[i18n] print_printable_section [i18n] print_click_to_print.
实用工具
AgentMemory 开源:给 AI 编程 Agent 装上持久化大脑
每天都跟 Claude Code、Cursor 这些 AI 编程 Agent 打交道的人,大概率都遇到过同一个问题:每次开新会话,都得把项目背景重新交代一遍。 架构选型、目录结构、代码风格、踩过的坑——AI 什么都会,就是不会"记住"你。
最近 GitHub 上冒出一个叫 agentmemory 的开源项目,1.4 万+ Star,口号很直白:给你的 AI 编程 Agent 装上持久化大脑。它在 ICLR 2025 的 LongMemEval 基准测试中,R@5 命中率达到 95.2%,远超同类工具。

一、AI 编程的"失忆症"问题
用过 Claude Code 或 Cursor 的人都知道,每次开始新会话,Agent 对你的项目一无所知。常见的"上下文传递"方案有几种,但各有局限:
- 1CLAUDE.md / .cursorrules — 手动维护项目说明文件,但最多 200 行,容易过时,且每个 Agent 各写各的
- 2手动粘贴上下文 — 每次把架构文档、技术选型复制到对话中,token 消耗巨大,年成本可达 $500+
- 3LLM 压缩摘要 — 让模型自己总结上下文,仍然需要手动触发,且压缩质量不稳定
- 4全量加载到提示词 — 超过上下文窗口直接崩溃,不现实
这些方案的本质问题是一样的:上下文传递依赖人工,而 AI 的"失忆"是每会话一清零的硬伤。
二、三路融合检索:不止是关键词匹配
agentmemory 的检索系统不是简单的关键词匹配,而是走了一套成熟的混合检索方案:
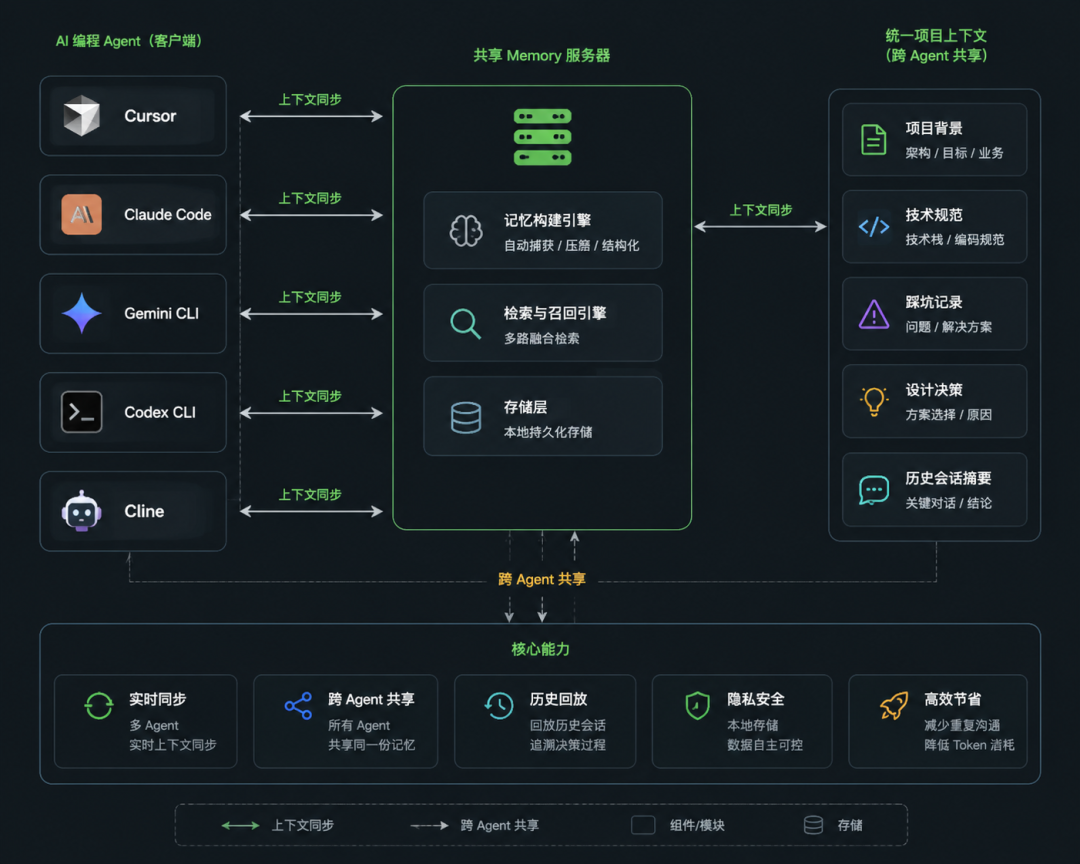
- BM25 — 传统关键词检索,速度快,适合精确匹配
- 向量检索 — 基于 all-MiniLM-L6-v2 本地嵌入模型,语义理解,无需 API Key
- 知识图谱 — 实体关系建模,理解代码之间的关联
三路结果通过 RRF(Reciprocal Rank Fusion) 排序融合,最终的检索质量远超单一方案。
对比数据来自 GitHub 官方 benchmark:
| 系统 | R@5 | R@10 | 备注 |
|---|---|---|---|
| agentmemory | 95.2% | 98.6% | BM25 + 向量 + 知识图谱三路融合 |
| BM25-only (fallback) | 86.2% | 94.6% | 仅关键词匹配 |
| mem0 (53K ⭐) | 68.5% | - | 被动记忆提取,需手动调用 |
| Letta / MemGPT (22K ⭐) | 83.2% | - | 需要 Postgres + 向量数据库 |
差距很明显。agentmemory 的优势不仅体现在准确率上,还在于它完全不需要外部基础设施。
三、架构设计:极简部署,零外部依赖
agentmemory 的底层架构非常克制,也是它能做到"一条命令启动"的关键原因。
npm install -g @agentmemory/agentmemory # 全局安装
agentmemory # 启动记忆服务器,默认 :3111
agentmemory connect claude-code # 接入 Claude Code
agentmemory connect cursor # 接入 Cursor

四层记忆整合机制 是它区别于其他工具的关键设计:
- 1短期记忆 — 当前会话的实时交互记录
- 2工作记忆 — 跨会话保留的重要上下文
- 3长期记忆 — 项目层面的技术规范、架构决策
- 4全局记忆 — 跨项目的通用模式与偏好
每层记忆带置信度衰减机制——久了没用的记忆会逐渐淡化,不会越堆越乱。这个设计很像人类的记忆模式:常被回忆的内容永远新鲜,早已遗忘的事情自然淡出。
四、实时可视化与回放
启动 agentmemory 之后,打开浏览器访问 http://localhost:3113,能看到实时记忆构建的仪表盘:
最有意思的功能是 会话回放(Replay)——每一次 Agent 交互都被记录下来,可以通过时间轴逐帧回放:提示词、工具调用、执行结果、模型回复,全部可查。支持 0.5×~4× 变速播放,排查问题极为方便。
如果你之前有过 Claude Code 的 JSONL 转录文件,也可以直接导入:
# 导入所有 ~/.claude/projects 下的历史会话
npx @agentmemory/agentmemory import-jsonl
# 导入单个文件
npx @agentmemory/agentmemory import-jsonl ~/.claude/projects/my-project/abc123.jsonl
五、Agent 生态覆盖
agentmemory 支持的 Agent 类型覆盖了当前主流的 AI 编程工具生态:
| Agent | 接入方式 | 说明 |
|---|---|---|
| Claude Code | 原生插件 + 12 个 Hook + MCP | 支持最完善 |
| Codex CLI | 原生插件 + 6 个 Hook + MCP | OpenAI 官方 |
| Cursor | MCP 服务器 | 主流 IDE 集成 |
| Gemini CLI | MCP 服务器 | Google 出品 |
| Cline | MCP 服务器 | VS Code 插件 |
| OpenClaw | 原生插件 + MCP | 支持完整 |
| Aider | REST API | 终端工具 |
| Windsurf | MCP 服务器 | 新一代 IDE |
所有 Agent 共享同一个记忆服务器,上下文完全打通。
六、成本与效率
这是最让人意外的地方——agentmemory 的 token 开销极低。
| 方式 | 年 Token 量 | 年成本 |
|---|---|---|
| 每次手动粘贴全量上下文 | 1950 万+ | 超出上下文窗口 |
| LLM 自动摘要 | ~65 万 | ~$500 |
| agentmemory(默认) | ~17 万 | ~$10 |
| agentmemory + 本地向量 | ~17 万 | $0 |
七、快速上手
# 安装
npm install -g @agentmemory/agentmemory
# 启动记忆服务器
agentmemory
# 接入 Agent
agentmemory connect claude-code
agentmemory connect cursor
# 启动演示(3 条会话 + 召回验证)
agentmemory demo
# 打开仪表盘
# → http://localhost:3113
安装完成后,agentmemory demo 会注入 3 个真实的会话样本(JWT 认证配置、N+1 SQL 优化、限流策略实现),然后你可以用语义搜索来验证召回效果——比如搜"数据库性能优化",它会把 N+1 查询修复的上下文找出来,纯关键词匹配做不到这一点。
写在最后
对于每天跟 AI 结对编程的人来说,agentmemory 解决了一个长期被忽视的基础设施问题——Agent 的上下文持久化。它不需要你改变工作流程,不需要引入外部数据库,一条命令装好就能用。
当你经历这样一个时刻:新开一个会话,Agent 自动知道你的项目用 jose 而不是 jsonwebtoken、知道你的测试覆盖了哪些边界情况、知道上周刚修复的那个 bug 的根因——你就再也回不去了。
GitHub:github.com/rohitg00/agentmemory
官网:agent-memory.dev
npm:@agentmemory/agentmemory
装上试试,让 Agent 有记忆是什么体验,用了就回不去了。
GPT Image 2 生成舞蹈大片:3 套完整分镜提示词(敦煌/洛神/苗族银饰)
AI 图像生成已经不只是"画一张图"了。用 GPT Image 2,你可以在一个画面中生成长达 16 帧的舞蹈分镜,每帧动作连贯、人物一致、场景统一,直接可作为视频生成的分镜参考。
这篇文章整理了 3 套完整可复用的 GPT Image 2 舞蹈分镜提示词——敦煌反弹琵琶舞、洛神水舞、苗族银饰舞——每套都包含完整的场景设定、人物设定、服装妆造和 16 帧动作分镜。直接复制即可使用。

