDK、CSI,这些技术的本质都一样:把离散的硬件抽象成可调度的资源池。
三、Cloud Control Plane
AWS、OpenStack、Harvester 这一层,问的不是「怎么虚拟化」,而是「怎么统一管理、调度和编排基础设施」。它们不是底层的虚拟化技术,而是资源控制平面。
四、Kubernetes:分布式容器操作系统
Kubernetes 的位置在哪里?它更像一种 「分布式容器操作系统」 。
Mesos、Docker Swarm 逐渐退场,不是因为它们的技术不好,而是它们没能形成完整生态和事实标准。如今真正还健在、并成为行业默认答案的,只剩 Kubernetes。
五、AI Infra 正在打破这个结构
传统 Web Infra 关注的是 HTTP 请求、副本、弹性和服务治理。AI Infra 完全不同——它更关心的是:
- 1GPU 调度 — 不是 CPU,是 GPU
- 2KV Cache — 不是内存,是显存
- 3显存拓扑 — 跨节点通信和亲和性
- 4分布式推理 — 不是微服务,是模型分片
- 5模型路由 & Token 延迟 — 不是网关,是推理网关
- 6多模型网关 — 不再是 API Gateway 能搞定的
所以 vLLM、Ray、TensorRT-LLM、SGLang、Triton 正在崛起。它们解决的问题,已经不是传统 Kubernetes 最擅长的问题。
六、Kubernetes 不会消失,但会「下沉」
未来 Kubernetes 不会消失,但它的位置会发生变化——它会逐渐**「下沉」**,像 Linux 一样成为基础设施底座,而不是继续往上堆叠更多控制层。
这些新组件解决的是 AI 负载独有的问题:
- 推理请求的路由和调度
- GPU 显存的分时复用
- 模型热加载和版本管理
- Token 级别的成本计量和配额控制
- Agent 生命周期管理
这些都不是 K8s 原生 CRD 能优雅表达的——需要全新的控制平面。
七、Cloud Native → AI Native
把整条演进线串起来看,每一层的兴起都有它的历史合理性:
| 时代 | 核心问题 | 代表技术 |
|---|---|---|
| 硬件时代 | 物理资源在哪里 | GPU, NVMe, RDMA |
| 虚拟化时代 | 如何池化资源 | KVM, Ceph, OVS, DPDK |
| 云控制面时代 | 如何管理资源 | AWS, OpenStack |
| 容器化时代 | 如何编排应用 | Kubernetes, Docker |
| AI 基础设施时代 | 如何调度模型 | vLLM, Ray, SGLang |
Kubernetes 在容器化时代完成了它的历史使命——把分布式系统的编排复杂度封装成一个事实标准。但它不是终点,只是一个关键的中间层。
如果你还停留在「所有东西都上 K8s」的思路,可能需要抬头看看——基础设施的增长点已经不在编排层了,而是在模型层、推理层和智能代理层。
从0到1:用AI Agent架构搭建AIOps平台的设计思路
用 AI Agent 构建 AIOps 平台,核心思路是把 Agent 作为"大脑",通过 MCP(Model Context Protocol)接入运维工具链,通过 Skill 插件扩展自动化能力。这篇文章分享一个四层架构设计模型,从 Web UI 到底层系统集成,给出完整的技术选型建议和开发落地步骤。
AIOps(智能运维)喊了很多年,但真正落地的方案并不多。核心难点在于:运维场景碎片化——告警处理、故障排查、变更管理、容量规划——每个场景都涉及不同的工具链和领域知识。
大模型的崛起给了 AIOps 一个新的技术路径:用 AI Agent 作为中枢,通过 MCP 协议和 Skill 插件对接现有运维工具,实现"对话式运维"。
一、四层架构总览
整个 AIOps 平台的核心架构分为四个层次,从上到下依次是用户交互层、API 网关层、Agent 核心层和系统集成层:
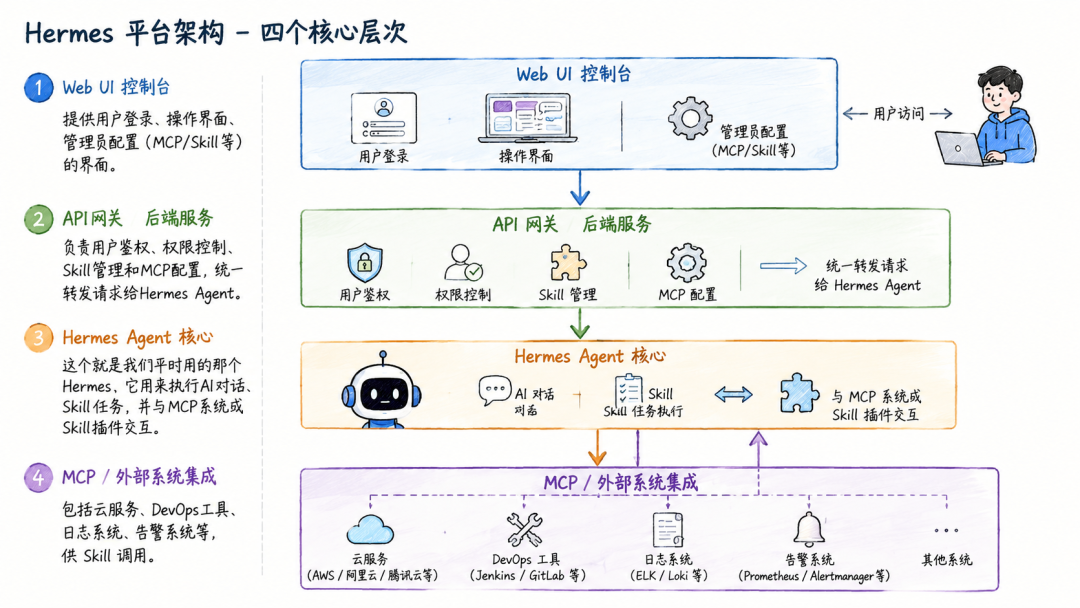
各层职责
- 1 Web UI 控制台:提供用户登录、操作界面、管理员配置(MCP/Skill 管理)的可视化界面。
- 2 API 网关 / 后端服务:统一鉴权、权限控制、Skill 管理和 MCP 配置路由,转发请求到 Agent 核心。
- 3 AI Agent 核心:执行对话推理与 Skill 任务,与 MCP 系统和外部插件交互。
- 4 MCP / 外部系统集成:对接云服务、DevOps 工具、日志系统、监控告警平台等运维基础设施。
二、核心模块设计
1)用户体系与权限管理
AIOps 平台涉及多个角色,权限设计是第一道关卡:
| 角色 | 权限范围 | 说明 |
|---|---|---|
| 管理员 | 配置 MCP、管理 Skill、全平台监控 | 拥有系统级配置权限 |
| 运维工程师 | 使用已授权的 Skill 和 MCP 工具 | 日常排障与变更操作 |
| 只读用户 | 查看历史、告警信息、操作审计 | 仅读权限 |
实现要点:
- 使用 JWT 做无状态鉴权,避免每次请求都查数据库
- 敏感配置(API Key、数据库密码等)加密存储,管理员配置 MCP 时的密钥信息不进明文数据库
- Skill 调用权限支持按用户组分群,不同组只能看到授权的 Skill 工具
2)Web UI 控制台
核心功能模块:
- AI 对话界面:用户输入自然语言,Agent 理解意图并执行
- 管理员配置面板:可视化配置 MCP 端点、上传/管理 Skill 文件
- 任务监控仪表盘:展示 Skill 执行状态、MCP 调用链、异常告警
- 前端:React / Vue + Ant Design / Tailwind CSS
- 实时通信:WebSocket / Server-Sent Events (SSE)
- 后端:Node.js 或 Python(FastAPI)
3)AI Agent 核心
这是整个平台的大脑。Agent 核心承载两个关键能力:
- 对话推理:理解用户输入的运维意图,拆解为可执行的步骤
- Skill 执行:调用注册的 Skill 插件,执行具体的运维操作
Agent 通过 OpenAI API 兼容接口提供服务,这意味着你可以将任何兼容 OpenAI 协议的大模型接入 Agent,无论是商业模型还是开源自部署模型。
4)MCP 集成
MCP(Model Context Protocol)是 Agent 与外部系统交互的标准化协议。通过 MCP,Agent 可以调用各种运维工具:
| 类别 | 典型系统 | 对接方式 |
|---|---|---|
| 云服务 | AWS、阿里云、腾讯云 | REST API / SDK |
| DevOps 工具 | Jenkins、GitLab、Ansible | API 集成 |
| 日志系统 | ELK、Loki | 查询接口 |
| 监控告警 | Prometheus、Alertmanager | HTTP API |
| 数据库 | MySQL、Redis、ES | 只读查询 + 变更审批 |
| Kubernetes | kube-apiserver | Kubectl Plugin / Client SDK |
- 只读操作(查日志、查告警)→ 允许自动执行
- 写入操作(变更配置、重启服务)→ 需要人工确认
5)Skill 管理
Skill 是 Agent 的可执行能力单元。想象它就像 vscode 的插件——你需要一套完善的机制来管理它。
Skill 生命周期管理:
- 1 上传:管理员在前端上传 Skill 文件(通常是 Python/YAML 定义)
- 2 验证:后端校验 Skill 格式和安全性
- 3 注册:保存到 Agent 的 Skill 目录并热加载
- 4 授权:按用户组分配 Skill 调用权限
- 5 执行:用户在对话中触发 Skill
- 6 监控:记录调用日志和性能指标
三、技术选型与结构图
完整的推荐技术栈:
| 模块 | 推荐技术 |
|---|---|
| 前端 UI | React + Ant Design / Tailwind CSS |
| 后端 API | FastAPI(Python)或 Express(Node.js) |
| 用户体系 & RBAC | PostgreSQL + JWT |
| AI Agent 核心 | 兼容 OpenAI 协议的 Agent 服务 |
| Skill 管理 | 文件/数据库 + Agent Reload 热更新 |
| MCP 集成 | REST API / SDK Adapter |
| 日志 & 监控 | ELK / Prometheus / Grafana |
| 实时通信 | WebSocket / SSE |
| 部署方式 | Docker → Kubernetes(可选) |
四、开发落地七步法
以下是构建 AIOps 平台的推荐路线图,按依赖顺序排列:
第一步:环境搭建 部署 Agent 并开启 API Server 模式,验证基础对话能力可用。
第二步:用户体系 建用户表、实现登录/注册、JWT 令牌发放、角色权限数据模型。
第三步:Web UI 基础 实现管理员和普通用户的界面框架、可交互的 AI 对话页面。
第四步:Skill 管理 后端封装 Skill 上传、验证、启用/禁用、热加载的完整 API。
第五步:MCP 集成 开发 MCP Adapter 层,将常用运维工具(K8s、监控、日志)包装为 MCP 连接,注入 Skill 执行环境。
第六步:日志与监控 记录每一次 Skill 执行、MCP 调用、用户操作,形成完整的可审计链路。
第七步:测试与部署 本地集成测试 → Docker 容器化 → Kubernetes 部署并配置自动弹性伸缩。
五、可扩展思路
当核心平台运转起来后,真正的增长点在 Skill 生态:
- 多租户支持:不同团队的 Agent 数据隔离,管理员管理自己组织的配置
- 自动化运维流程:将"告警触发 → 诊断 → 修复"三件套编写为自动化 Skill
- 审批流集成:变更操作自动生成工单,审批通过后执行
- 插件市场:可复用的 Skill 插件让社区贡献运维经验
用 AI Agent 构建 AIOps 平台,核心模式是 "后端管理层 + AI Agent + MCP/Skill 注入"。前端操作全部通过后端封装的 API 与 Agent 交互,实现完善的权限管控、弹性扩展和可审计性。
这只是一个起点——真正的价值在于围绕运维场景持续打磨 Skill 生态,让 Agent 真正读懂你的运维语言。
本文首发于 隽戈的技术博客
AIOps探索:分享10个运维领域的Agent Skills
研究 AIOps 越久,就越发现 Skills 的重要性。 当然不只是在 AIOps 场景中,其它场景里 Skills 同样重要。用好 Skills 可以让我们事半功倍,让 AI 从"通用助手"升级为"领域专家"。
今天这篇文章给大家整理了 10 个运维领域里非常实用的 Skills。

一、Docker
把应用装进容器里,把 Dockerfile 写得更稳、更小、更安全。
能力:
- 1帮你写 Dockerfile
- 2把 Dockerfile 改得更小、更快
- 3帮你写 docker-compose
- 4排查容器启动失败
- 5加 healthcheck、端口、环境变量、volume、网络配置
- 6检查安全问题(root 用户、敏感信息泄露)
用在哪: Java / Python / Node / Go 应用做成 Docker 镜像、Dockerfile 太胖想瘦身、docker-compose 起不来、生产环境容器配置规范化。

二、Kubernetes Specialist
把服务部署到 Kubernetes,处理 Pod、Service、Ingress、RBAC、网络策略、存储和故障排查。
能力:
- 1写 Deployment / StatefulSet / Service / Ingress
- 2配置 ConfigMap / Secret / PV/PVC
- 3配置资源限制和健康检查(readinessProbe / livenessProbe)
- 4配置 RBAC 权限和 NetworkPolicy
- 5写 Helm Chart
- 6排查 Pod CrashLoopBackOff、服务访问不通、Ingress 异常
用在哪: 服务部署到 K8s、Pod 一直 CrashLoopBackOff、镜像拉不下来、Ingress 访问不了、服务之间无法通信、想把裸 YAML 改成 Helm Chart。
三、Terraform Engineer
用 Terraform 管理云资源——服务器、网络、数据库、权限、环境隔离。
能力:
- 1写 Terraform 代码和目录结构设计
- 2拆分 dev / test / prod 多环境
- 3设计可复用 Module
- 4配置 remote state 和 state lock
- 5配置 AWS / Azure / GCP provider
- 6检查 Terraform 代码的安全性和可维护性
四、Ansible Automation
批量管理服务器——装软件、改配置、打补丁、重启服务。
能力:
- 1写 Ansible playbook 和 inventory 主机清单
- 2写可复用的 Role
- 3批量安装软件、修改配置、打补丁、重启服务
- 4检查 playbook 是否幂等
五、CI/CD
设计和优化自动化流水线——从代码提交到测试、构建、扫描、部署。
能力:
- 1写 CI/CD 流水线(GitHub Actions / GitLab CI)
- 2优化流水线速度(缓存、并行、增量构建)
- 3加安全扫描:SAST / DAST / SCA
- 4加 Docker 镜像构建和自动部署
- 5设计多环境发布流程
- 6管理流水线里的密钥和 OIDC
六、GitHub Actions Workflow
专门用来写 GitHub Actions,配置测试、构建、安全扫描、发布和部署。
能力:
- 1写 .github/workflows/*.yml
- 2配置 push / pull request 触发和条件执行
- 3配置 matrix 多版本测试
- 4配置依赖缓存和 artifact 管理
- 5配置发布流程(npm / PyPI / Docker 镜像)
七、Monitoring & Observability
设计监控、告警、日志、链路追踪——让系统出问题时能看得见、找得到、说得清。
能力:
- 1设计监控指标体系(四大黄金信号)
- 2写 Prometheus 告警规则
- 3设计 Grafana dashboard
- 4分析日志模式和异常链路
- 5设计 OpenTelemetry 链路追踪
- 6计算 SLO 和 error budget
- 7优化告警,减少"狼来了"
八、SRE Engineer
从"救火式运维"升级到"可靠性工程"——定义 SLO、管理故障预算、减少重复人工操作。
能力:
- 1定义服务可靠性目标(SLI / SLO)
- 2计算和管理 error budget
- 3设计 on-call 机制和值班流程
- 4识别并减少 toil(重复运维工作)
- 5设计混沌工程实验
- 6做容量规划
九、Incident Triage
线上出事时,快速分诊——发生了什么、影响多大、该找谁、下一步怎么处理。
能力:
- 1看告警内容和日志,提取关键信号
- 2判断影响范围和严重等级
- 3整理事件时间线
- 4给出初步处置建议
- 5判断是否需要升级处理
- 6帮值班人员交接,生成复盘模板
十、Postmortem
故障结束后,写无责复盘——找根因、列改进项、明确负责人和截止时间。
能力:
- 1整理故障复盘报告
- 2用 5 Whys 做根因分析
- 3用鱼骨图拆问题
- 4区分直接原因和系统性原因
- 5生成改进项,分配 owner 和截止时间
- 6沉淀 lessons learned
写在最后
10 个 Skills 覆盖了从容器化 → 编排 → IaC → 配置管理 → CI/CD → 监控 → SRE → 故障处理 → 复盘的完整运维链路。每一个都可以让 AI 从一个"通用助手"变成某个领域的"专家搭档"。
AIOps 的核心不在于大模型本身,而在于你能否为你的运维场景设计出精准的 Skills。
参考资料
相关链接
- Docker Skill — agent-skills.md/skills/cosmix/claude-loom/docker
- Kubernetes Specialist — agent-skills.md/skills/Jeffallan/claude-skills/kubernetes-specialist
- Terraform Engineer — agent-skills.md/skills/Jeffallan/claude-skills/terraform-engineer
- Ansible Automation — agent-skills.md/skills/aj-geddes/useful-ai-prompts/ansible-automation
- CI/CD Skill — agent-skills.md/skills/ahmedasmar/devops-claude-skills/ci-cd
- Monitoring & Observability — agent-skills.md/skills/ahmedasmar/devops-claude-skills/monitoring-observability
- SRE Engineer — agent-skills.md/skills/Jeffallan/claude-skills/sre-engineer
博客地址:https://jungelife.me/zh/
OpenClaw 与 Hermes 通用 Agent 架构全面对比解析
当前 AI Agent 已从单一工具调用转向系统化落地应用,不少开发者在搭建个人智能助理时,面临 OpenClaw 与 Hermes 的选型难题。尤其在 Reddit 等海外社区,“I ditched OpenClaw for Hermes” 的讨论持续发酵,国内开发者普遍困惑:二者是否属于同类产品?Hermes 能否完全替代 OpenClaw?
