AgentMemory 开源:给 AI 编程 Agent 装上持久化大脑
2 分钟阅读
每天都跟 Claude Code、Cursor 这些 AI 编程 Agent 打交道的人,大概率都遇到过同一个问题:每次开新会话,都得把项目背景重新交代一遍。 架构选型、目录结构、代码风格、踩过的坑——AI 什么都会,就是不会"记住"你。
最近 GitHub 上冒出一个叫 agentmemory 的开源项目,1.4 万+ Star,口号很直白:给你的 AI 编程 Agent 装上持久化大脑。它在 ICLR 2025 的 LongMemEval 基准测试中,R@5 命中率达到 95.2%,远超同类工具。

一、AI 编程的"失忆症"问题
用过 Claude Code 或 Cursor 的人都知道,每次开始新会话,Agent 对你的项目一无所知。常见的"上下文传递"方案有几种,但各有局限:
- 1CLAUDE.md / .cursorrules — 手动维护项目说明文件,但最多 200 行,容易过时,且每个 Agent 各写各的
- 2手动粘贴上下文 — 每次把架构文档、技术选型复制到对话中,token 消耗巨大,年成本可达 $500+
- 3LLM 压缩摘要 — 让模型自己总结上下文,仍然需要手动触发,且压缩质量不稳定
- 4全量加载到提示词 — 超过上下文窗口直接崩溃,不现实
这些方案的本质问题是一样的:上下文传递依赖人工,而 AI 的"失忆"是每会话一清零的硬伤。
二、三路融合检索:不止是关键词匹配
agentmemory 的检索系统不是简单的关键词匹配,而是走了一套成熟的混合检索方案:
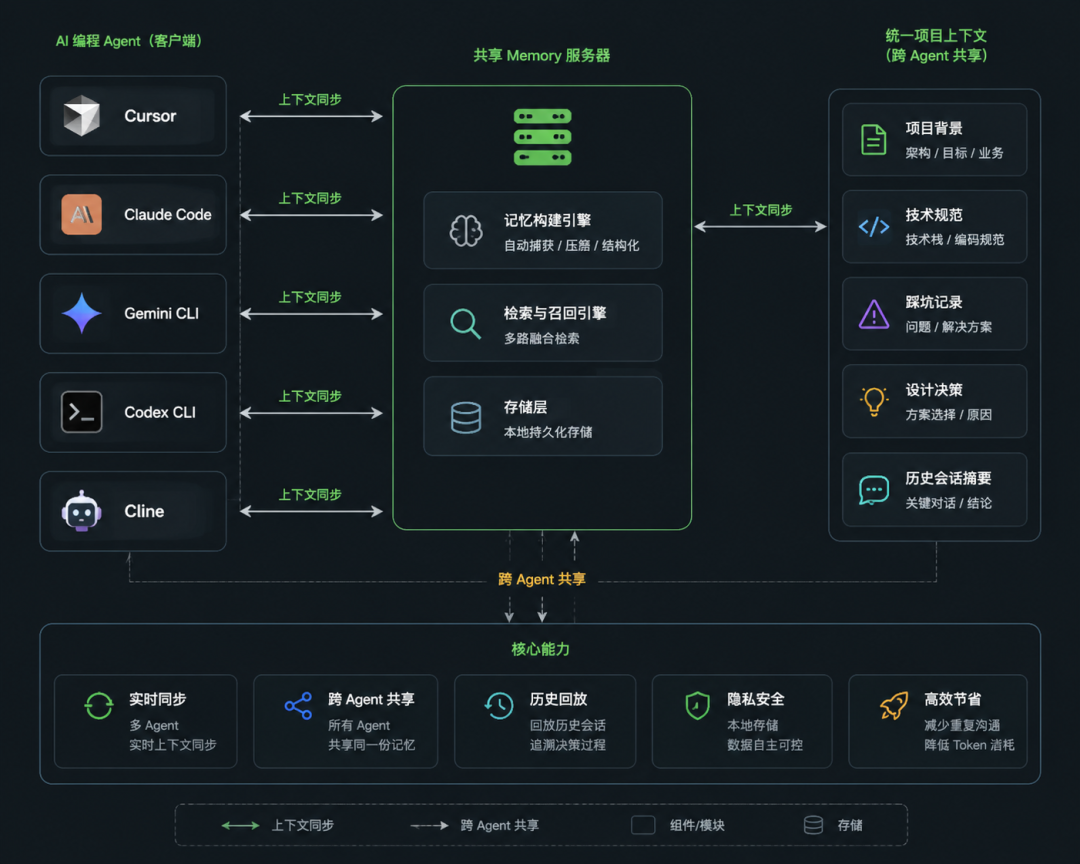
- BM25 — 传统关键词检索,速度快,适合精确匹配
- 向量检索 — 基于 all-MiniLM-L6-v2 本地嵌入模型,语义理解,无需 API Key
- 知识图谱 — 实体关系建模,理解代码之间的关联
三路结果通过 RRF(Reciprocal Rank Fusion) 排序融合,最终的检索质量远超单一方案。