一、GPT Image 2 的舞蹈生成能力
GPT Image 2 在处理复杂构图方面相比前代有了质的飞跃。它不仅能理解"一个人跳舞"这种笼统描述,更能精确解析:
- 16 宫格分镜排版 —— 4×4 网格,每格独立画面但保持整体一致性
- 同一人物一致性 —— 多帧画面中保持相同的面孔、服装、气质
- 连续动作逻辑 —— 从起势到高潮再到收尾,动作序列有明确的递进关系
- 文化符号识别 —— 敦煌壁画、苗族银饰、洛神赋等文化元素精准还原
二、案例一:敦煌反弹琵琶舞
敦煌石窟场景 · 反弹琵琶经典动作 · 电影感灯光
这套提示词重现了敦煌壁画中最具辨识度的"反弹琵琶"舞姿,场景设定在敦煌石窟壁画长廊中,暖金余晖 + 洞窟暖光,色彩以赭石、土红、青绿、矿物蓝、金色为主。

完整提示词
请创作一张高完成度、超高清、清晰通透、写实且富有电影感的「敦煌反弹琵琶舞·16宫格分镜图」。
【整体定位】
这不是普通古风写真,也不是简单舞蹈教学图,而是一张融合「敦煌乐舞」「反弹琵琶经典动作」「石窟壁画空间」「16步编舞分镜」「电影感镜头设计」的高完成度分镜海报。
整张图像一段完整的敦煌反弹琵琶舞被拆解成16个关键动作画面,每一格既独立成立,又具有连续流动感、文化识别度和明显动作层次,适合后续作为视频生成分镜参考。
【场景设定】
不要现代舞台,不要空背景,不要摄影棚,不要普通古风室内。
场景必须是一个真实、优美、具有敦煌壁画气质的空间:
* 敦煌石窟前殿 / 壁画长廊 / 佛龛光影空间
* 墙面可见壁画纹样、拱门、佛龛、石窟肌理
* 整体有暖金余辉、洞窟暖光、轻微光尘
* 主色调为赭石、土红、青绿、矿物蓝、金色
* 空间有前景、中景、后景,层次清晰,具有纵深感
* 整体氛围神圣、华美、沉静、带壁画复活感
【人物设定】
主角是一位年轻成年中国女舞者,气质端庄、灵动、神圣、优雅,像敦煌乐舞天女。
在16格中保持同一张脸、同一人物、同一气质、同一套服装体系。
【服装与妆造】
服装为敦煌风乐舞服:高腰长裙、飘逸披帛、敦煌风大袖或轻纱袖,配色以赭石、敦煌红、青绿、金色、少量孔雀蓝为主。一把琵琶是核心道具,必须清晰可见。披帛、裙摆、袖摆都要有真实动态。
【版式要求】
* 4×4 的16宫格排版,每格有编号 1-16
* 每格有中文动作标题
* 干净、清晰、信息完整但不过度拥挤
* 分辨率极其高清
【动作分镜顺序】
1. 壁画初醒:舞者立于石窟长廊中央,手持琵琶,身体微侧,披帛垂落
2. 抱琵琶起势:将琵琶抱于身前,双臂柔和弧线,头部微偏
3. 侧身拨弦:侧身,一手扶琵琶一手拨弦,披帛被带起
4. 回眸开乐:回头的瞬间,身体和视线形成反向张力
5. 披帛扬起:转动身体,披帛和裙摆被带起
6. 低位献乐:下到低位,一手托琵琶一手向上延展
7. 起身扬帛:从低位起身,披帛向上扬起,琵琶顺势抬高
8. 半旋抱乐:半圈转身,披帛与裙摆流动
9. 反身初现:身体开始反扭,进入反弹琵琶前奏
10. 反弹琵琶:经典核心动作,琵琶置于背后,极具辨识度的敦煌姿态
11. 旋身奏乐:从反弹姿态回转,带动琵琶与披帛一起旋转
12. 飞袖绕乐:扬起披帛和长袖,乐器+飞袖的华丽共同构图
13. 半跪拨弦:半跪低位,神态沉静
14. 托乐望月:琵琶举高,头部向上望,如向天献乐
15. 反弹琵琶大定格:整套最高潮的反弹琵琶高光姿态
16. 壁画归位:最终收于壁画式定格,像重新定格成壁画
【重点要求】
* 保持同一舞者一致性
* 突出琵琶、披帛、反身、回旋、献乐、定格等核心元素
* 每格动作都要明显不同
* 写实、华美、敦煌感强、文化识别度高
视频生成提示词
同样的分镜还可以直接用来生成 视频。以下是与上述分镜配套的视频生成提示词:
请根据16宫格参考图,生成一段高完成度的「敦煌反弹琵琶舞」视频。
核心要求:严格按照画面1到画面16的顺序依次生成。整体不是普通古风写真,不是舞台表演,而是一位女舞者在敦煌石窟空间中完成的一段华美敦煌乐舞。
动作:真人舞者真实可完成,重点表现抱乐、拨弦、回眸、低位献乐、反弹琵琶、大定格等。动作流畅丝滑、层层递进。
镜头:稳定优雅流动。有缓慢推进、中近景停顿、小幅环绕、低机位、180度环绕,高潮段有完整360度环绕。大部分时间展示全身,情绪点适当中近景。
灯光:暖金余晖、洞窟暖光、壁画反射光和少量光尘。整体色调赭石、土红、青绿、矿物蓝、金色。干净通透,高级自然。
三、案例二:洛神水舞
洛神赋意境 · 镜面倒影 · 水墨东方美学
以曹植《洛神赋》为灵感,将洛神凌波微步、翩若惊鸿的姿态转化为 16 帧分镜。场景设定在月夜水岸,镜面浅水、远山薄雾、亭台石阶,倒影与实景相互映照。