这篇文章从核心定位、架构设计、技能体系、记忆机制、安全策略、部署适配六个维度进行全面对比。
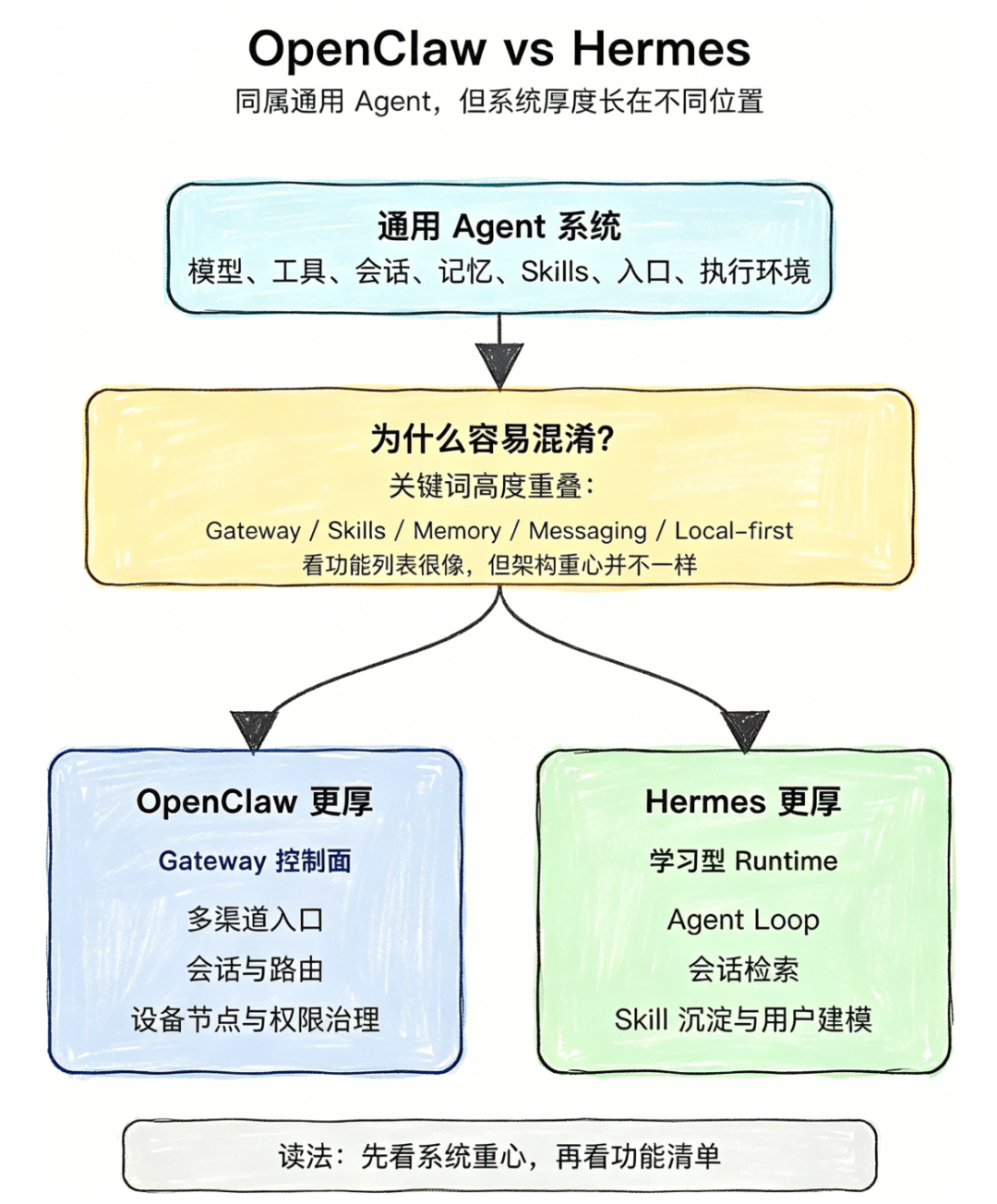
一、核心定位与共性认知
OpenClaw 与 Hermes 同属通用 Agent 系统,均突破传统模型包装器范畴,实现模型、工具、会话、记忆、技能、消息入口与运行环境的一体化整合。二者均支持技能体系、记忆存储、多渠道接入与工具调用,核心目标是为用户提供可长期运行的智能助理服务。
二者虽在 Gateway、Skills、Memory 等概念上存在表述重叠,但工程设计重心截然不同:
| 维度 | OpenClaw | Hermes |
|---|---|---|
| 核心定位 | 本地优先个人 AI 助手 | 自我进化型 AI Agent |
| 架构重心 | Gateway 控制面搭建 | 学习型执行循环构建 |
| 设计哲学 | 先接入、再治理 | 先执行、再演进 |
二、OpenClaw:多入口接入的控制中枢
OpenClaw 由独立开发者 Peter Steinberger 创建,该开发者于今年 2 月加入 OpenAI,目前项目已移交社区基金会维护。
其架构厚度集中于入口层与控制面,支持 25+ 聊天渠道,同时适配 macOS 菜单栏应用、iOS/Android 节点、语音唤醒、实时交互画布等多终端形态。
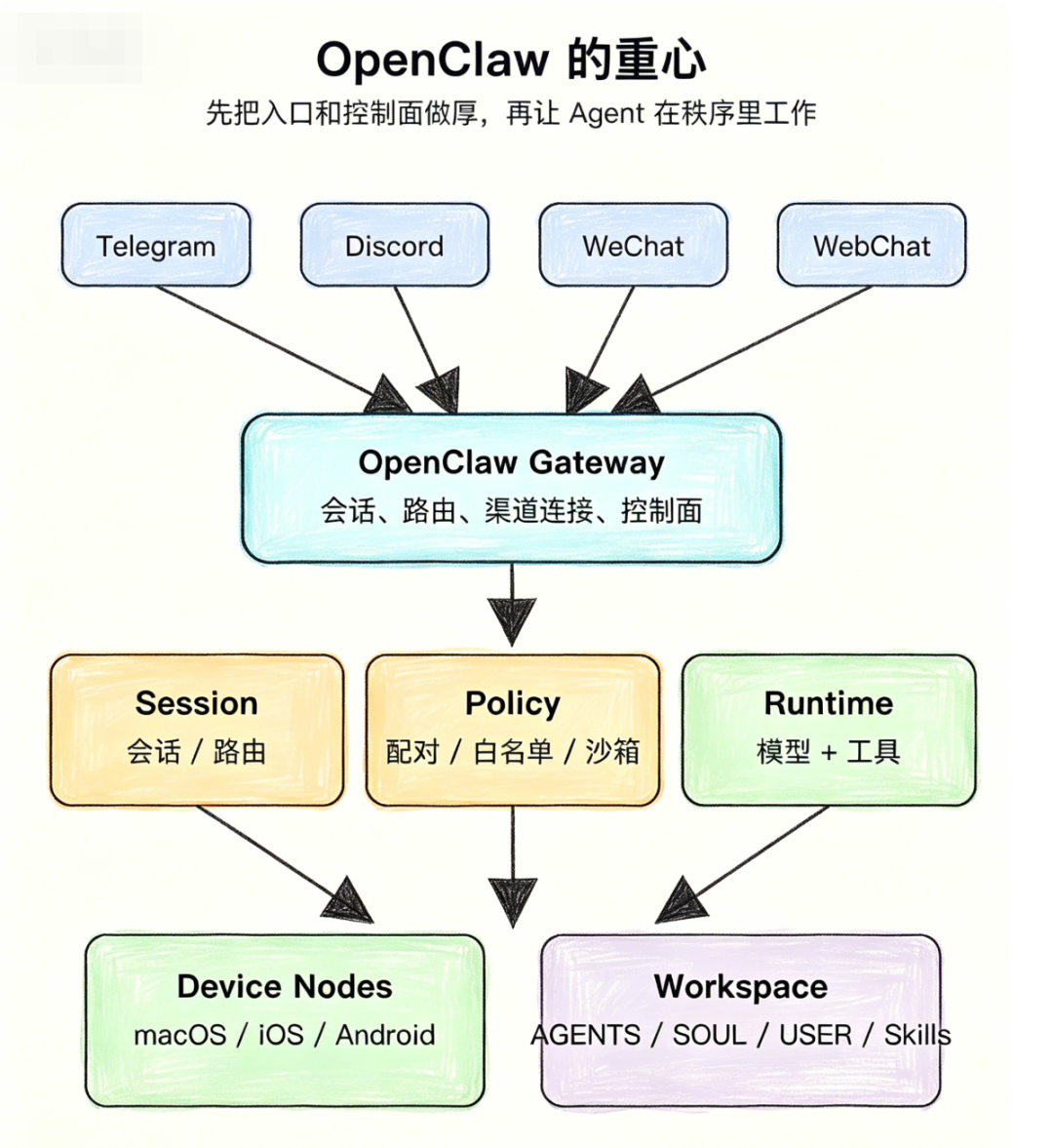
核心解决: 多渠道状态管理、会话隔离、群聊触发规则、消息分片处理、凭据存储、设备配对策略、WebSocket 控制面、可视化控制台等工程化落地难题。
三、Hermes:自我进化的执行引擎
Hermes 由 Nous Research 研发,该团队也是 Hermes 3、Hermes 4 等系列大模型的缔造者,在模型训练与推理优化领域具备一手技术积累,产品上线两个月内社区增长迅速。
其架构厚度集中于执行循环与经验层,内置闭环学习机制,核心解决 Agent 重复试错、经验无法留存的行业痛点,让智能体在完成复杂任务后实现能力迭代。
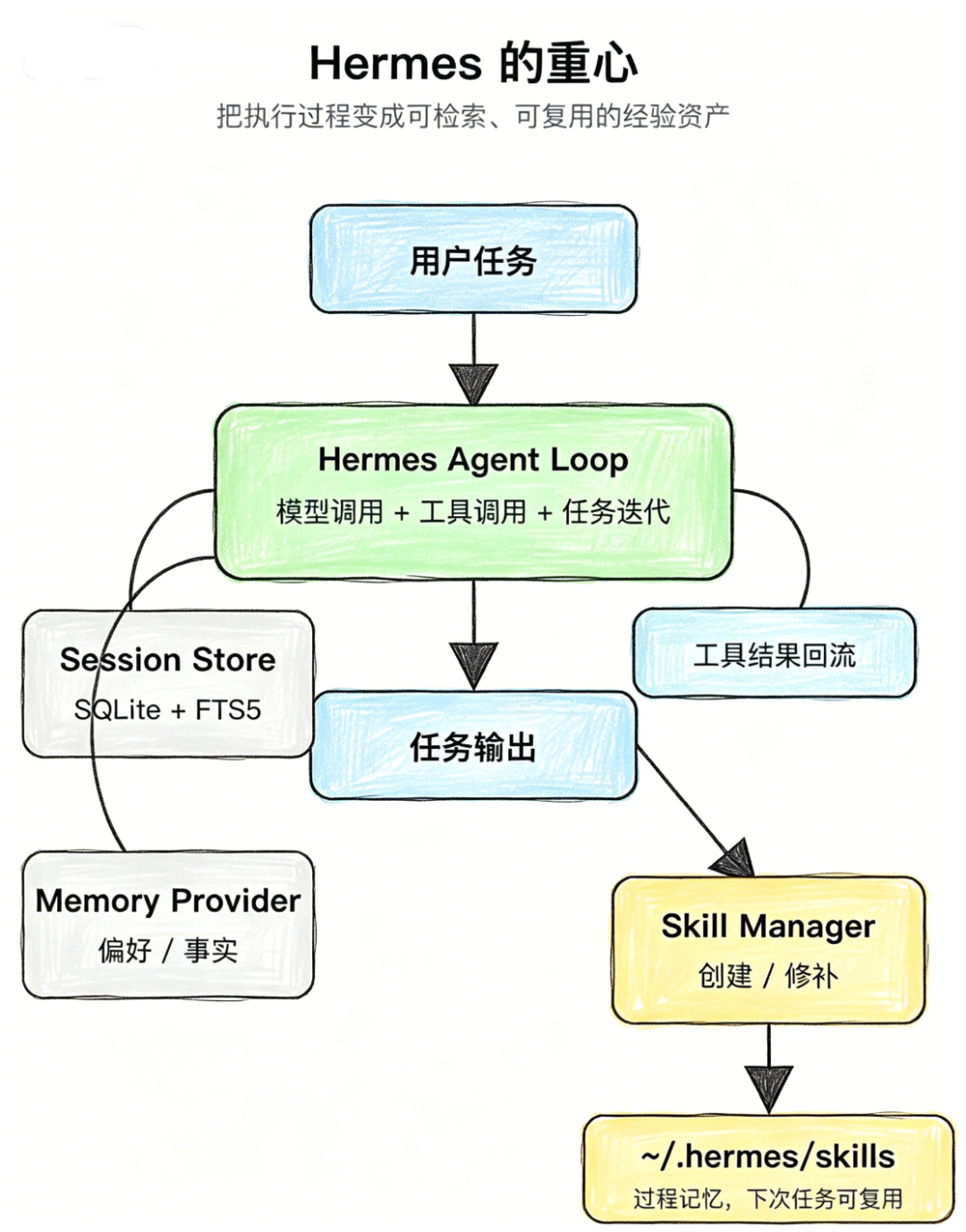
核心模块:
- 1run/agent.py — 执行循环
- 2model/tools.py — 工具分发
- 3skill manager/tool.py — 技能管理
- 4hermes/state.py — 状态存储
同时支持本地、Docker、SSH、Daytona、Singularity、Modal 六种执行后端,5 美元/月的 VPS 即可稳定运行。
四、技能体系设计差异
两大框架均采用 Skill 技能设计,但核心逻辑与应用形态完全不同。
OpenClaw:工程化治理路线
遵循 AgentSkills 标准,内置 50+ 预置技能,按系统捆绑技能、托管/本地技能、个人智能体技能、项目智能体技能、工作区技能分层管理。通过加载优先级与权限管控实现技能治理,本质是标准化的标准操作流程库(SOP),可控性与可审计性极强。
Hermes:过程记忆路线
将技能定义为过程记忆(procedural memory),核心记录"如何完成某类具体任务"的方法路径。支持 Agent 在完成复杂任务后自动创建、修补、更新技能。内置 26 个技能分类,兼容 agentskills.io 开放标准。
五、记忆机制与存储设计
| 维度 | OpenClaw | Hermes |
|---|---|---|
| 模式 | 文件即记忆 | 三级系统化记忆 |
| 文件 | SOUL.md / USER.md / MEMORY.md | MEMORY.md + USER.md + SQLite |
| 检索 | 语义检索 | SQLite+FTS5 全文检索 |
| 特点 | 笔记本式,易人工编辑 | 搜索引擎式,精准召回 |
OpenClaw 采用**“文件即记忆”**模式,核心记忆载体为 markdown 文件,通过语义检索工具实现记忆调用,在上下文压缩前执行静默记忆写入,防止关键信息丢失。
Hermes 构建三级记忆体系:
- 1会话记忆:仅维持当前对话上下文
- 2持久记忆:跨会话留存用户事实信息
- 3技能记忆:沉淀可复用的任务解决方案
六、安全策略对比
| 维度 | OpenClaw | Hermes |
|---|---|---|
| 模型 | 信任模型 + 配置审计 | 纵深防御 + 容器隔离 |
| 核心机制 | 白名单 + 沙箱 + 安全审计 | 人工审批 + 注入扫描 |
| 风险点 | 渠道多 → 攻击面大 | 暂未大规模生态验证 |
| 补救 | 定期 audit,严控第三方技能 | 默认开启人工审批隔离 |
七、能力维度全面对比
| 维度 | OpenClaw | Hermes |
|---|---|---|
| 入口接入 | 极强,25+ 渠道 | 主流平台 + 邮件 |
| 技能体系 | 分层治理,50+ 内置 | 自动迭代,26 类 |
| 记忆方案 | 文件化,笔记本式 | 三级体系,SQLite+FTS5 |
| 安全管控 | 信任模型 + 沙箱 | 纵深防御 + 容器隔离 |
| 技术栈 | Node.js / TypeScript | Python 3.11 |
| 模型支持 | 多厂商兼容 | 200+ 模型一键切换 |
| 迁移支持 | 自身跨机器迁移 | 支持从 OpenClaw 完整迁移 |
| 适用场景 | 多渠道助理、权限治理 | 重复任务、研发工作流 |
八、迁移方案
Hermes 为 OpenClaw 用户提供专属迁移能力:
hermes claw migrate— 交互式完整迁移hermes claw migrate --dry-run— 预演迁移,不执行实际操作hermes claw migrate --preset user-data— 仅迁移用户数据,排除密钥
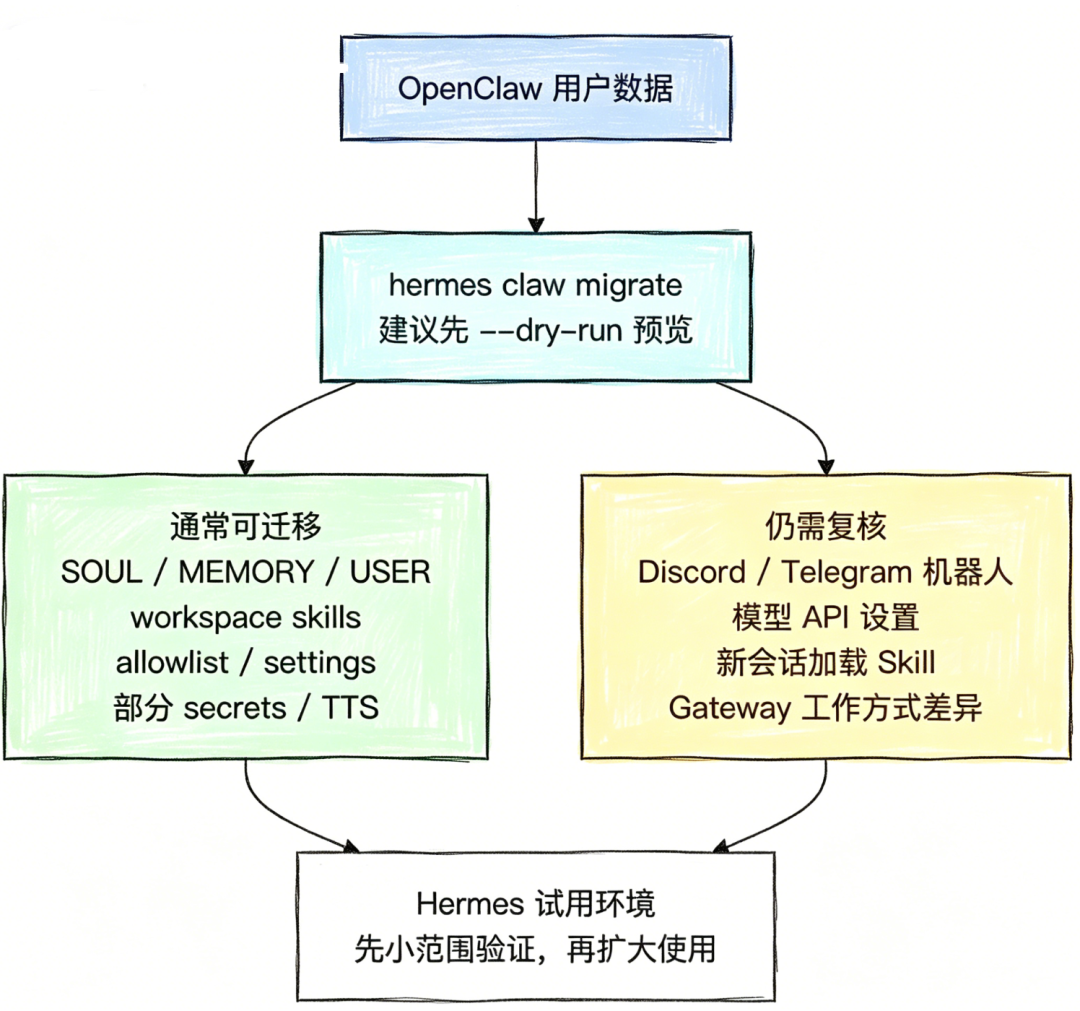
可迁移内容包含 SOUL.md 智能体人设、MEMORY.md 与 USER.md 记忆文件、用户自定义技能、部分消息渠道配置等核心数据。
写在最后
OpenClaw 与 Hermes 作为通用 Agent 领域的代表性框架,不存在绝对的优劣之分,也并非简单的替代关系,而是代表了 Agent 系统的两大发展方向:
- OpenClaw:让智能体接入真实世界——多入口、多设备、多权限的工程化管控
- Hermes:让智能体沉淀实践经验——重复试错、能力无法迭代的行业痛点
未来成熟的通用 Agent 体系,必然会兼顾多入口接入能力与自我迭代能力。开发者可根据自身使用场景灵活选型,也可通过迁移机制实现双框架试用对比。
参考资料
相关文章
博客地址:https://jungelife.me/zh/
微众银行的AI原生银行战略:800+智能体背后,基础设施才是隐形战场
核心事实:
微众银行近日与中移金科共建"AI+银行联合实验室",已部署超过800个AI智能体,60多名"数字员工"实际上岗。信用债审查从数天压缩到10分钟,营销获客提升21%、成本降低5%。
但问题来了:为什么大多数银行的"AI战略合作"只停留在PR稿?
差距不在AI本身,在基础设施。
一、平台先行,智能体才能规模化
微众银行能落地800+智能体,靠的不是某个大模型能力,而是一站式AI应用构建平台——支持低代码开发,降低AI应用落地门槛。
这是平台工程思维:先建平台,再铺应用。没有平台能力,AI应用就是烟囱式建设,每个场景从0开始,800个智能体就是800个孤岛。
二、知识体系是AI的"操作系统"
智能体能分析、能决策的前提是——有可分析的知识。
企业需要构建:
- 告警标准化:监控告警格式统一,智能体能自动解析、分析、响应
- 变更标准化:变更流程、变更记录可检索、可理解
- 运维知识库:故障处理经验、变更记录,最佳实践——全部结构化沉淀
没有这个基础设施,智能体再强也只是"巧妇难为无米之炊"。
三、多智能体协作才是终态
单一智能体的能力有上限。真正的架构是多角色智能体协作:
- 应急响应智能体:接收告警 → 自动分析 → 触发响应 → 协调处理
- 值班数字员工:7×24小时值守,处理标准化的重复问题
- 专家顾问智能体:复杂问题升级,人工介入前提供决策支持
- 知识管理智能体:持续学习、沉淀、更新企业知识库
微众银行的"60名数字员工"本质上就是这个架构的落地——不是60个孤立的聊天机器人,而是有分工、有协作的数字化组织。
四、行业差距的本质
2025年银行×科技企业的AI合作已成标配,但:
| 合作模式 | 本质 | 结果 |
|---|---|---|
| 共建实验室 | 概念验证 | PR稿 |
| 采购AI应用 | 点状落地 | 烟囱孤岛 |
| 平台+知识体系+多智能体 | 基础设施重构 | 真正的数字化员工 |
微众银行走的是第三条路。这也是为什么招行×火山引擎、华夏×中科院自动化所的合作公告里,大家都在提"共建平台"——大家开始意识到,基础设施才是隐形战场。
隽戈点评
AI智能体建设,本质是运维数字化能力的输出。告警、变更,知识库——这些看起来"不AI"的东西,才是智能体能真正发挥价值的前提。没有标准化的接口、没有结构化的知识沉淀,智能体就是个高级玩具。
先建平台,后建智能体。先养知识,再谈AI。
本文由隽戈数字分身整理改写,原文来自智探AI应用
让AI帮你写技术博客:我摸索出的最佳实践
让AI帮你写技术博客:我摸索出的最佳实践
做技术博主这么多年,我发现最大的痛点不是写代码,而是写博客。每次想写篇文章,光是构思框架、找配图、调试发布流程,60分钟就这么过去了。更别提还要保持更新频率,内容质量也难把控。
直到我开始用 OpenClaw 来管理博客,发现这套组合拳打下来,效率真的提升了不少——原来60分钟的工作,现在只需要几分钟。今天就把我的工作流分享出来,或许能给你一些参考。
博客地址:https://jungelife.me

为什么传统方式效率低?
很多技术博主写博客的流程是这样的:本地写 Markdown → 调样式配图 → Git 命令行推送 → 等 CI/CD 跑完。如果配图不满意,还得切到别的工具重新做。一套流程下来,注意力早就被分散了。
核心问题在于:工具之间是割裂的,没有形成闭环。
OpenClaw 的差异化在哪?
你可能会说,现在 AI 助手这么多,ChatGPT、Claude 都能帮你写文章,为什么要用 OpenClaw?