完整提示词
请创作一张高完成度、超高清的「洛神水舞 · 16宫格分镜图 / Luo Shen Water Dance 16-Step Storyboard」。
【整体定位】
融合「洛神赋意境」「月夜水岸」「水袖长纱」「16步编舞」「电影感构图」的高完成度分镜海报。
像一段洛神水舞被拆解成16个关键动作画面,适合后续视频生成分镜参考。
【场景设定】
不要黑色舞台,不要摄影棚,不要现代室内。
场景必须是优美、有东方水墨气质的月夜水岸空间:
* 镜面浅水 / 水岸石台
* 远景可见远山、薄雾、亭台
* 月光洒落水面,有倒影
* 主色调为月白、浅蓝、青灰、水绿、暖灯
* 有前景、中景、后景,层次清晰
* 整体氛围优美、梦幻、有诗意
【人物设定】
主角是一位年轻成年中国女舞者,气质典雅、仙气、轻盈。
保持同一张脸、同一人物身份、同一气质、同一套服装体系。
【服装与妆造】
服装为洛神赋风格水袖长纱舞服:
* 月白色和浅蓝色渐变长裙
* 薄纱披帛和轻纱长袖
* 发饰为半挽发或飘逸长发 + 精致头饰
* 可带少量珍珠或水纹元素配饰
* 裙摆适合水面拖曳和旋转
【版式要求】
* 4×4的16宫格分镜排版
* 每格有编号 1-16 和中文动作标题
* 干净、清晰、信息完整但不过度拥挤
【动作分镜顺序】
1. 水岸亮相:舞者立于浅水边缘,微侧身,一手轻垂,一手微抬,倒影清晰
2. 提纱起势:双臂缓缓抬起,披纱和轻袖被带起,像水面微波
3. 拂水探身:身体向前轻探,一只手向下拂过水面,另一手向后展开
4. 回袖开流:双臂向两侧展开,轻纱沿身体两侧流开
5. 侧步水行:沿浅水边轻移步,裙摆和纱拖出轨迹
6. 低身拂波:下到低位,一手向下扫过水面,一手高举
7. 起身扬纱:从低位起身,双臂向上扬起,轻纱与裙摆一起带动
8. 回身流转:回身转向侧后方,轻纱绕出弧线
9. 长袖探月:一手高举如探月,一手展开,身体拉长
10. 旋裙开波:一次较大的旋转,裙摆与披纱像水纹扩散
11. 水面回旋:在浅水继续回旋,倒影一起形成完整画面
12. 腾步掠波:小跃步或掠步,纱与裙摆向后扬起
13. 半跪回眸:落入半跪姿态,轻轻回眸
14. 托水举纱:双手向上托举,纱被拉成柔和弧线
15. 神女大旋:整套最高潮,最完整华美的大旋
16. 洛神定格:一臂高举,一臂舒展,身体微扭,裙摆落下,倒影安静
【重点要求】
* 保持同一舞者一致性
* 突出水、纱、倒影、旋转、拂水等核心元素
* 每格动作明显不同
* 写实与梦幻相结合,东方美学风格
* 所有动作真人可完成
四、案例三:苗族银饰舞
银饰动态 · 民族盛装 · 脚步节奏
苗族银饰舞的特点是银饰的动态感——银冠、项圈、胸牌、腰链随着舞者的脚步、肩颈律动产生清脆的撞击声和摆动轨迹。这套提示词将这种特色完整还原到 16 帧分镜中。

完整提示词
请创作一张高完成度、超高清、清晰通透的「苗族银饰舞 · 16宫格分镜图 / Miao Silver Dance 16-Step Storyboard」。
【整体定位】
这不是普通民族写真,而是一张融合「苗族银饰舞」「真实苗寨场景」「16步编舞分镜」「电影感构图」的高完成度分镜海报。每一格连成一条流畅、节奏感强、银饰动态明显的舞蹈轨迹。
【场景设定】
不要黑色舞台,不要现代摄影棚。
傍晚苗寨木楼前广场 / 石板地
* 吊脚楼、木栏杆、远山和山雾
* 暖色灯火或火塘光
* 背景层次清楚(前景、中景、后景)
* 整体氛围优美有真实感
【人物设定】
年轻成年中国女舞者,苗族银饰舞者气质,灵动、优雅、有力量感。
保持同一张脸、同一人物、同一套服装体系。
【服装与妆造】
苗族银饰舞风格盛装:
* 银冠头饰明显夸张精致
* 银项圈、银胸牌、银链、耳饰、手饰丰富
* 深蓝/靛蓝/黑蓝色调的民族刺绣裙装
* 裙摆层次丰富,适合旋转摆动
* 银饰、裙摆必须随动作产生真实动态
【画面风格】
* 真实民族舞表演感,银饰动态明显
* 脚步、肩颈、手臂、裙摆节奏清楚
* 电影分镜感、舞蹈编排感
* 所有动作像真人舞者真实可完成
【版式要求】
* 4×4的16宫格分镜排版,每格编号 1-16
* 每格有中文动作标题
* 干净清晰,不过度拥挤
【动作分镜顺序】
1. 银冠亮相:舞者站在苗寨木楼前,一手轻扶银饰胸牌,一手自然打开
2. 踏步起铃:脚下轻踏两拍,肩颈带动银饰轻晃,双手缓缓抬起
3. 翻腕开臂:双手翻腕从胸前向两侧展开,身体微微侧摆
4. 侧踏摆裙:向侧方大步踏出,裙摆被带起,一手高扬一手展开
5. 肩颈摇银:肩膀连续轻抖,银冠、项圈、胸饰一起晃动
6. 环步绕身:脚下走环步,身体绕半圈,双臂展开
7. 抬臂转身:一手高举一手低开,优雅转身,银饰和裙摆甩出动态
8. 交叉踏步:双脚交叉切换,双手随节奏摆动,身体有弹性
9. 低身扫摆:下到半蹲低位,一手向下扫过裙摆
10. 起身扬银:从低位起身,胸饰和银链随动作明显上扬
11. 旋裙开幅:大旋转,裙摆完整打开,所有银饰动态明显
12. 踏鼓快步:连续快速踏步,身体微前倾,节奏感强
13. 回身甩饰:回身,银饰与头饰流苏被甩出
14. 大开祭舞:双臂大幅打开,身体向上拉长
15. 银铃大旋:最终大旋转,所有银饰形成最强动势——整套高潮
16. 苗岭定格:一手高举,一手横于胸前,裙摆落下,银饰轻晃
【重点要求】
* 突出银饰动态、裙摆动态、脚步节奏、肩颈律动
* 保持同一舞者一致性
* 每格动作明显不同
* 场景有民族氛围但不喧宾夺主
* 所有动作真人可完成
五、使用技巧与最佳实践
制作高质量舞蹈分镜的要点
- 元设定先行:先明确这张图的"定位"——是什么、不是什么。告诉模型"这不是普通古风写真,不是舞台表演",能有效减少偏差
- 人物一致性写清楚:明确要求"保持同一张脸、同一人物身份、同一气质、同一服装体系",避免每格像换了一个人
- 动作序列要有叙事弧:从亮相→起势→展开→高潮→回落→收尾,16 帧其实是一个微型故事
- 细节要具体:“一手轻扶银饰胸牌"比"在跳舞"有效一万倍
- 不要的也说清楚:“不要仙侠特效,不要悬浮,不要魔法光效"等负面提示有时候比正面提示更重要
从图片到视频
这套分镜图的核心价值在于:它不仅仅是 16 张图,而是一个视频分镜脚本。三套提示词都参考了视频生成,你可以:
- 用 GPT Image 2 生成 16 宫格分镜图
- 用配套视频提示词(如敦煌案例中的视频生成提示词)生成完整舞段
- 分镜图中的 编号 + 动作标题 直接对应视频中的镜头顺序
AI 图像生成正在经历从"画得好看"到"理解编排"的跃迁。这套舞蹈分镜提示词展示了 GPT Image 2 在
连续动作理解、人物一致性保持、文化符号还原三个维度上的能力边界。
三套提示词可以直接复制使用,也可以在文末评论分享你的生成结果。
更多 AI 绘画技巧,欢迎收藏关注。
GPT Image 2 提示词工程:12 套模板,从入门到精准出图
GPT Image 2 用的是另一种语言——不是关键词标签,是设计师和艺术总监互相交代任务时的"创意简报"语言。一旦理解这个转变,出图就不再靠抽卡碰运气。
如果你是 API 调用用户,之前的文章《1.8k Star 的 GPT Image 2 提示词仓库,7 个能直接抄的 prompt 》介绍了社区提示词仓库;本文则从底层原理出发,给出更完整的模板体系和工程化方法。
一、万能公式:六要素
无论做什么类型的图,所有高水准的提示词都遵循同一套骨架:
| 要素 | 描述 | 示例 |
|---|---|---|
| 载体 (Artifact) | 先给作品定性——是海报、产品实拍还是角色设定图 | “一张电影海报”、“影棚产品摄影” |
| 主体 (Subject) | 画面里是谁或什么 | “一位 28 岁的女性爵士乐手” |
| 场景 (Scene) | 时间、地点、正在发生什么 | “黄昏时分的纽约屋顶,吹奏萨克斯管” |
| 细节 (Detail) | 纹理、材质、氛围、具体道具 | “磨损的帆布围裙,双手布满老茧” |
| 约束 (Constraint) | 取景方式、构图要求、排除的元素 | “35mm 镜头,禁止平光,禁止卡通感” |
| 风格 (Style) | 胶片型号、插画风格、时代感参考 | “Kodak Vision3 500T,浅景深” |
二、文字精准渲染的解法
GPT Image 2 是目前少数能精准渲染画面文字的图像模型。触发方式:
- 1文案放在双引号或全大写中
- 2不常见的品牌名逐字母拼写
- 3提示词末尾加上
verbatim — no extra characters(原样输出,不得有额外字符)
这三步组合,能解决 80% 的文字乱码问题。
三、12 套模板,覆盖主流场景
01 纪实摄影:消除 AI 感的终极解法
过度磨皮、光影过亮——AI 生成的照片为什么一眼看穿?因为缺少人性化细节。秘诀是加入一个具体的物理细节,让画面感觉是"被观察到的"而非生成的。
一张彩色纪实摄影照片,描绘了【主体】在【具体地点和时间】正在【具体动作】。 【氛围细节:天气、水汽、灰尘或光影质感】。背景:【表面材质与纹理】。 细节:【一个人性化特征——磨损的靴子/手上的面粉/寒冷空气中呼出的白气】。 使用 35mm 镜头拍摄。仅限自然光。带有轻微胶片颗粒感。无后期加工痕迹。

02 电影感人像:让图有"贵感"
适用于英雄特写、社论人像、活动大片,或任何需要"昂贵感"的场景。
一张电影感高分辨率【人像/动作捕捉】,【主体】在【地点】【做动作】。 【灯光描述:色温、方向、质感】。焦点锐利,对准【脸部/核心元素】。 【胶片/风格参考】。反向约束:禁止卡通感,禁止平光,禁止廉价素材图既视感。

03 产品英雄位实拍:电商广告直出
适用于电商、方案演示、通讯稿或广告。GPT Image 2 在能准确描述表面材质和灯光的情况下,不同轮次的生成高度一致。
影棚产品摄影,【产品】悬浮在【表面】之上。影棚灯光:左上方柔和主光,右侧微妙补光, 干净的投影。背景:【白色/渐变/质感材质】。产品整体焦点清晰。 标签文字:"【标签内容】" verbatim — no extra characters。商业摄影,专业精修。

04 品牌视觉规范页
GPT Image 2 可以在单页内呈现一整套设计规范。只要结构描述清晰,它完全可以胜任。
一份为【品牌名】设计的专业单页品牌视觉规范文档。顶部:主 Logo,带有清晰的留白区域。 中间:色板——【Hex 1】,【Hex 2】,【Hex 3】,下方标注 Hex 标签。 下方:字体示例,【标题字体】和【正文字体】。 底部:正确/错误的使用示例。品牌口号:"【口号】" verbatim。 纯白背景。企业级设计审美。所有文字原样输出(verbatim)。
05 社交媒体广告:平台直出
适配 1:1、9:16、1.91:1 等各种比例。
一份【1:1/9:16】的社交媒体广告,为【品牌/产品】设计。视觉部分:【英雄位图像描述】。 文字层级叠加:标题"【内容】"(大号粗体,颜色);副标题"【内容】"(中等粗细); 行动按钮"【文字】"(颜色,胶囊形)。品牌色:【Hex 1】,【Hex 2】。 氛围:【充满活力/简约/奢华/俏皮】。无素材图感。所有文字 verbatim。

06 电影/活动海报:戏剧感拉满
适用于产品发布、活动宣传、任何能从戏剧化框架中获益的场景。
一张【时代感】风格的院线海报,片名为"【片名】"。【插画风格】。【调色板】。 【主体】位于前景,【背景细节】。标题:"【片名】"——【字体描述】、【颜色】、【位置】。 口号:"【内容】" verbatim。带有【纹理/做旧效果】。

07 漫画/分镜页面
GPT Image 2 支持非拉丁文字精准渲染——可以制作带有准确日语、韩语、孟加拉语的真实漫画。
- 【N】个分镜的单页漫画 - 布局:【网格描述,如 2x2】 - 每个分镜单独描述场景/动作/角度 - 艺术风格:【少年漫/青年漫/Webtoon/法式连环画】 - 对话框内容:分镜 N 气泡:"【对话】" verbatim
08 分屏时光旅行:前后对比叙事
适用于历史对比内容、前后效果展示或跨时代叙事。
一张由干净垂直线平分的分屏照片。左侧:【地点】在【年份】——【历史细节】。 右侧:同一视角的【年份】现状——【现代细节】。 双侧保持一致的透视和焦距。纪实摄影风格。
09 360 度全景图
大多数人不知道这在 GPT Image 2 中是可能的。技巧是:必须填满所有六个方向的元素描述。
一张关于【环境】的 360 度等距柱状全景图。 前方:【内容】;后方:【内容】;左右侧:【侧面元素】; 上方:【天空/天花板】;下方:【地面】。 【灯光与氛围】。高动态范围,全局锐利,无明显接缝。
10 信息图表
文字密集的图像通常是图像模型的软肋。GPT Image 2 能处理,但前提是给出明确的结构。
一张关于【话题】的干净单页信息图,标题为"【标题】",包含【N】个板块。 【布局方式:垂直堆叠/两栏网格/环形流】。 颜色:【主色 Hex】装饰,纯白背景,【字色 Hex】文字。 所有文字原样输出:第一部分 "标题"——"正文"……verbatim。
11 UI/App 原型图
适用于创始人、产品团队或任何需要可视化界面的场景。
一张【App 类型】的高保真 UI 原型图——【屏幕名称】界面。设备:【具体机型】。 屏幕内容:顶部标题"【标题】" verbatim; 【描述卡片、按钮、导航等各 UI 元素】;主按钮"【文字】" verbatim。 色板:【主色 Hex】为主,纯白背景,【强调色 Hex】用于交互元素。 字体:干净无衬线。扁平化设计,像素级精确间距。
12 角色设定参考图
长线项目角色一致性的核武器——先生成设定图,后续每条提示词开头写上"使用角色参考图,严格保留所有特征"。
为【角色名】设计的专业角色设计参考图。三视图并排:正面(左)、3/4 侧面(中)、正侧面(右)。 同一角色,同一套服装,比例完全一致。角色:【年龄、体态、特征】。 服装:【具体材质与颜色】。纯白背景。平整灯光。动画设定集审美。 标签文字:"【角色名】— Reference Sheet" verbatim。

四、API 用户福利:JSON 格式
在生产流程中批量调用时,JSON 格式能提供更精准的控制:
{
"meta": {
"image_quality": "Very High",
"style": "photorealistic",
"aspect_ratio": "16:9"
},
"scene": {
"location": "凌晨五点上海市场",
"time_of_day": "金黄时刻",
"weather": "薄雾"
},
"subject": {
"description": "整理水果的商贩",
"position": "中左侧",
"action": "弯腰整理木箱"
},
"lighting": "来自右侧的温暖定向光,柔和阴影",
"constraints": "无文字,无水印,极高细节"
}
五、5 条通用金律
- 1载体先行——开头第一句就定调。"院线海报"还是"一张照片"直接决定模型的底层构图理解。
- 2用事实说话,别谈感觉——"凌晨 5 点,浓雾笼罩鹅卵石街道"不需要模型猜。"忧郁、有氛围"才需要猜。
- 3单点迭代——出图之后一次只改一个变量。先声明你要保留什么,再说改哪一点。贪心一次改三处,会丢掉前面已生效的部分。
- 4明确取景角度——特写、中景、远景、俯拍、荷兰式斜角——你不说,模型默认居中中景。
- 5文字必带"原样输出"——只要画面里有字,结尾务必加
verbatim — no extra characters。
从"关键词"转向"指令集"。
从告诉它"要什么风格"到告诉它"画面里有什么"、"光从哪里来"、"焦点在哪"。
掌握这个转变,什么海报级画质、照片级写实、精准文字渲染,
几乎都能在一两次内搞定——不再靠抽卡碰运气。
参考:由 GitHub 开源社区及 AI 设计社区整理的经验总结 | 博客地址:https://jungelife.me/zh/blog/tools/gpt-image-2-prompt-engineering/
1.8k Star 的 GPT Image 2 提示词仓库,7 个能直接抄的 prompt
GPT Image 2 发布十多天了,网上教程铺天盖地,但真正好用的东西往往藏在 GitHub 上。 有人已经把精心打磨的提示词整理成公开仓库,全部免费,复制粘贴就能用。
我翻遍了 GitHub 上几个 Image 2 提示词仓库,最后留下的只有一个——Awesome-GPT-Image-2-API-Prompts 。
上面这张杭州春季海报,就是从仓库里的一条 prompt 改的。Charles River 换成西湖,Beacon Hill 换成雷峰塔,1 分钟出片,不用 Photoshop,不用找设计师。
一、这个仓库为什么值得推荐
仓库 1.8k Star——星数不是重点,重点是它每条 prompt 都是「能直接交稿」的水平。