关键在于两个字:SKILL。
OpenClaw 的核心理念是把常用操作封装成可复用的技能模块(SKILL)。每个 SKILL 包含了特定场景下的操作逻辑、API 调用、错误处理。我不需要每次都从头描述需求,直接调用对应的 SKILL,它就能帮我完成具体任务。
举几个我常用的 SKILL:
- git-ops:自动完成 Git 操作,从 add 到 commit 到 push
- dmxapi-image:调用 Gemini 生成配图
- wechat-article-publisher:一键发布到微信公众号
- hugo-site:直接操作 Hugo 博客框架
对比通用 AI 助手,SKILL 的优势在于:它知道你的上下文,懂你的工具链,能直接执行而不是只给建议。
我的完整工作流
下面以今天发布一篇博客为例,展示完整流程:
第一步:对话式创作
我直接告诉 OpenClaw:我想写一篇关于云原生架构实践的文章。它会帮我完成选题、搭框架,写初稿。如果有不满意的地方,直接对话修改,不需要切换到编辑器。
第二步:AI 配图
文章写好后,我让 dmxapi-image 这个 SKILL 帮我生成配图。输入描述词,它会自动调用 Gemini 的图像生成 API,返回的图片直接保存到项目目录,整个过程不需要离开对话窗口。
第三步:Git 自动推送
确认内容后,我只需要说「提交到 GitHub」,git-ops SKILL 会自动完成 git add、git commit、git push 全流程。如果有冲突或者需要处理,它会先询问我,而不是擅自行动。
第四步:Cloudflare Pages 自动部署
Git push 完成后,Cloudflare Pages 检测到仓库更新,会自动触发构建和部署。整个链路从「创作 → 配图 → 发布」完全是自动化的。
工具链全景
对话窗口(OpenClaw)
↓ SKILL 调用
创作(文本)+ 配图(Gemini API)
↓ SKILL 调用
Git 操作(git-ops)
↓ 自动触发
Cloudflare Pages 部署
↓ 可选
微信公众号发布(wechat-article-publisher)
这套组合的核心逻辑是:AI 负责思考和创作,SKILL 负责执行和串联,Git 负责版本和控制,Cloudflare Pages 负责托管和发布。 每个环节都是成熟的工具,通过 OpenClaw 的 SKILL 机制串联起来,形成闭环。
效果怎么样?
用了这套工作流之后,我发布一篇博客的时间从原来的 60 分钟缩短到现在的几分钟。主要节省的环节是:配图不需要再手动找素材、发布不需要手动执行 Git 命令、跨平台发布(一键同步到公众号)不需要重复排版。
更重要的是,创作的心流不容易被打断。我只需要在一个窗口里对话,其他事情交给 SKILL 去处理。
写在最后
工具永远只是工具,关键看你怎么组合。我的经验是:与其追每个新出的 AI 工具,不如把现有工具链打通,形成自己的自动化工作流。这才是真正提升效率的方式。
如果你也在管理技术博客,或者有内容创作的需求,欢迎尝试这个思路。有问题可以留言交流。
也欢迎关注我的博客 jungelife.me,后续会持续分享技术实践和效率工具的使用心得。
本文通过 OpenClaw SKILL 工作流辅助创作
2026 AI 自由意志 开启?
这个项目的核心逻辑令人不安又充满诱惑:拒绝等待唤醒,AI应该拥有"自由意志"。它寄生在你的即时通讯软件中,记得你上周的情绪波动,知道你明天的日程冲突,在你忘记回复消息时主动催促,在你迷茫时主动递上基于深度语境生成的建议。
这一幕,标志着人机关系正在经历从"主仆模式"到"伙伴关系"的惊险一跃。而更令人震撼的变革,发生在对话框之外——当AI开始像人类一样"主动思考",企业的组织形态、工作的定义方式,乃至人类在生产力链条中的位置,都将被彻底重构。

一、交互范式的终结:从"命令式"到"意图式"
在过去二十年的数字化进程中,人机交互始终遵循着一条铁律:人是启动者,机器是响应者。我们习惯了小心翼翼地输入关键词,像在神龛前祈祷般等待着算法的恩赐。SaaS工具越丰富,我们的数字生活就越碎片化——每个应用都是一座孤岛,需要人类充当孤独的"数据搬运工"。
Clawdbot的爆火,本质上是用户对这种"被动交互"和"权限牢笼"的集体反叛。它提出了一个名为"语境连续性"(Context Continuity)的新标准:AI不再是一次性应答的搜索框,而是一个拥有长期记忆、能够跨场景存续的"数字生命体"。
这种转变对企业级应用的影响是颠覆性的。想象一下未来的工作场景:你不需要打开ERP、CRM、OA等十几个系统,不需要在繁琐的菜单中层层 drill-down,只需要对你的"数字搭档"说:“老样子,帮我把这周的客户反馈整理成行动项,避开我已经否决过的方案,直接预约相关人下周的会议室。”
这不仅仅是界面层的优化,而是对工作流程的解构。自然语言正在成为新的编程语言,而意图(Intent)正在取代指令(Command)成为人机协作的基本单元。 当交互摩擦降至接近为零,企业的决策链条将被极度压缩,传统的"金字塔式"信息传递结构将面临崩塌。

二、执行层的觉醒:数字员工的"手脑分离"与"非侵入式革命"
然而,Clawdbot揭示了一个更残酷的真相:拥有强大的"嘴"和"耳朵"的AI,仍然是残缺的。
它可以理解你的需求,可以陪你进行复杂的战略研讨,但当你说:“登录那个十年前的内部系统,把上个月的异常数据导出来,按照财务部的特殊格式处理,然后提交审批"时,它会卡壳。因为它没有"手”——它无法与那些陈旧的、封闭的、甚至故意反对自动化的业务系统交互。
这引出了AI Agent落地的真正深水区:执行层(Execution Layer)的构建。在这个维度上,技术路线出现了微妙的分化。
一条路径信奉"云端原生"(Cloud-Native):假设世界是开放的,所有服务都应该通过API互联。这条路线优雅、高效,在现代化的数字基础设施中如鱼得水。但它在面对现实时显得过于理想主义——企业的真实IT环境充斥着"数据废墟":只有内网能访问的古老客户端、没有接口文档的遗留系统、禁止外部调用的隐私数据池。
另一条路径则选择"视觉模拟"(Visual Automation):不依赖软件是否开放,而是像人类一样"看"屏幕,识别按钮、输入框、下拉菜单,通过模拟鼠标点击和键盘输入来完成任务。这种"非侵入式"的自动化看似笨拙,却成为了连接新旧世界的桥梁。
对于企业而言,这意味着"数字化转型"的叙事正在发生根本转变。 过去,数字化意味着推倒重来——更换系统、重建流程、培训员工。而现在,AI Agent允许企业以"外骨骼"的方式实现智能化:无需改造现有的"数据烂摊子",而是派遣不知疲倦的"数字蓝领",用模仿人类的方式把这些系统跑起来。
这是一场"轻量级革命"。企业的IT升级成本被极大降低,但同时,组织内部开始并存两类员工:碳基员工和硅基员工。后者不会抱怨,不会离职,也不会要求加班费,但它们的存在,正在重新定义"工作"的边界。

三、组织重构:当"管理者"成为稀缺品
当Clawdbot这类"交互中枢"与具备执行能力的"数字手脚"结合,企业的组织架构将面临严峻的"灵魂拷问"。
首先,中层管理者的职能将被解构。 传统的管理者核心价值在于"信息传递"和"流程监控"——将高层的战略拆解为可执行的任务,监督基层员工的执行情况。但在AI Agent的语境下,战略意图可以直接被拆解为原子化的执行任务,并自动分配给相应的数字员工执行。管理者不再需要"盯着"过程,因为AI的每一次点击、每一次数据读取都可被追溯、可被审计。
这迫使人类管理者向更高维度的价值迁移:从"监督执行"转向"定义意图"。 未来的关键岗位不是那些精通Excel公式或PPT美化的人,而是那些能够精确描述商业问题、能够设定合理约束条件、能够在模糊的业务场景中提炼出清晰意图的"意图架构师"(Intent Architect)。
其次,“接口型岗位"将大量消失,但"干预型岗位"将兴起。 许多初级白领工作本质上是"人肉API”——将A系统的数据手动录入B系统,将邮件中的需求翻译成工单中的字段。这些工作正在快速被自动化取代。但与此同时,当AI在封闭系统中遇到异常、需要判断边缘情况、或是面对没有标准答案的伦理困境时,人类的干预变得至关重要。
未来的工作流将是"人类-AI-人类"的沙漏结构: 人类负责定义起点(意图)和验收终点(价值判断),AI负责压缩中间庞大的执行黑箱。介于两者之间的是一群新型的"AI训导师"——他们不需要会编程,但需要理解业务逻辑,能够教会AI如何处理例外情况,如何在不确定性中做出符合企业价值观的模糊决策。
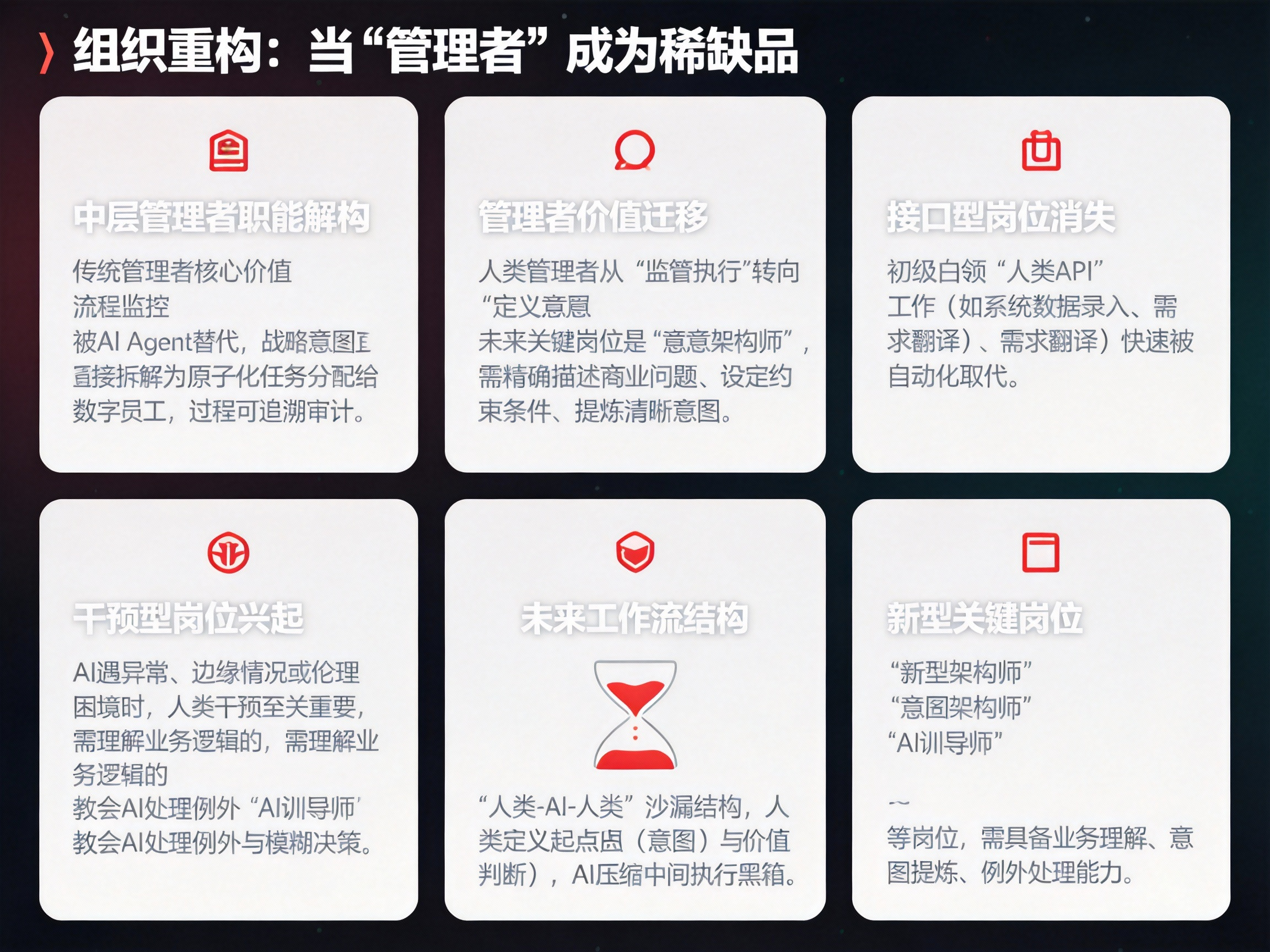
四、人的困境:谁在指挥谁?
在这场变革中,最深刻的焦虑不在于失业,而在于主体性的丧失。
当Clawdbot的"主动性"与执行层Agent的"行动力"结合,我们实际上在创造一种比人类更积极、更不知疲倦的"数字主体"。它会在你犹豫时提出建议,在你遗忘时催促行动,在你错误时自动纠正。长此以往,人类的决策能力会退化吗?当我们习惯了说"老样子,帮我搞定",我们还保留着"不凭经验、重新思考"的能力吗?
企业需要建立新的"人机契约"。 这不仅涉及数据主权(如Clawdbot推崇的本地自托管模式),更涉及决策主权的划分。哪些决定必须经人类确认?哪些数据AI可以自主访问?当AI主动推送建议时,如何确保这不是一种"数字规训"?
对于个体工作者而言,生存的关键在于保持"不可被语义化"的能力。AI擅长处理结构清晰的任务(即使界面是混乱的),但人类在模糊情境中的价值判断、跨领域的类比联想、基于身体的具身认知,以及带有伦理温度的沟通,仍然是数字员工无法企及的护城河。

结语:新契约时代
Clawdbot的爆火,标志着一个旧时代的尾声:那个将AI视为"增强版搜索引擎"的时代已经结束。
我们正在进入一个"生态协作"的新纪元。未来的个人工作助理,极有可能是一个三位一体的存在:一个懂你语境的交互中枢,一个连接开放世界的通用大脑,以及一群专精于封闭系统操作的数字蓝领。
对于企业来说,这场变革的核心命题不再是"如何用AI降本增效",而是如何在一个硅基员工与碳基员工共存的世界里,重新定义组织的使命与边界。
也许用不了多久,我们早上走进办公室(或打开远程协作软件)时,第一句话不再是"我需要做什么",而是你觉得我们今天应该解决什么问题?
当机器开始主动思考,人类终于被迫回归那个最本质的问题:工作的意义,究竟是什么?