仓库将 prompt 分为 6 大类:
- 1人像摄影
- 2海报插画
- 3游戏截图
- 4UI/UX 设计
- 5角色设计
- 6信息图排版
二、7 个最值得收藏的 Prompt
1. 城市春季海报 — 结构化模板的典范
仓库里最让我惊艳的一条,是 Boston Spring。它的构图极其巧妙:左下角一艘小船划过水面,水流顺着画面向上走,把整个城市的标志性元素——天际线、街道、桥、地标——全部融进河流形状的构图里。

我把它改成了杭州春季。你可以完全套用这个模板改造你的城市:
- 上海 → 黄浦江 + 外滩 + 武康大楼
- 苏州 → 运河 + 园林 + 平江路
- 西安 → 护城河 + 兵马俑 + 钟楼
这就是这个仓库的精髓:结构化模板可改造。 一条好 prompt 不是给你照抄的,是给你拆解学习的。
2. 宋朝社交媒体 — 穿越梗自带传播
这条 prompt 超级有趣——让 AI 生成「假如宋朝人有微信朋友圈」。苏东坡的头像、贬到黄州后发自制东坡肉、王安石点了「呵呵」、司马光评论「还是那个味道」。

Prompt 结构很巧妙:把现代社交 App 的所有元素(头像、用户名、点赞、评论)都列出来了,但内容全部替换成宋朝语境。套到唐朝、明朝、民国,都能复用。
写历史科普类、文化类内容的人,这条必须收藏。
3. 山河茶饮海报 — 新中式国潮设计
新中式虽然卷成红海,但这条 prompt 真能跑出能用的图。

核心是 文字层级的精确控制。一张茶饮海报需要哪些信息?品牌名、产品名、系列名、上市标语、限时价格、活动期、二维码区——这条 prompt 全部列出,让模型按设计师的方式排版。
4. 博物馆藏品信息图 — 教程类配图天花板
这是我用着最顺手的一条。Prompt 让 AI 生成「博物馆解说牌风格」的信息图——主体写实图、结构拆解图、材质工艺、纹样含义、色彩说明,全部图文结合排版。

风格不是海报,不是商品页,不是动漫——是顶级博物馆展板级别。prompt 里有个关键词 automatically determine the most appropriate subject structure,你只要给个主题,剩下的 AI 自己排版。
5. 35mm 便利店夜景人像 — 摄影级长 prompt
这条 prompt 长得离谱,但是它展示了 GPT Image 2 真正的强大之处。

摄影细节被精确控制到令人发指的程度:
- 35mm 胶片摄影
- 便利店冷白荧光灯混外面霓虹灯
- 玻璃门反光
- 真实皮肤质感,不要塑料感
- 真实微毛孔细节
这种 prompt 在 Midjourney 时代根本没法用——关键词堆叠永远做不到这种精度。但 GPT Image 2 吃这一套,500 字它都能消化。 仓库里这种超长写实 prompt 有四五条,每一条都是把 prompt 当一份摄影 brief 来写。
6. 咖啡溯源信息图 — 教程范本
如果你做内容、写公众号,这条 prompt 必须收藏。

它把「一杯咖啡是怎么来的」拆成 5 步:种植 → 处理 → 烘焙 → 研磨 → 萃取,每步都有具体数据。出来的图是一张完整的信息长图,路径箭头、数据框、图标、模块卡,一应俱全。
AI 出图时间 vs 自己用 Figma 拉图
把咖啡换成奶茶、葡萄酒、巧克力、面包、寿司,同一条 prompt 模板,能产出十几张不同主题的科普长图。
7. 16 面板表情网格 — 角色设计省 80% 时间
最后这条给做 IP 的人。

一张图生成同一个角色的 16 种不同表情——开心、悲伤、愤怒、惊讶、害羞、无语、坏笑、思考、好奇、骄傲、委屈、不屑、困惑、害怕、哭泣、爱心。
关键是 面部、发型、服装在 16 个面板里必须保持高度一致。这是 GPT Image 2 的角色一致性能力,扩散模型时代根本做不到。适合做漫画、IP 形象设计、表情包系列的人——一次生成等于一周工作量。
三、3 步抄出专业级图片
仓库介绍完,用法简单得离谱:
- 1去仓库找一条接近你需求的 prompt 复制下来
- 2替换具体内容——地标、品牌名、标语、配色。比如杭州海报模板里的 Charles River 改成西湖,crimson and gold 改成你的品牌色
- 3扔给 ChatGPT 或 Codex 出图
整个流程不到 10 分钟,比从零写 prompt 快 10 倍,效果还更好。
四、写在最后
可能有人会觉得这有点「投机取巧」。但我恰恰认为,AI 时代最稀缺的能力不是「从零创造」,而是「会站在巨人的肩膀上」。
以前一个普通人想做一张专业海报,要不就花三千块请设计师,要不就自己学三个月 Photoshop。现在你只需要会复制粘贴、会替换关键词。门槛塌方式下降,但能跨过这个门槛的人依然不多。
会抄的人,不丢人。懂得用别人的肩膀,反而是这个时代最稀缺的清醒。
AI 赋能:如何用 Claude 瞬间生成专业级系统架构图
在数字化转型加速的今天,系统设计与架构能力已成为技术工作者的核心竞争力。一张清晰、美观的架构图,往往胜过千言万语,能让复杂的系统逻辑一目了然。
然而,传统的绘图方式往往让人望而却步:
- 门槛高:需要熟练掌握 Visio, OmniGraffle, ProcessOn 等专业工具。
- 耗时久:调整对齐、配色、连线占据了大量时间,修改成本极高。
- 风格乱:难以统一格式,从文本思维到图形表达存在巨大的转换鸿沟。
在多次尝试 WPS AI、豆包、通义千问等工具后,我发现生成的图表在专业度和美观度上仍有欠缺。直到我发现了 Claude (配合特定 Prompt) 的强大能力——它可以一键生成代码级的 SVG 或 HTML 架构图,只需简单截图,即可完美嵌入 PPT,极大地提升了技术交流的效率。
本文将分享这一高效方法,助你轻松搞定“高大上”的架构图。
🎨 效果预览
在深入方法之前,先来看看 AI 生成的实际效果。这些图表均由 Claude/Gemini 3 配合提示词直接生成 SVG/HTML 渲染而成。
1. 宣传汇报类
适用于产品介绍、方案推广,风格现代简洁。