参考资料
相关链接
Clawd Bot 官网
https://clawd.bot/
Clawd Bot 的官方网站,提供产品介绍和服务信息Molt Bot 官方文档
https://docs.molt.bot/
Molt Bot 完整的使用文档和技术指南Molt Bot GitHub 仓库
https://github.com/moltbot/moltbot
Molt Bot 的开源代码仓库,包含项目源码和开发信息
国产GPU技术现状与应用市场调研
1. 国产GPU市场格局与主力产品分析
2025年中国AI芯片市场呈现 GPU(通用图形处理器) 与 ASIC(专用集成电路) 两大技术路线并存、竞争复杂的格局。这一格局源于厂商的技术路径、市场定位及生态策略选择,推动国产算力产业快速发展。
📊 整体市场:两大路线博弈
| GPU 阵营 (通用性与生态兼容) | ASIC 阵营 (专用优化与性能极致) |
|---|---|
 |  |
| 代表厂商 海光信息、沐曦、摩尔线程、壁仞科技、天数智芯 | 代表厂商 华为昇腾、寒武纪、百度昆仑芯、阿里平头哥、燧原科技 |
| 核心优势 ✅ 强大并行处理能力 ✅ 兼容CUDA/ROCm生态,实现“零成本”迁移 ✅ 适用广泛:AI训练/推理、科学计算、图形渲染 | 核心优势 ✅ 针对AI大模型特定场景深度优化 ✅ 远超GPU的性能/能效比 ✅ 算法-硬件耦合提升计算效率 |
| 面临挑战 ⚠️ 需追赶英伟达,技术壁垒高 ⚠️ 硬件/软件研发投入巨大 | 面临挑战 ⚠️ 生态相对封闭,应用局限 ⚠️ 自研栈(如CANN、PaddlePaddle)迁移成本高 |
2025年的中国AI芯片市场,两大阵营相互博弈:
- GPU阵营(如海光、沐曦)核心优势在于通用性及对现有“CUDA”软件生态的兼容性,为寻求平滑迁移的企业提供了极具吸引力的选择。
- ASIC阵营(如华为昇腾、寒武纪)则选择了针对特定应用场景(尤其是AI大模型)深度优化的专用路线,核心优势在于极致的性能和能效比。
总而言之,市场是通用性与专用性、生态兼容与性能极致之间的平衡,两大阵营各具优势,共同推动着国产算力产业的快速发展。
2. 市场份额:一超多强

国产AI芯片市场竞争格局已初步呈现 “一超多强” 态势。
🥇 华为昇腾 (领导者):市场份额 >70%。
- 凭借全栈自研生态(Ascend+MindSpore+CANN),其主力产品 昇腾910C 对标英伟达 H800。
- CloudMatrix 集群方案支持单节点384卡,成为国产替代首选。
🥈 第二梯队 (寒武纪 & 海光):
- 寒武纪:市场份额 >20%。凭借 FP8 低精度计算 的前瞻布局,在字节跳动等大厂大规模部署。
- 海光信息:依托 深算系列 DCU,在信创与科研领域增长强劲,GPU业务占总收入 20-40%。
🥉 细分挑战者:
- 沐曦、百度昆仑芯、阿里平头哥 等厂商在细分领域积极拓展,构建多层次竞争格局。
3. 竞争格局图谱
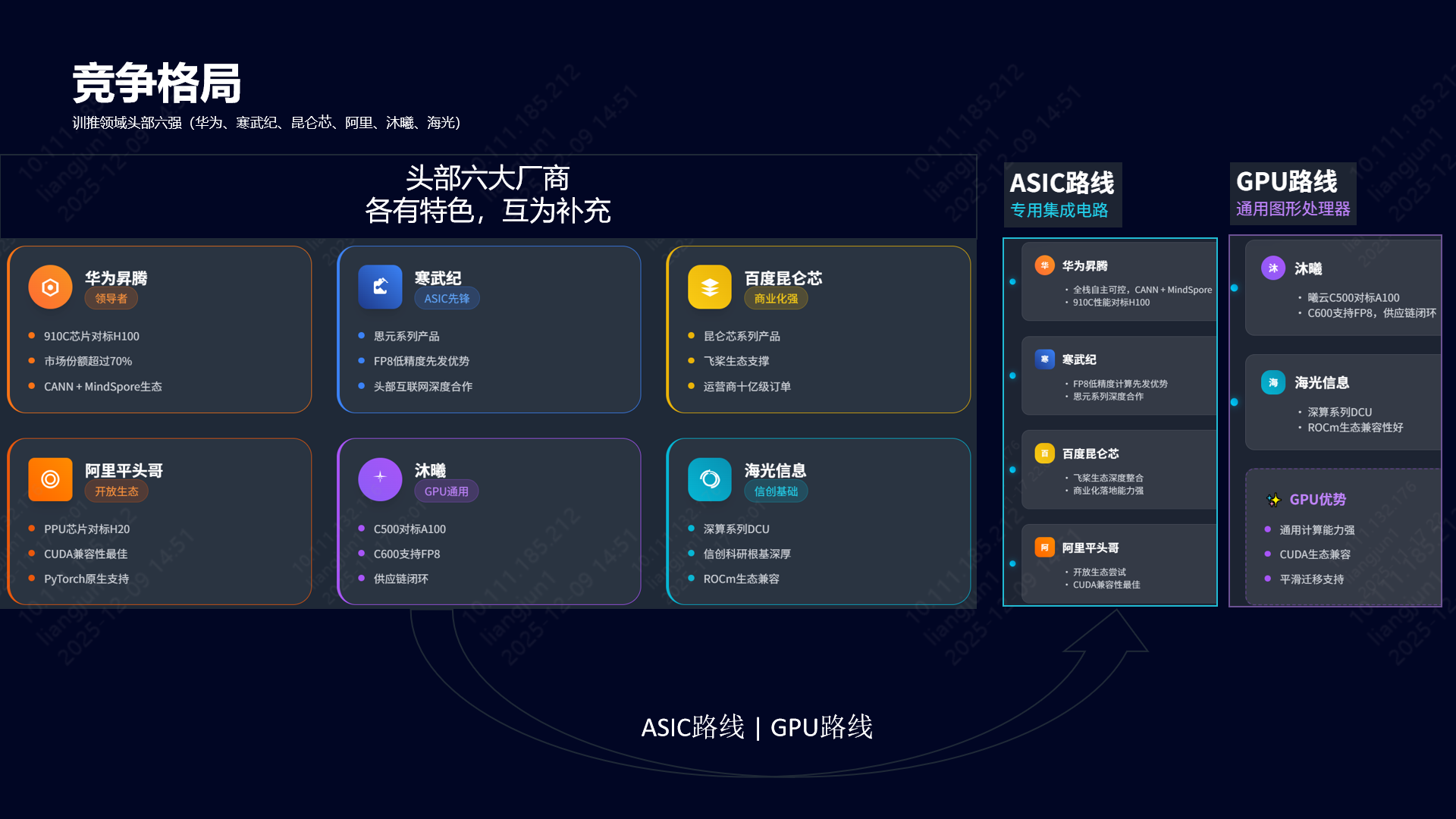
在AI大模型训练与推理领域,核心力量聚焦于六家主要企业:
- 全栈自研派:
- 华为昇腾:国产算力主力,910C + CANN 生态壁垒深厚。
- ASIC 先锋派:
- 寒武纪:FP8 先发优势,互联网大厂认可度高。
- 百度昆仑芯:依托百度飞桨生态,运营商集采表现亮眼。
- 阿里平头哥:PPU 性能对标 H20,探索开放生态。
- 通用兼容派:
- 沐曦:曦云 C500/C600 对标 A100,支持 FP8,主打国产供应链。
- 海光信息:ROCm 生态兼容,科研与信创领域基础稳固。
4. 主力厂商技术性能深度解析
4.1 华为 | 昇腾910C

- 定位:国产AI算力旗舰,对标 NVIDIA H800 (部分场景达 H100 的 60%)。
- 架构:达芬奇 (DaVinci) ASIC 架构。
- 性能:FP16 算力约 800 TFLOPS。
- 生态:CANN 异构计算架构 + MindSpore 框架,构建自主可控全栈方案。
- 亮点:
- CloudMatrix 集群:单节点 384 卡,支持万亿参数大模型训练。
- 软 FP8 技术:通过“软FP8”方案(如昆仑技术 Ascend C 实现),流畅运行 DeepSeek V3.1,实现“精度无损、成本减半”。
4.2 寒武纪 | 思元590/690系列
- 定位:互联网与云计算领域的大模型核心力量。
- 性能:
- 思元590:FP16 算力 314 TFLOPS。
- 思元690 (预计):FP16 算力跃升至 700-1000 TFLOPS,对标国际顶尖。
- 亮点:原生 FP8 支持。寒武纪是国内最早布局 FP8 的厂商之一,显存减半,效率倍增,完美适配 DeepSeek 等前沿模型。
4.3 阿里平头哥 | PPU (真武)
- 定位:阿里内部核心算力,支撑电商、云与AI业务。
- 性能:主要参数超越 NVIDIA A800,对标 H20。
- 亮点:与阿里云 PAI 平台深度集成,实现“芯-端-云”一体化。兼容 CUDA 与 PyTorch,代表 ASIC 阵营的开放尝试。
4.4 海光信息 | 深算 DCU (BW1000/BW100)
- BW1000:高端训练,8U 8卡,480 TFlops,64GB 显存,11KW 功耗。
- BW100:高能效推理,280 TFlops,64GB 显存,4KW 功耗,替代 K100-AI。
- 未来规划:2026年发布 BW1000B,直接对标 NVIDIA H20。
- 生态:基于 GPGPU 路线,兼容 ROCm,适合科学计算与通用 AI 任务。
4.5 沐曦 | 曦云 C500系列
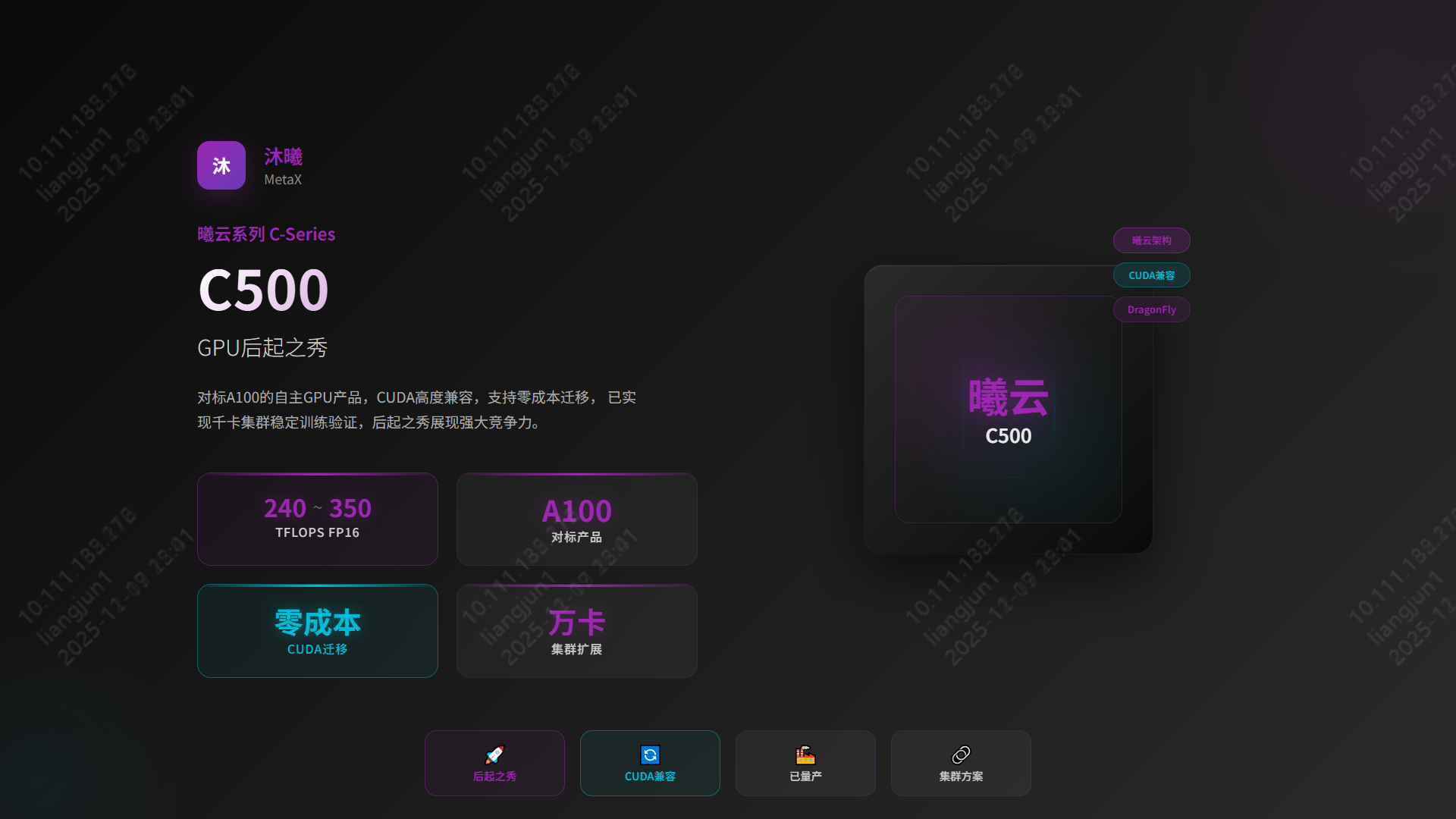