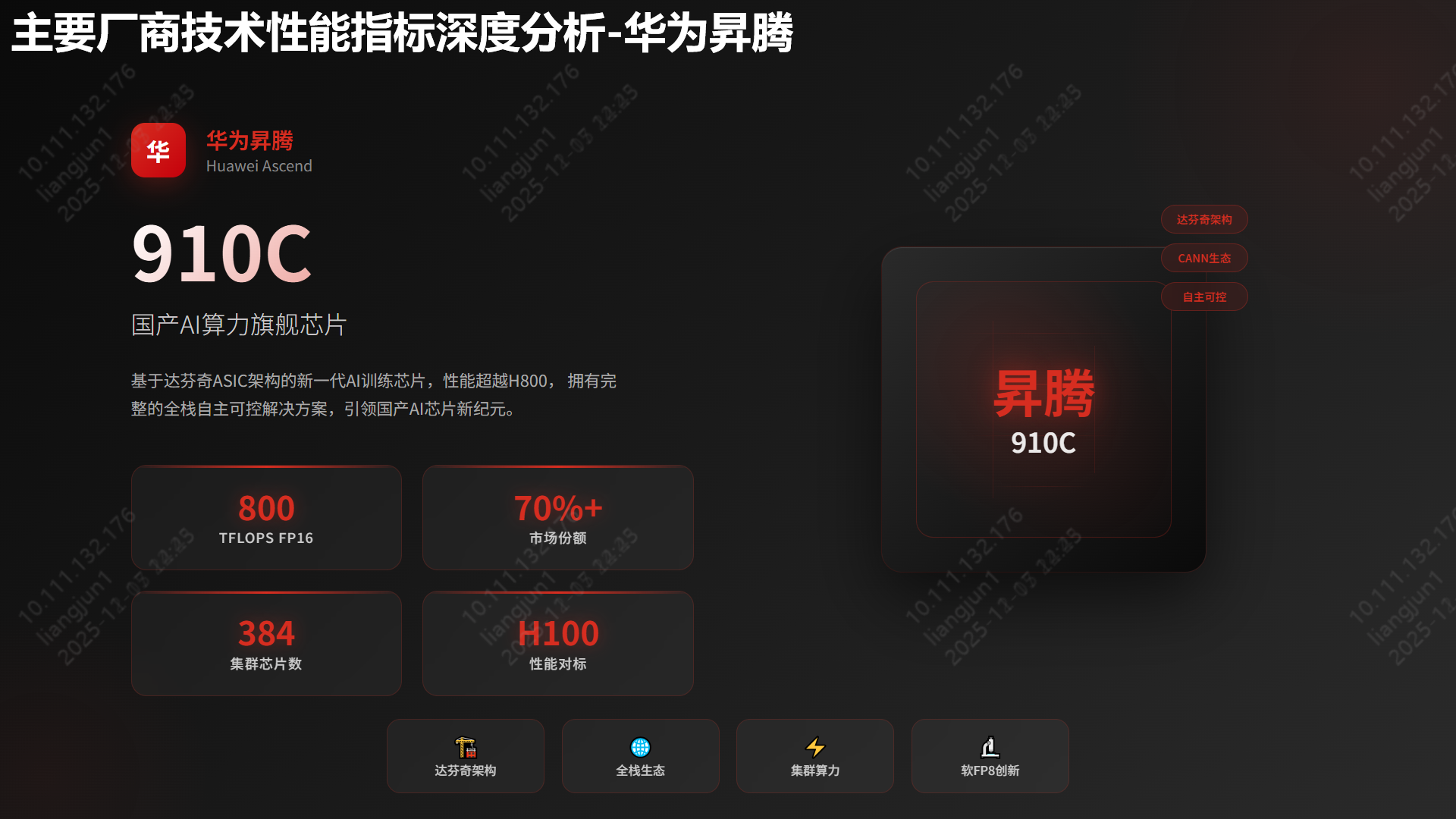
2. 架构设计类
适用于技术评审、系统蓝图,层次分明,逻辑严密。
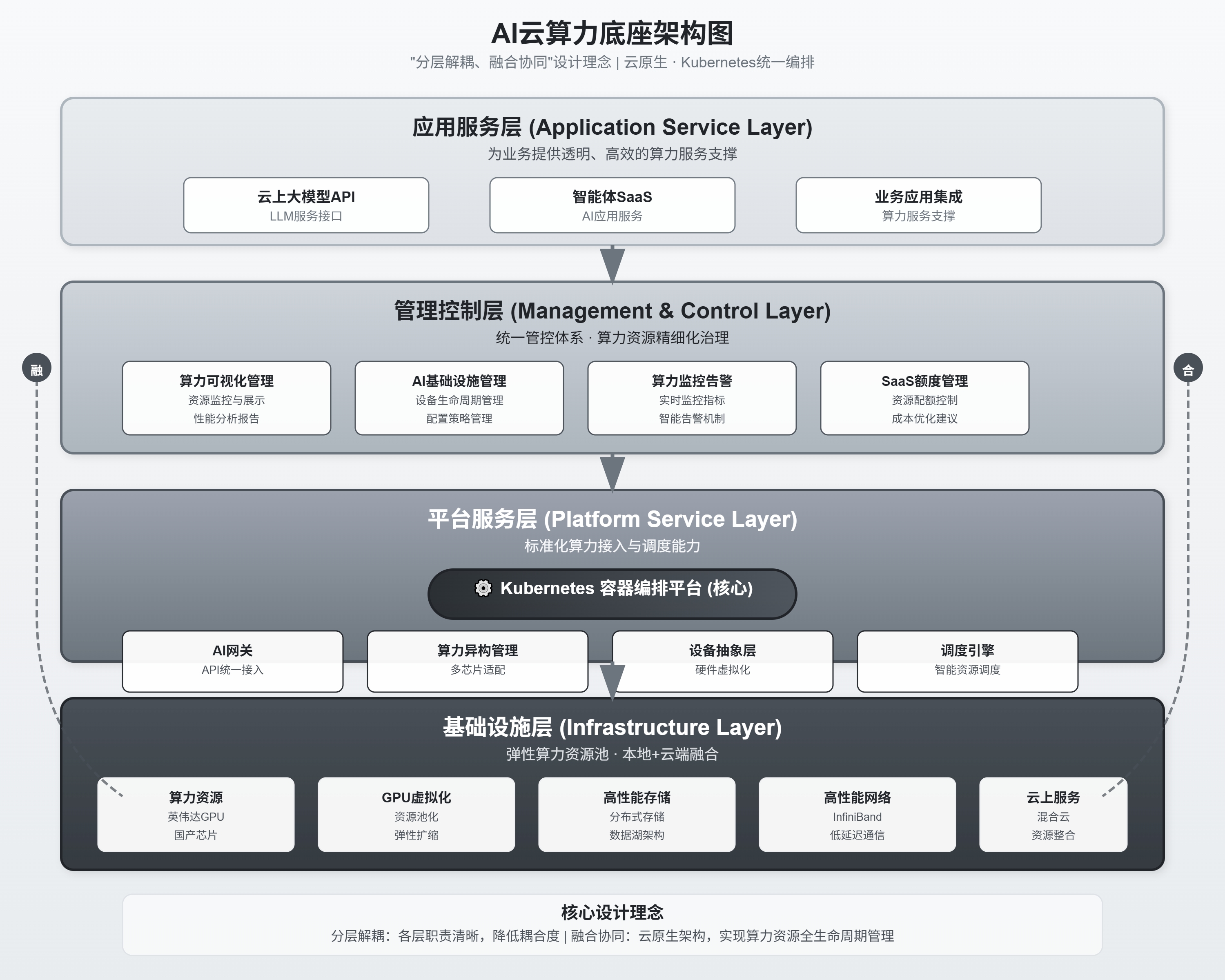
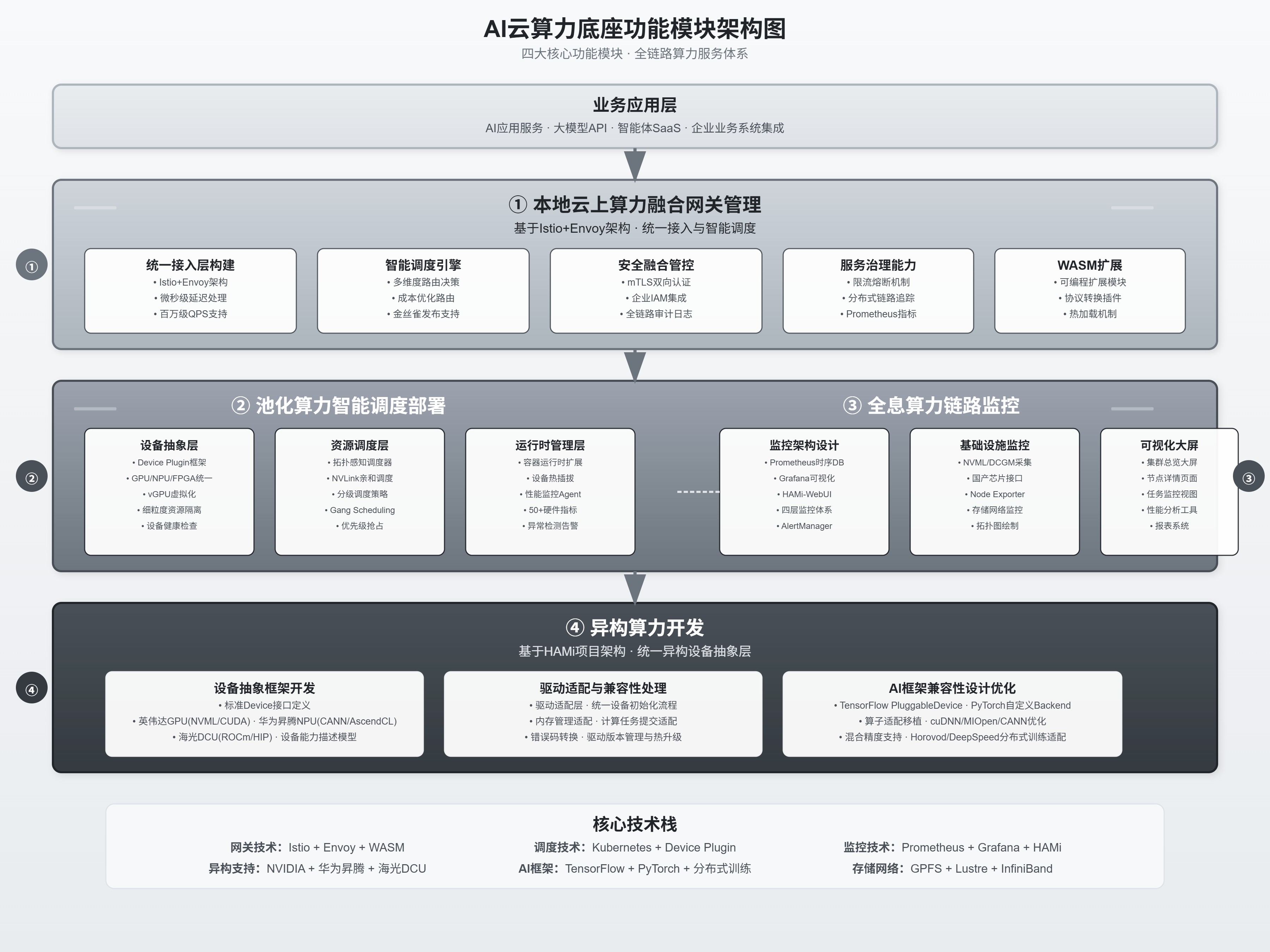
3. 业务流程类
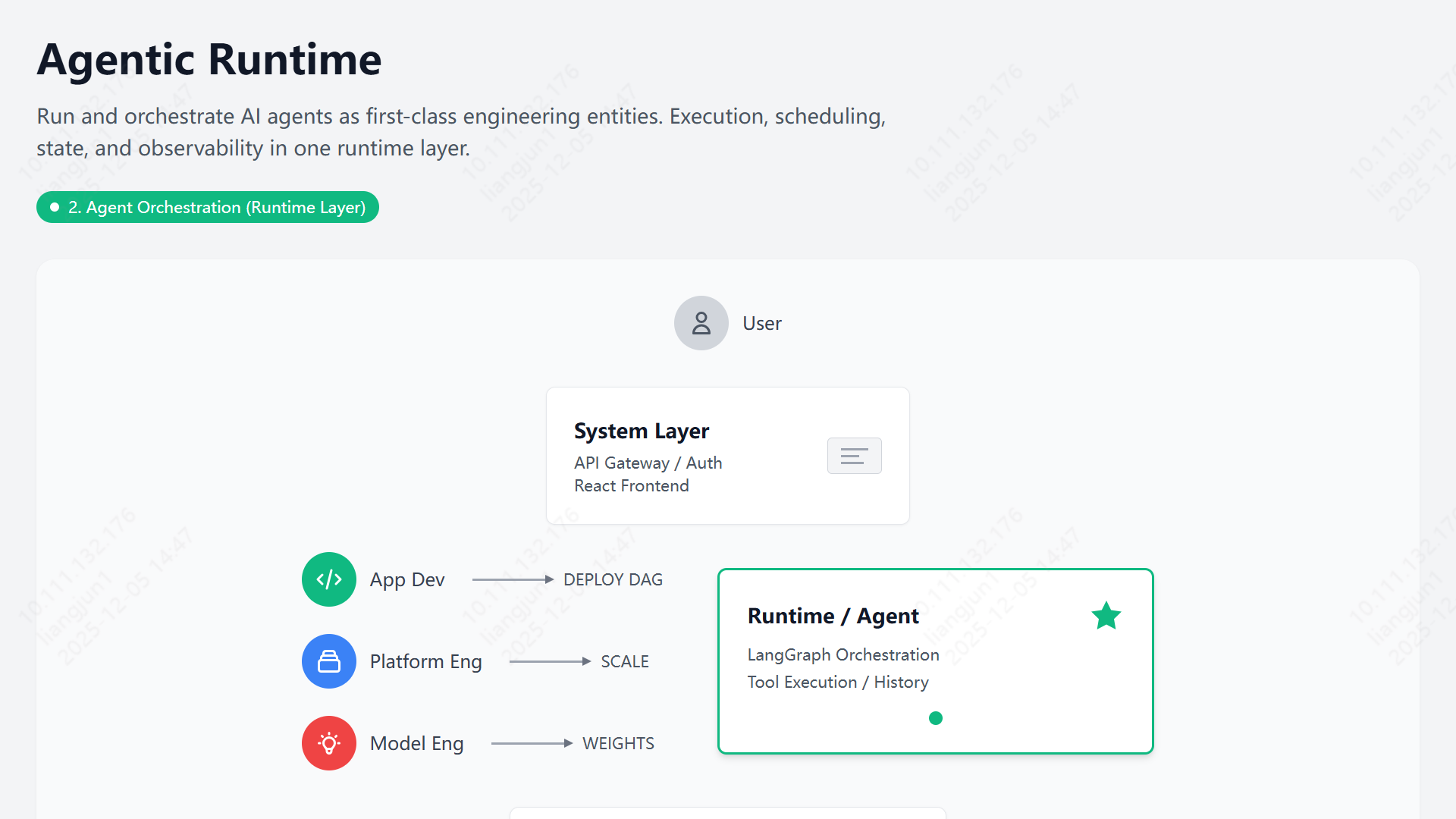
适用于泳道图、状态流转,清晰直观。
🛠️ 准备工作
要实现上述效果,你需要准备好以下环境:
方案 A:在线直接生成 (推荐)
如果你能顺畅访问 Google 服务,直接使用 Google AI Studio 是最便捷的选择。
方案 B:客户端 + API
对于国内网络环境,推荐使用本地客户端配合 API 服务:
- 客户端:下载安装 Cherry Studio (支持多模型管理的优秀客户端)。
- API 服务:你需要一个支持 Claude 3.5 Sonnet 或 Gemini 1.5 Pro 的 API。
- 推荐渠道:DMX API
(使用邀请码
bDx3可获赠额度) - 备选渠道:OpenRouter 等其他聚合服务商。
- 推荐渠道:DMX API
(使用邀请码
🚀 实战演练:4步生成架构图
以 Cherry Studio + Claude 4 Sonnet 为例,生成一张架构图仅需四步:
- 准备文档:梳理好你的系统描述、功能列表或技术栈说明。
- 输入指令:将下方的“万能提示词”填入对话框。