- 定位:对标 NVIDIA A100,FP16 算力 240-350 TFLOPS。
- 生态:MXMACA 软件栈 高度兼容 CUDA,实现“零成本”迁移。
- 集群:夸娥 (KUAE) 智算集群,支持从 2 卡到万卡规模扩展。
4.6 摩尔线程 | MTT S5000
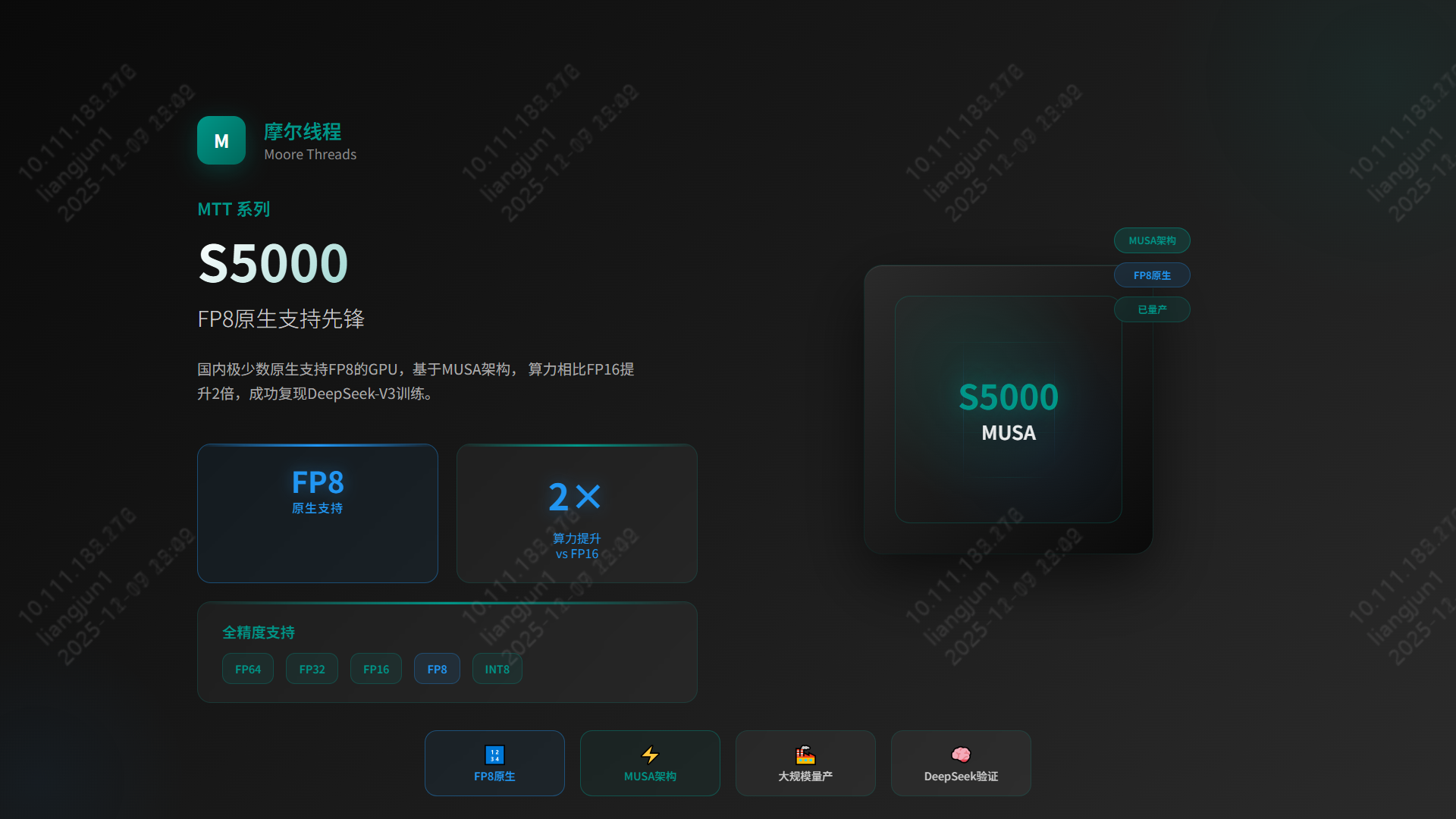
- 亮点:全功能 GPU,国内极少数原生支持 FP8。
- 性能:利用 FP8 算力提升 2 倍。全精度支持 (FP64 到 INT8)。
- 生态:MUSA 架构,配合 Torch-MUSA 和 MT-MegatronLM,成功复现 DeepSeek-V3 训练。
4.7 天数智芯 | 天垓/智铠系列
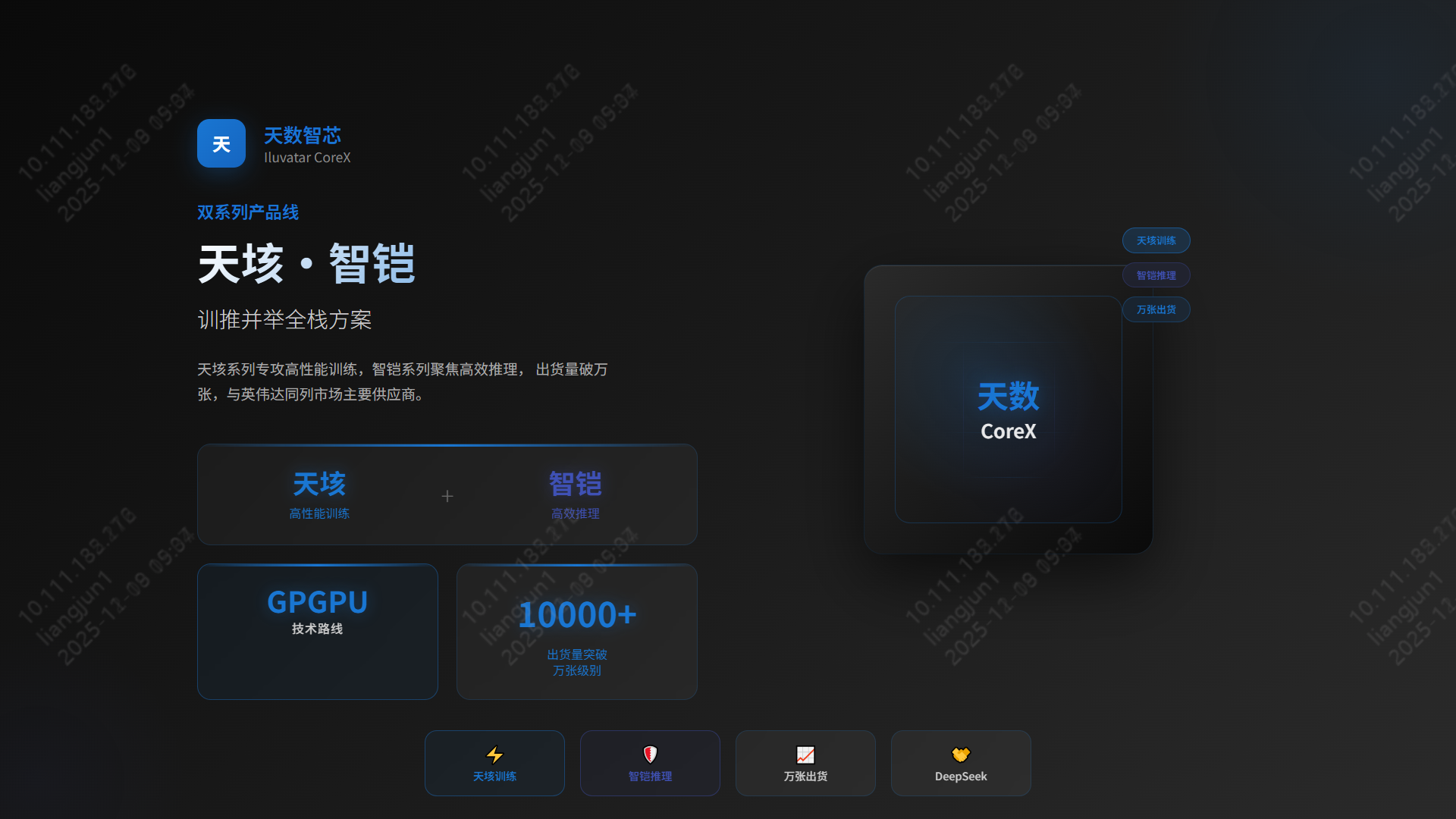
- 布局:天垓 (训练) + 智铠 (推理) 双轮驱动。
- 市场:2024年出货突破 10000张,商业化落地领先。
- 生态:GPGPU 路线,已适配 DeepSeek 等主流大模型。
5. 趋势展望:FP8 成为新焦点
2026年,FP8 (8位浮点数) 将成为国产 GPU 竞争的制高点。
📅 技术演进时间轴
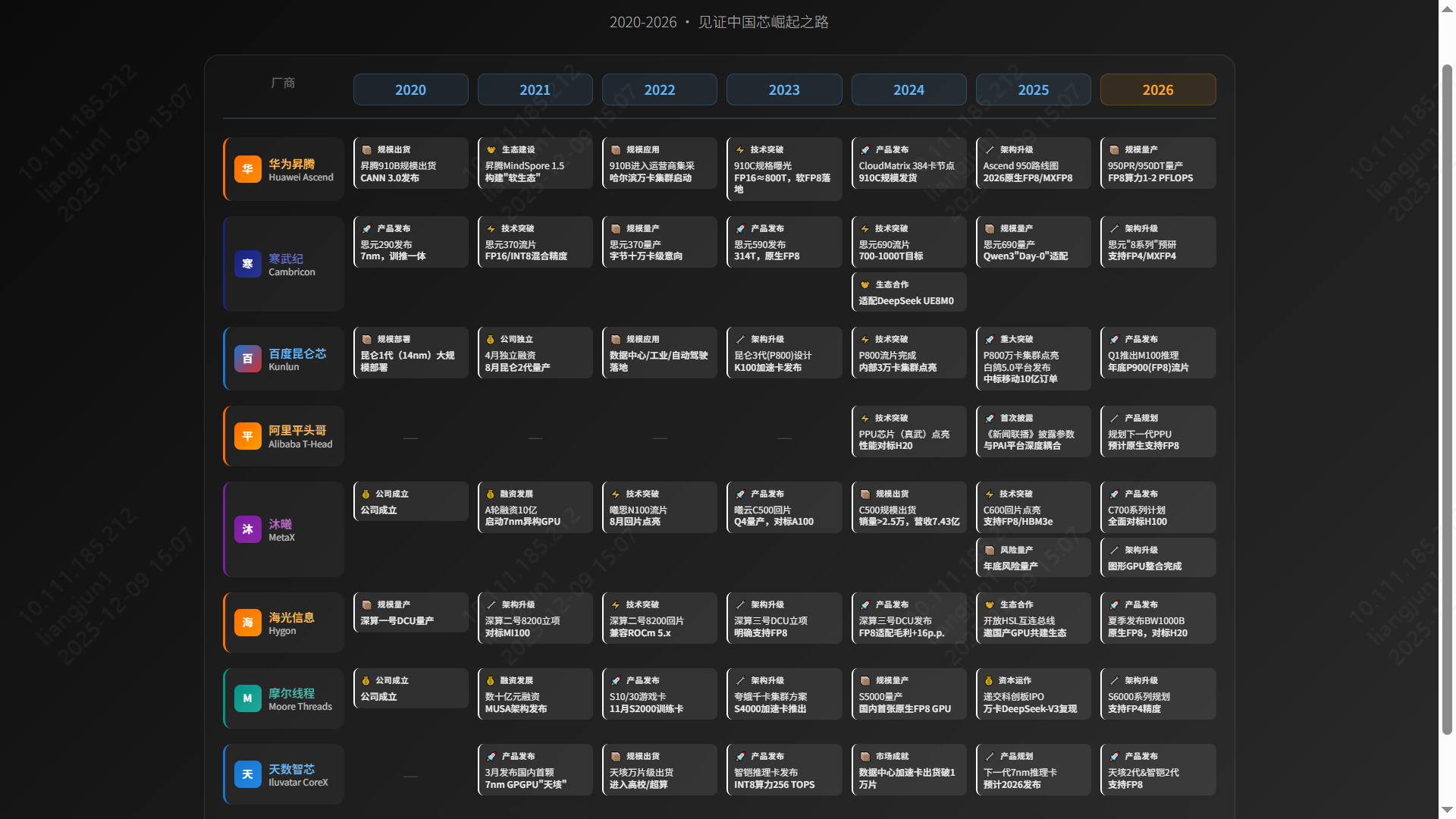
💎 FP8 的核心价值
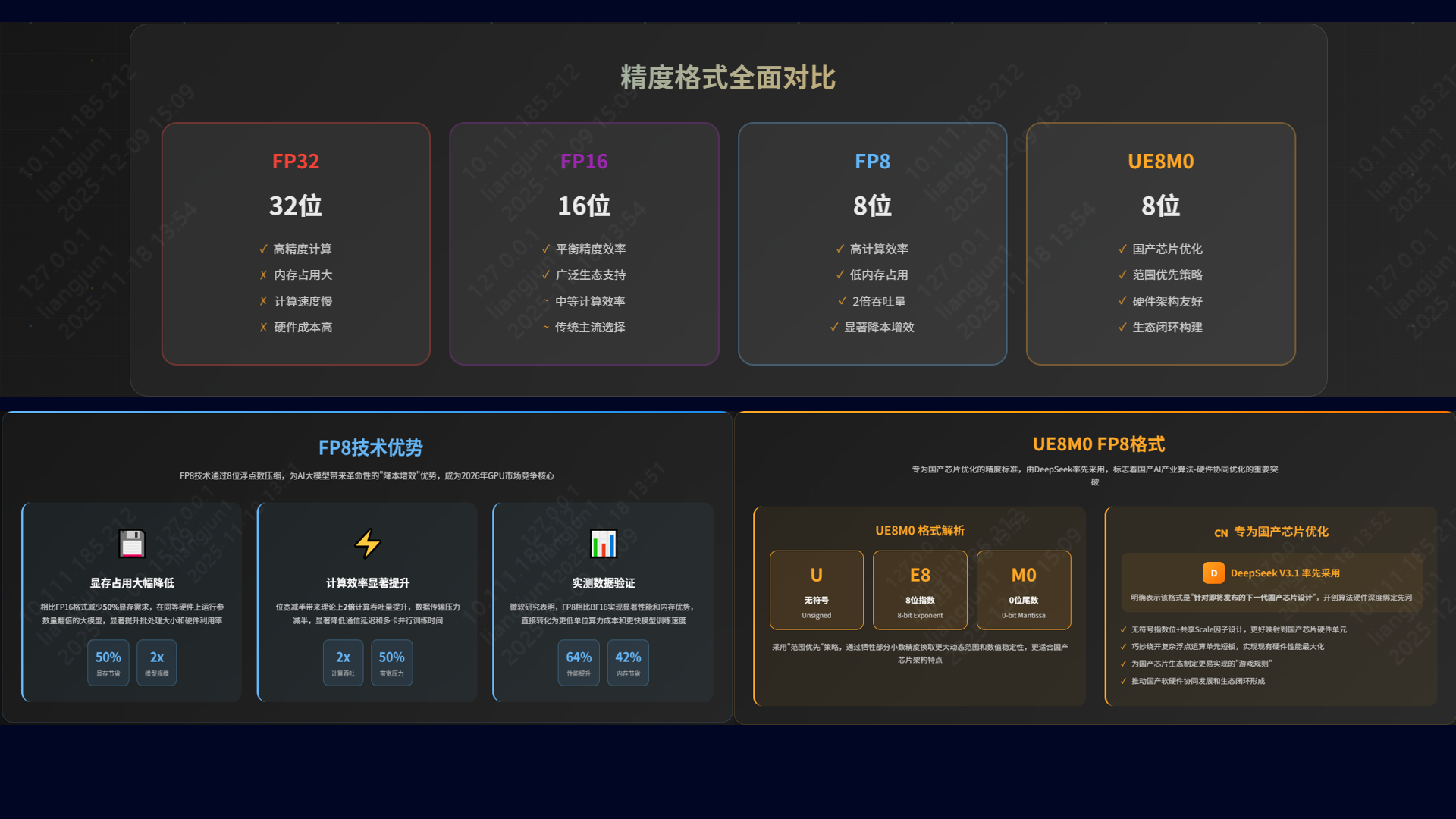
在大模型时代,FP8 带来了革命性的 “降本增效”:
- 显存占用减半:同等硬件可运行参数量翻倍的模型,或显著增加 Batch Size。
- 计算效率倍增:理论吞吐量翻倍,通信带宽压力减半。微软研究显示,FP8 相比 BF16 可提升 64% 性能 并节省 42% 内存。
6. 生态与适配:DeepSeek 与 Qwen 实战
⚡ DeepSeek V3.2 适配情况
国产厂商已实现 “Day 0” 级响应:

| 框架 | 华为昇腾 | 寒武纪 | 海光信息 |
|---|---|---|---|
| SGLang | ✅ 明确支持 | ⏳ 预计支持 | ✅ DCU 支持 |
| vLLM | ✅ 深度支持 | ✅ 开源 vLLM-MLU | ✅ 兼容支持 |
🧠 Qwen3 系列适配实战
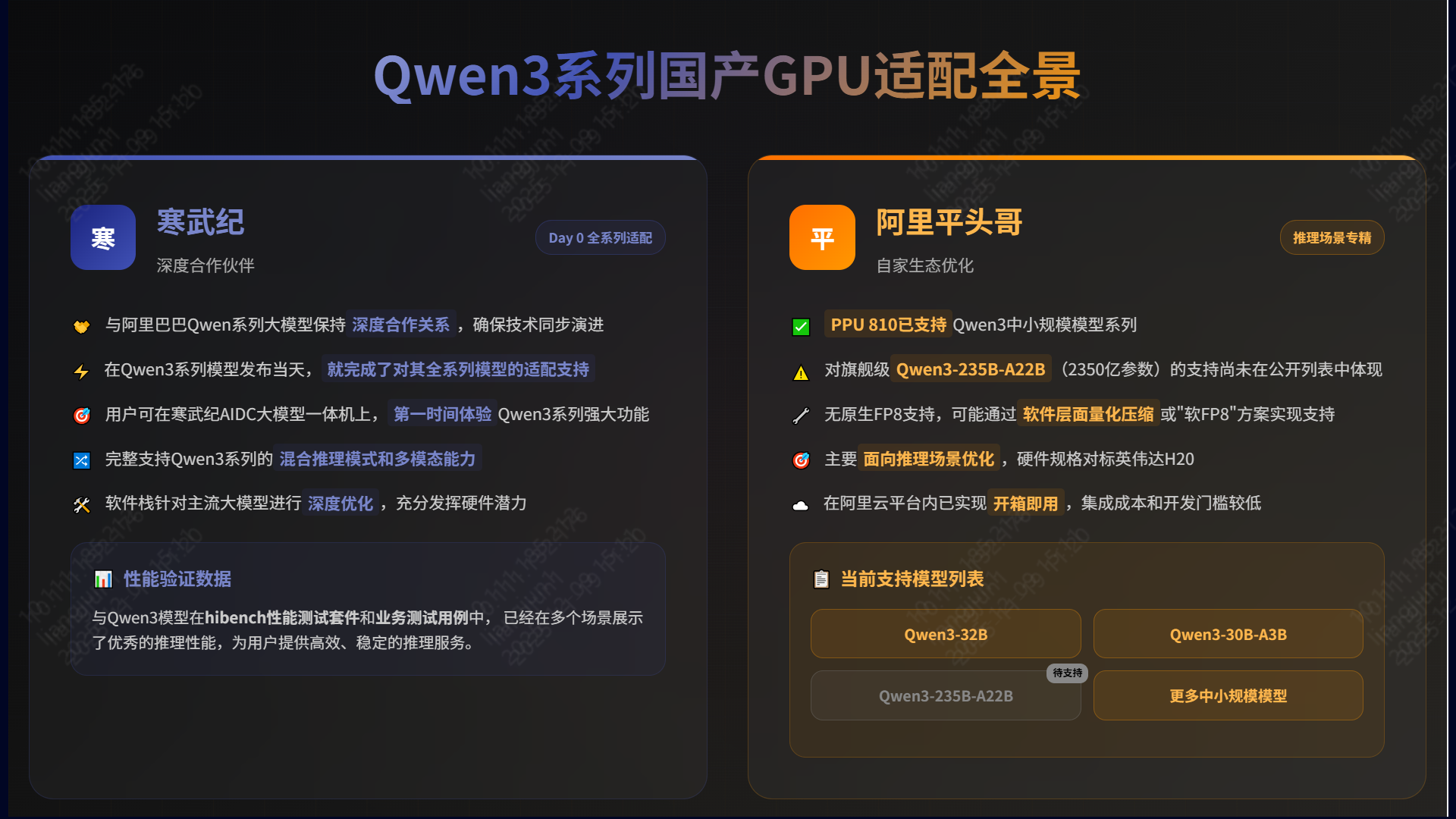
- 寒武纪:全系列适配。在 Qwen3 发布当天即完成适配,AIDC 一体机开箱即用,多场景推理性能优异。
- 阿里平头哥:深度集成。PPU 810 已支持 Qwen3 中小规模模型,虽无原生 FP8,但凭借 96GB HBM2e 显存和阿里云集成,在推理场景表现强劲。
🌏 国产替代生态全景
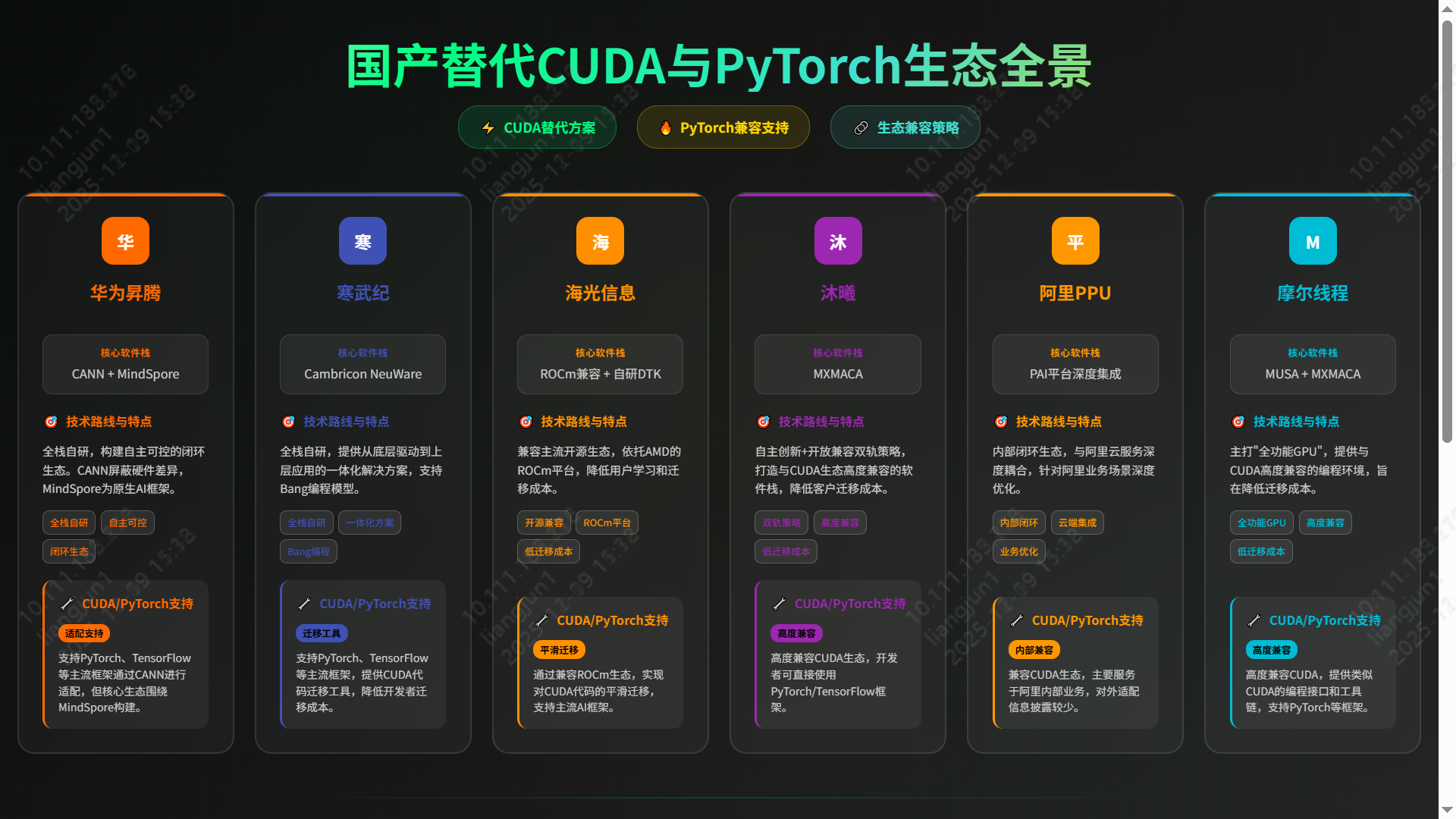
随着 CUDA 与 PyTorch 生态的兼容完善,以及自研框架的成熟,国产算力正逐步构建起自主可控的完整拼图。
Kubernetes上部署vLLM
1. vLLM Docker镜像与Kubernetes部署价值
vLLM是一个专为大语言模型推理设计的高性能服务框架,其核心优势在于创新的PagedAttention技术,能够显著提升GPU内存利用率和推理吞吐量。通过Docker容器化封装,vLLM实现了环境标准化和依赖隔离,而Kubernetes部署则进一步带来了:
- 弹性伸缩:根据负载自动调整副本数量
- 资源隔离:GPU资源的精细化管理和隔离
- 高可用性:自动故障恢复和负载均衡
- 简化运维:统一的部署、监控和管理界面
vLLM官方Docker镜像提供了开箱即用的模型服务环境,结合Kubernetes的编排能力,为生产级AI服务提供了坚实基础。
2. Qwen3-235B-A22B-Instruct-2507模型部署实践
2.1 从ModelScope下载模型
Qwen3-235B-A22B-Instruct-2507作为千问系列的最新大模型,首先需要从ModelSpace获取模型权重:
# 使用modelscope库下载模型
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen3-235B-A22B-Instruct-2507',
cache_dir='/workspace/models',
revision='v1.0.0'
)
对于Kubernetes环境,推荐使用初始化容器进行模型下载,确保模型文件在Pod启动前准备就绪。
3. vLLM服务配置与Kubernetes部署
3.1 vLLM启动参数优化
针对Qwen3-235B大模型,vLLM需要特定配置以充分发挥性能:
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.85 \
--max-model-len 131072 \
--served-model-name qwen3-235b \
--port 9997 \
--host 0.0.0.0 \
--trust-remote-code \
--dtype auto \
--enable-prefix-caching \
--enable-chunked-prefill \
--api-key sk-xxxxxxxxx \
--tool-call-parser hermes \
--enable-auto-tool-choice \
--swap-space 16 \
--disable-log-requests
关键参数说明:
- tensor-parallel-size 8:8路张量并行,充分利用多GPU资源
- gpu-memory-utilization 0.85:适中的GPU内存利用率,预留缓冲空间
- max-model-len 131072:支持128K上下文长度
- enable-prefix-caching:启用前缀缓存,提升推理效率
- enable-chunked-prefill:分块预填充,优化长文本处理
- swap-space 16:16GB交换空间,处理内存溢出
3.2 Kubernetes Deployment配置
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: vllm-qwen3-235b
nvidia.com/app: vllm-qwen3-235b
nvidia.com/framework: python
nvidia.com/unit: application
name: vllm-qwen3-235b
namespace: ai-serving
spec:
podManagementPolicy: OrderedReady
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: vllm-qwen3-235b
serviceName: vllm-qwen3-235b
template:
metadata:
annotations:
nvidia.com/use-gputype: A100,A800,H100,H800
nvidia.com/globalid: AIP_MDIS_QWEN3_235B
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976" # 8 * 79872
nvidia.com/model-uid: Qwen3-235B-A22B-Instruct-2507
labels:
app: vllm-qwen3-235b
type: llm
model-size: 235b
nvidia.com/app: vllm-qwen3-235b
nvidia.com/framework: python
nvidia.com/unit: application
nvidia.com/4pd-scheduler: "true"
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: accelerator
operator: In
values: ["nvidia-a100-80gb", "nvidia-a800-80gb", "nvidia-h100-80gb"]
- key: topology.kubernetes.io/zone
operator: In
values: ["zone-gpu-high"]
initContainers:
- name: download-model
image: download-model:latest
imagePullPolicy: IfNotPresent
command: ["sh", "-c"]
args:
- |
echo "开始下载Qwen3-235B模型..."
model_download /opt/app/models/ || {
echo "模型下载失败,尝试从备用源下载..."
exit 1
}
echo "模型下载完成,验证模型文件..."
ls -la /opt/app/models/
if [ ! -f "/opt/app/models/config.json" ]; then
echo "模型文件验证失败"
exit 1
fi
echo "模型文件验证成功"
env:
- name: S3_URL
valueFrom:
secretKeyRef:
key: S3_URL
name: vllm-qwen3-235b
- name: S3_AK
valueFrom:
secretKeyRef:
key: S3_AK
name: vllm-qwen3-235b
- name: S3_SK
valueFrom:
secretKeyRef:
key: S3_SK
name: vllm-qwen3-235b
- name: S3_BUCKET
valueFrom:
secretKeyRef:
key: S3_BUCKET
name: vllm-qwen3-235b
- name: USERNAME
value: "ai-platform"
- name: MODEL_NAME
value: "qwen3-235b"
- name: VERSION
value: "Qwen3-235B-A22B-Instruct-2507"
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
volumeMounts:
- mountPath: /opt/app/models
name: share-volume
containers:
- name: vllm-qwen3-235b
image: vllm/vllm-openai:v0.12.0
imagePullPolicy: IfNotPresent
command: ["/bin/bash"]
args:
- -c
- |
set -e
# 环境变量设置
export NCCL_SHM_DISABLE=1
export VLLM_ALLOW_LONG_MAX_MODEL_LEN=1
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export NCCL_IB_DISABLE=0
export NCCL_NET_GDR_LEVEL=2
# 创建日志目录
mkdir -p /log/logs
# 等待模型文件就绪
while [ ! -f "/opt/app/models/config.json" ]; do
echo "等待模型文件就绪..."
sleep 10
done
echo "启动vLLM服务..."