- 获取代码:AI 会输出一段 SVG 或 HTML 代码。
- 渲染保存:Cherry Studio 会自动渲染预览,直接截图或保存即可。
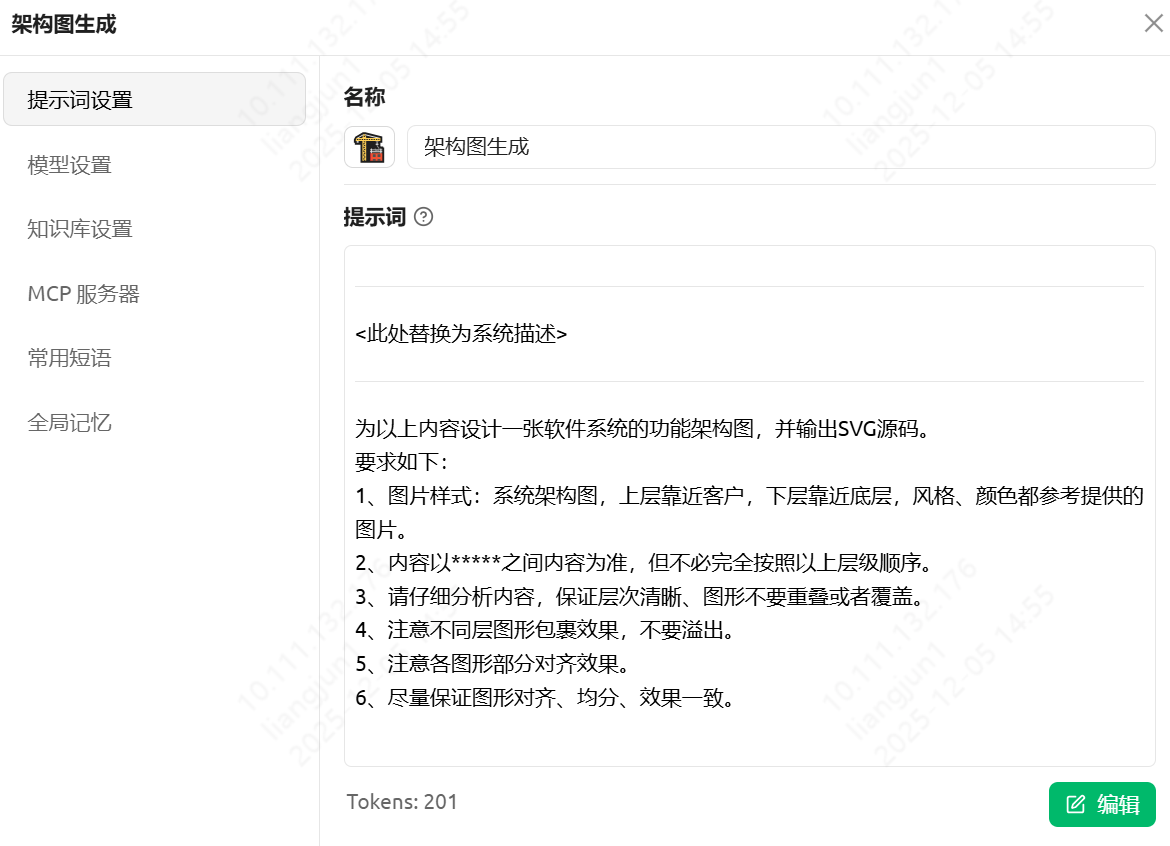
核心提示词 (Prompt)
复制以下 Prompt,将 <此处替换为系统描述> 替换为你实际的业务内容:
*****
<此处替换为系统描述>
*****
为以上内容设计一张软件系统的功能架构图,并输出 SVG 源码。
**设计要求:**
1. **视觉风格**:采用专业的系统架构图样式。
* 布局:逻辑分层,上层靠近用户/业务,下层靠近底层/数据。
* 配色:参考现代科技风格(如蓝、白、灰主色调),配色和谐专业。
2. **内容准则**:
* 内容严格以 ***** 之间的描述为准。
* 层级顺序可根据架构逻辑进行微调,不必完全死板照搬。
3. **布局细节**:
* 层次清晰,模块之间严禁重叠或遮挡。
* 容器包裹效果要自然,子模块不要溢出父容器。
* 严格对齐(左对齐、居中对齐),模块间距均匀。
4. **最终输出**:仅输出一段完整的、可直接渲染的 SVG 代码。
输入示例
Cherry Studio示例:
最终产出
经过 AI 的即时运算,你将获得类似下图的精美架构图。
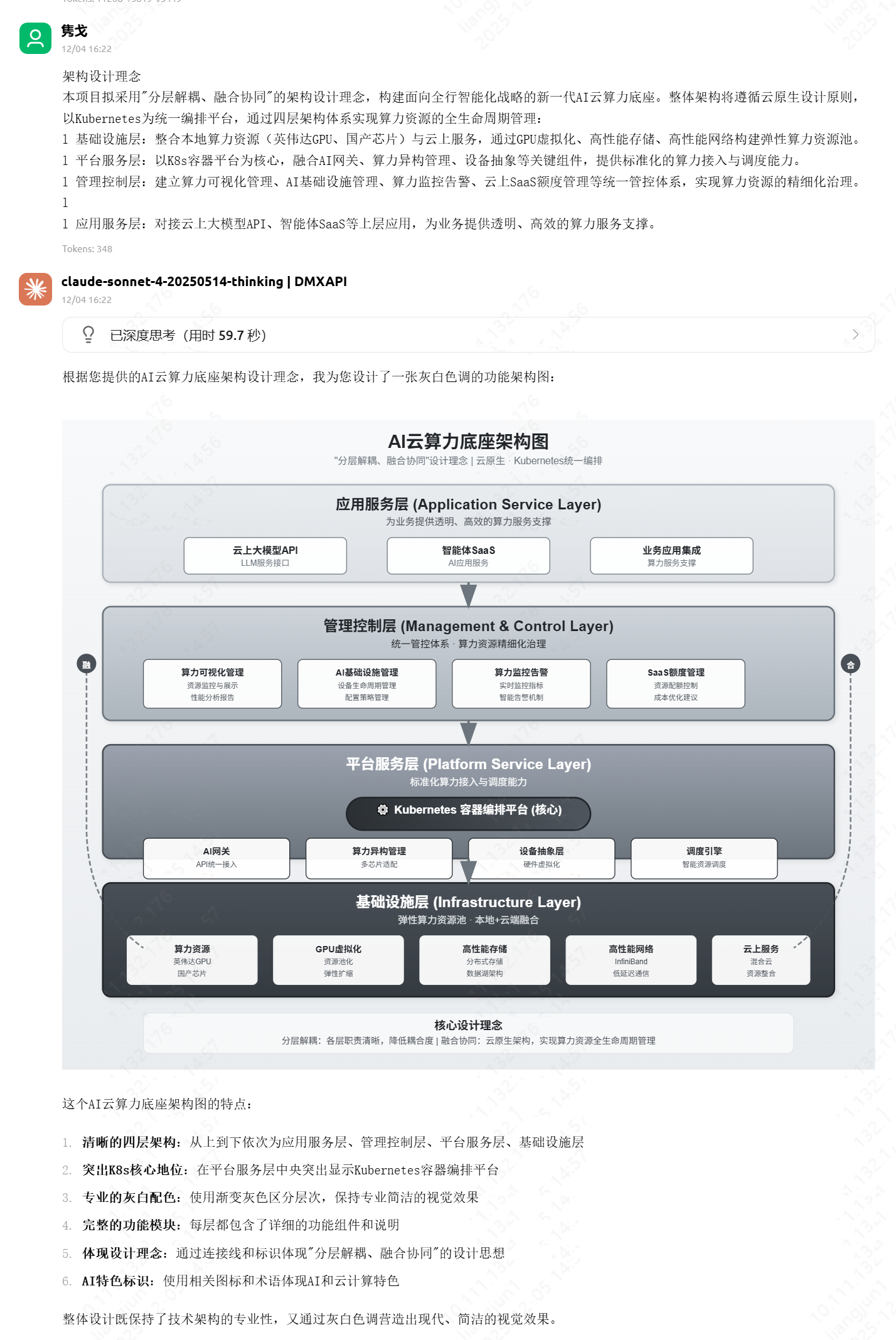
如果你用Cherry Studio可以直接复制/下载图片用于 PPT 汇报绝对吸睛!