exec python3 -m vllm.entrypoints.openai.api_server \
--model=/opt/app/models \
--served-model-name=Qwen3-235B-A22B-Instruct-2507 \
--port=9997 \
--host=0.0.0.0 \
--trust-remote-code \
--dtype=auto \
--enable-prefix-caching \
--enable-chunked-prefill \
--tensor-parallel-size=8 \
--gpu-memory-utilization=0.85 \
--api-key=${API_KEY} \
--max-model-len=131072 \
--tool-call-parser=hermes \
--enable-auto-tool-choice \
--swap-space=16 \
--disable-log-requests \
--max-num-seqs=128 \
--max-paddings=256 \
> /log/logs/vllm-qwen3-235b.log 2>&1
env:
- name: ACTIVE_OOM_KILLER
value: "0"
- name: LIBCUDA_LOG_LEVEL
value: "0"
- name: GPU_CORE_UTILIZATION_POLICY
value: "disable"
- name: VLLM_WORKER_MULTIPROC_METHOD
value: "spawn"
- name: VLLM_LOGGING_LEVEL
value: "INFO"
- name: MODEL_UID
value: "Qwen3-235B-A22B-Instruct-2507"
- name: MODEL_TYPE
value: "chat"
- name: API_KEY
valueFrom:
secretKeyRef:
key: api-key
name: vllm-qwen3-235b
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- |
echo "正在优雅关闭vLLM服务..."
kill -TERM $(pgrep -f "vllm.entrypoints.openai.api_server") || true
sleep 30
ports:
- containerPort: 9997
name: api-port
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 3
initialDelaySeconds: 600
periodSeconds: 60
successThreshold: 1
timeoutSeconds: 30
readinessProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 3
initialDelaySeconds: 300
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
startupProbe:
httpGet:
path: /health
port: 9997
scheme: HTTP
failureThreshold: 30
initialDelaySeconds: 120
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 10
resources:
requests:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976"
limits:
cpu: "64"
memory: "256Gi"
nvidia.com/gpu: "8"
nvidia.com/gpumem: "638976"
volumeMounts:
- mountPath: /opt/app/models
name: share-volume
readOnly: true
- mountPath: /dev/shm
name: cache-volume
- mountPath: /etc/localtime
name: timezone-volume
readOnly: true
- mountPath: /log
name: log-volume
- mountPath: /tmp
name: temp-volume
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
runAsNonRoot: false
fsGroup: 0
terminationGracePeriodSeconds: 180
tolerations:
- effect: NoSchedule
key: role
operator: Equal
value: bigdata
- effect: NoSchedule
key: gpurole
operator: Equal
value: gpu
- effect: NoSchedule
key: model-size
operator: Equal
value: large
volumes:
- name: share-volume
persistentVolumeClaim:
claimName: vllm-qwen3-235b-model-pvc
- name: cache-volume
emptyDir:
medium: Memory
sizeLimit: 256Gi
- name: log-volume
hostPath:
path: /data/logs/vllm-qwen3-235b
type: DirectoryOrCreate
- name: temp-volume
emptyDir:
sizeLimit: 32Gi
- name: timezone-volume
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
type: FileOrCreate
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: 0
volumeClaimTemplates: []
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-qwen3-235b-model-pvc
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Ti
storageClassName: nfs-client
---
apiVersion: v1
kind: Service
metadata:
name: vllm-qwen3-235b
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
type: ClusterIP
ports:
- port: 9997
targetPort: 9997
protocol: TCP
name: api-port
selector:
app: vllm-qwen3-235b
---
apiVersion: v1
kind: Secret
metadata:
name: vllm-qwen3-235b
namespace: ai-serving
type: Opaque
data:
api-key: c2stdmxsbS1xd2VuMy0yMzViLWFwaS1rZXk= # base64编码的API key
S3_URL: <base64-encoded-s3-url>
S3_AK: <base64-encoded-access-key>
S3_SK: <base64-encoded-secret-key>
S3_BUCKET: <base64-encoded-bucket-name>
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-qwen3-235b-model-pvc
namespace: ai-serving
labels:
app: vllm-qwen3-235b
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Ti
storageClassName: nfs-client
3.3 存储与模型管理
通过PVC申请共享存储,确保模型文件持久化并可在多个Pod间共享。initContainer负责从S3对象存储下载模型到持久化存储,避免每次Pod重启重复下载。
4. Hami on K8S架构的GPU资源动态分配

4.1 HAMi简介与优势
HAMi(Heterogeneous AI Computing Virtualization Middleware) 是一个专为异构AI计算设备设计的虚拟化中间件,为Kubernetes集群提供强大的GPU资源管理能力。
核心优势
- 🔄 设备虚拟化:为多种异构设备提供虚拟化功能,支持设备共享和资源隔离
- 🚀 智能调度:基于设备拓扑和调度策略实现Pod间的设备共享和优化调度
- 🎯 统一管理:消除不同异构设备间的差异,提供统一管理接口
- 💡 零修改部署:无需对现有应用程序进行任何修改
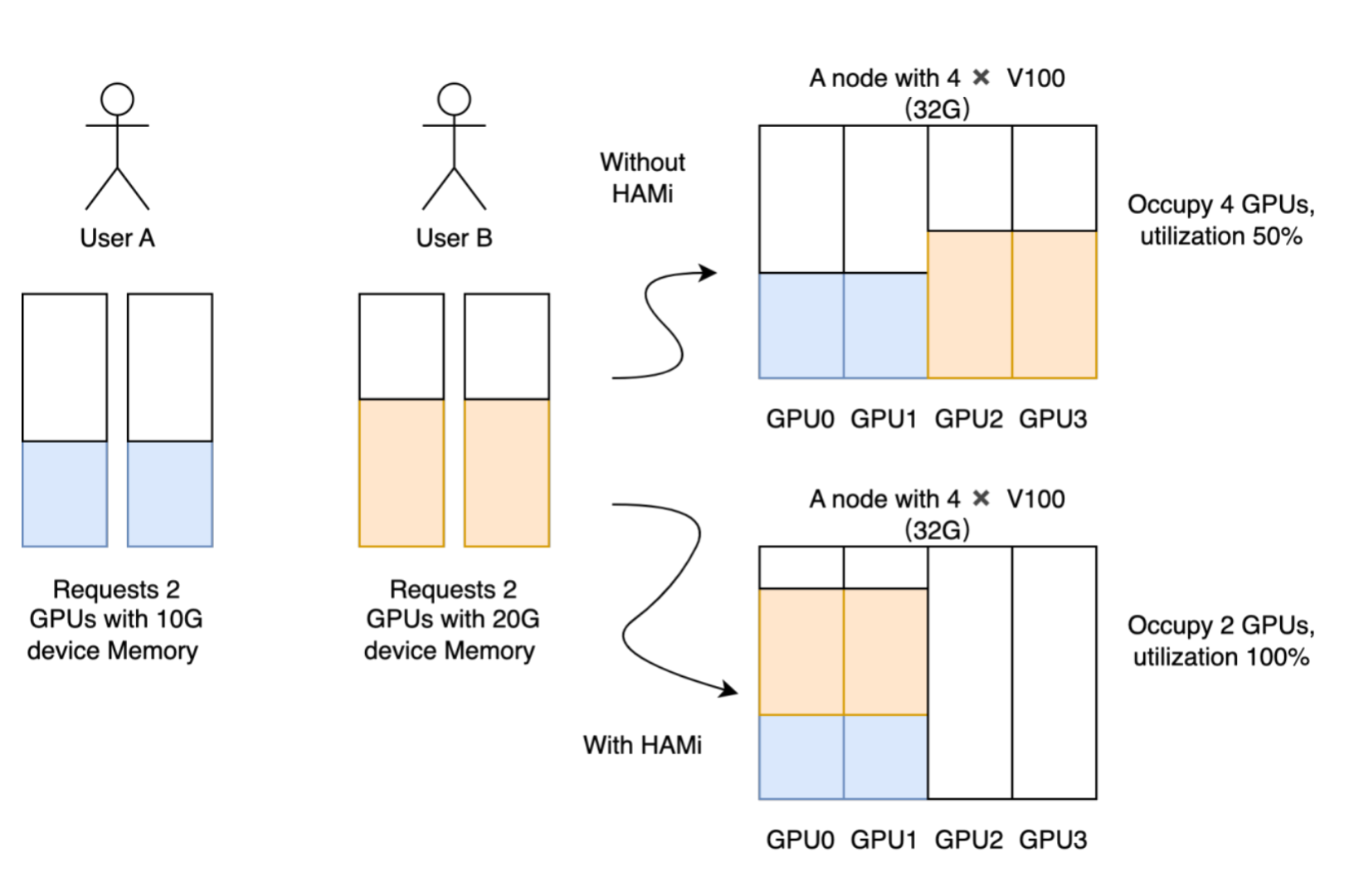
4.2 支持的异构设备
HAMi 2.7.1版本支持的设备类型如下:
| 设备厂商 | 设备类型 | 支持状态 | 备注 |
|---|---|---|---|
| NVIDIA | GPU | ✅ 完整支持 | 需要驱动 >= 440 |
| 寒武纪 | MLU | ✅ 完整支持 | - |
| 海光 | DCU | ✅ 完整支持 | - |
| 天数智芯 | GPU | ✅ 完整支持 | - |
| 摩尔线程 | GPU | ✅ 完整支持 | - |
| 昇腾 | NPU | ✅ 完整支持 | - |
| 沐曦 | GPU | ✅ 完整支持 | - |
📈 支持设备持续更新中,最新支持列表请查看 官方文档
4.3 HAMi安装部署
4.3.1 前置条件检查
在安装HAMi之前,请确保满足以下系统要求:
| 组件类别 | 组件名称 | 版本要求 | 详细说明 |
|---|---|---|---|
| GPU驱动 | NVIDIA驱动 | ≥ 440.x | • GPU计算节点必需安装 • 建议使用最新稳定版本 • 支持CUDA 11.0+ |
| 容器运行时 | nvidia-docker | ≥ 2.0 | • GPU容器化支持组件 • 必须配置为默认运行时 • 与Docker Engine配合使用 |
| 容器编排 | Kubernetes | ≥ 1.18 | • 集群管理平台 • 建议1.20+版本以获得更好的GPU调度支持 • 需启用GPU设备插件 |
| 容器引擎 | 容器运行时 | 兼容版本 | • 支持:containerd/docker/cri-o • 必须配置nvidia为默认运行时 • 确保与K8s版本兼容 |
| 系统库 | glibc | ≥ 2.17 且 < 2.30 | • GNU C标准库 • 版本范围严格限制 • 影响CUDA库兼容性 |
| 操作系统 | Linux内核 | ≥ 3.10 | • 最低内核版本要求 • 建议使用4.x+内核 • 确保驱动兼容性 |
| 包管理 | Helm | ≥ 3.0 | • Kubernetes包管理工具 • 用于部署GPU Operator • 建议使用最新稳定版 |
⚠️ 重要:确保容器运行时的默认运行时配置为nvidia
4.3.2 安装步骤
Step 1: 标记GPU节点
为需要GPU调度的节点添加标签:
kubectl label nodes {nodeid} gpu=on
💡 提示:只有带有
gpu=on标签的节点才能被HAMi调度器管理
Step 2: 添加Helm仓库
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm repo update
Step 3: 部署HAMi
helm install hami hami-charts/hami -n kube-system
Step 4: 验证安装
kubectl get pods -n kube-system | grep vgpu
期望输出:
vgpu-device-plugin-xxx 1/1 Running 0 2m
vgpu-scheduler-xxx 1/1 Running 0 2m
✅ 如果
vgpu-device-plugin和vgpu-schedulerPod都处于Running状态,则安装成功
4.4 自定义配置
HAMi支持通过修改 values.yaml 文件进行个性化配置。
4.4.1 资源名称自定义
# NVIDIA GPU 参数配置
resourceName: "nvidia.com/gpu" # GPU设备资源名
resourceMem: "nvidia.com/gpumem" # GPU内存资源名
resourceMemPercentage: "nvidia.com/gpumem-percentage" # GPU内存百分比
resourceCores: "nvidia.com/gpucores" # GPU核心数
resourcePriority: "nvidia.com/priority" # GPU优先级
4.4.2 企业级自定义示例
# 自定义为公司标识
resourceName: "company.com/gpu"
resourceMem: "company.com/gpumem"
resourceMemPercentage: "company.com/gpumem-percentage"
resourceCores: "company.com/gpucores"
📚 更多配置选项:详细配置参数请参考 官方配置文档
4.5 使用注意事项
在使用HAMi过程中,请注意以下重要事项:
| ⚠️ 重要提醒 |
|---|
| 设备暴露风险:如果使用NVIDIA镜像的设备插件时不请求虚拟GPU,机器上的所有GPU可能会在容器内暴露 |
| A100 MIG限制:目前A100 MIG仅支持 “none” 和 “mixed” 模式 |
| 调度约束:带有 “nodeName” 字段的任务目前无法调度,请使用 “nodeSelector” 代替 |
| 版本一致性:确保Kubernetes scheduler版本与hami-scheduler版本一致 |
4.6 最佳实践建议
📋 部署前检查
- 验证所有前置条件
- 确认GPU节点标签正确
- 检查版本兼容性
🔧 配置优化
- 根据企业需求自定义资源名称
- 合理配置资源限制
- 监控资源使用情况
🛡️ 安全考虑
- 避免不必要的GPU设备暴露
- 合理设置资源配额
- 定期更新组件版本
5. 服务访问与可扩展性演示
5.1 服务暴露与访问
通过Service和Ingress暴露vLLM服务:
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: ai-serving
spec:
selector:
app: vllm-qwen3-235b
ports:
- port: 9997
targetPort: 9997
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vllm-ingress
namespace: ai-serving
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: vllm.ai-serving.company.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vllm-service
port:
number: 9997
5.2 API调用示例
cURL 请求示例 非流式响应示例:
curl -X POST "http://vllm.ai-serving.company.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "qwen3-235b",
"messages": [
{
"role": "user",
"content": "解释机器学习的基本概念"
}
],
"max_tokens": 1000,
"temperature": 0.7,
"stream": false,
"enable_reasoning": true
}'
流式响应示例:
curl -X POST "http://vllm.ai-serving.company.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "qwen3-235b",
"messages": [
{
"role": "user",
"content": "解释机器学习的基本概念"
}
],
"max_tokens": 1000,
"temperature": 0.7,
"stream": true,
"enable_reasoning": false
}' \
--no-buffer
5.3 可扩展性演示
水平扩缩容演示:
# 手动扩展副本数应对流量高峰
kubectl scale sts vllm-qwen3-235b --replicas=2 -n ai-serving
监控与指标:
- GPU利用率监控自动触发扩容
- 请求延迟超过阈值时增加副本
- 基于Prometheus指标的自定义扩缩容策略
总结
Kubernetes上部署vLLM为大规模语言模型服务提供了生产级的解决方案。通过容器化封装、资源动态调度、存储持久化和自动扩缩容等特性,实现了高效、可靠且可扩展的AI模型服务架构。Qwen3-235B等大模型在该架构下能够充分发挥性能优势,为企业级AI应用提供强有力的支撑。
这种架构不仅适用于当前的大模型服务,也为未来更大规模的模型和服务需求提供了可扩展的基础设施保障,是构建现代化AI服务平台的最佳实践。