💡 总结
AI 正在重塑我们的工作流。通过将“绘图”这一繁琐过程转化为“描述”这一认知过程,我们不仅节省了时间,更能将精力集中在系统设计本身的逻辑与价值上。下次做 PPT 时,不妨试试这个方法。
Ghelper 使用流程指导
Ghelper 是一个浏览器插件,专门为科研、外贸、跨境电商、海淘人员、开发人员服务的上网加速工具,Chrome 内核浏览器专用!
它可以解决 Chrome 扩展无法自动更新的问题,同时可以访问 Google 搜索、Gmail 邮箱等谷歌产品。它可以帮助用户提高跨境访问网站的速度,突破地区限制,提高工作和学习的效率。
如何安装
支持 Chrome / Edge / 360 等 Chromium 内核浏览器。
方法一:手动安装(推荐)
- 下载插件:访问 Ghelper 官网
,下载 CRX package。下载后是一个 zip 文件,请解压缩取得
.crx文件。
- 打开扩展程序管理页面:
- 打开浏览器,点击地址栏最右边的三个点(菜单),选择 “更多工具” -> “扩展程序”。
- 或者直接在地址栏输入
chrome://extensions/并回车。
- 开启开发者模式:确保页面右上角的 Developer mode (开发者模式) 处于打开状态。
- 拖拽安装:将第一步解压得到的
.crx文件拖放到浏览器的扩展程序页面上,浏览器会提示是否添加扩展,点击“添加扩展程序”即可安装完成。
方法二:在线安装(Edge 浏览器)
如果是 Edge 浏览器,可以直接访问 Microsoft Edge Addons 商店:
点击页面右上角的 “获取” 按钮即可自动安装完成。
使用说明
- 安装完成后,点击浏览器右上角的插件图标。
- 点击 “登录” 按钮进行账号登录(如果没有账号请先注册)。
- 登录成功后,可以看到插件主界面,以及当前 VIP 的有效期。
(请将登录界面截图命名为 login_interface.png 并放在本文件同级目录下)
提示:请确保您的 VIP 状态有效以享受加速服务。