对比数据来自 GitHub 官方 benchmark:
| 系统 | R@5 | R@10 | 备注 |
|---|---|---|---|
| agentmemory | 95.2% | 98.6% | BM25 + 向量 + 知识图谱三路融合 |
| BM25-only (fallback) | 86.2% | 94.6% | 仅关键词匹配 |
| mem0 (53K ⭐) | 68.5% | - | 被动记忆提取,需手动调用 |
| Letta / MemGPT (22K ⭐) | 83.2% | - | 需要 Postgres + 向量数据库 |
差距很明显。agentmemory 的优势不仅体现在准确率上,还在于它完全不需要外部基础设施。
三、架构设计:极简部署,零外部依赖
agentmemory 的底层架构非常克制,也是它能做到"一条命令启动"的关键原因。
npm install -g @agentmemory/agentmemory # 全局安装
agentmemory # 启动记忆服务器,默认 :3111
agentmemory connect claude-code # 接入 Claude Code
agentmemory connect cursor # 接入 Cursor

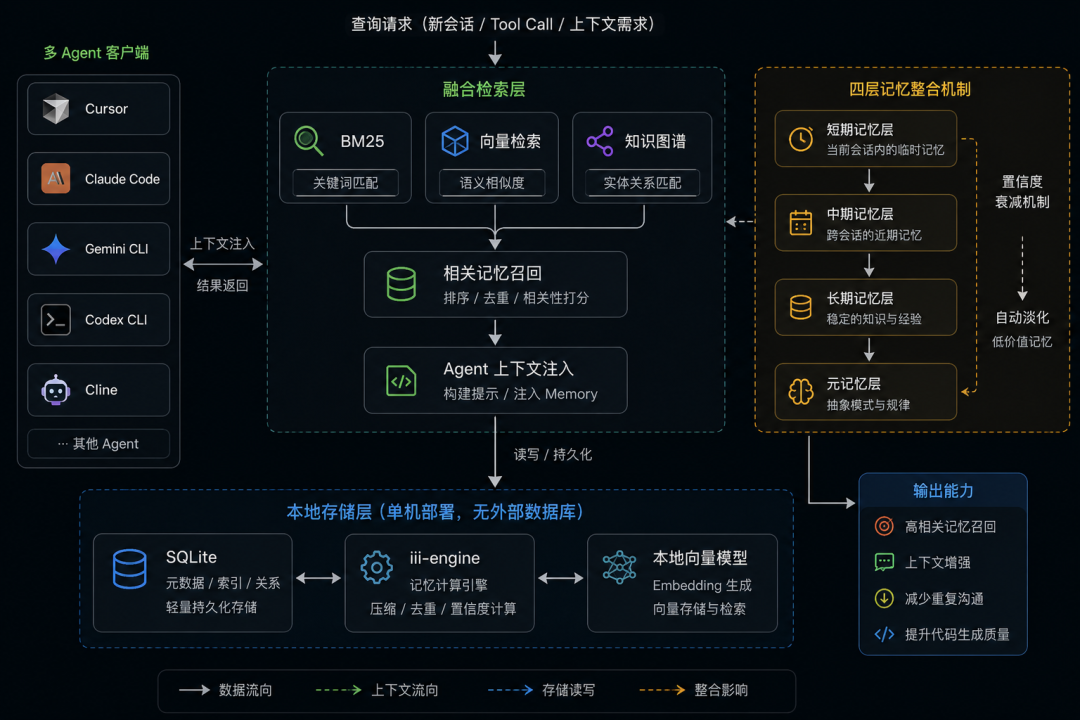
四层记忆整合机制 是它区别于其他工具的关键设计:
- 1短期记忆 — 当前会话的实时交互记录
- 2工作记忆 — 跨会话保留的重要上下文
- 3长期记忆 — 项目层面的技术规范、架构决策
- 4全局记忆 — 跨项目的通用模式与偏好
每层记忆带置信度衰减机制——久了没用的记忆会逐渐淡化,不会越堆越乱。这个设计很像人类的记忆模式:常被回忆的内容永远新鲜,早已遗忘的事情自然淡出。
四、实时可视化与回放
启动 agentmemory 之后,打开浏览器访问 http://localhost:3113,能看到实时记忆构建的仪表盘:
最有意思的功能是 会话回放(Replay)——每一次 Agent 交互都被记录下来,可以通过时间轴逐帧回放:提示词、工具调用、执行结果、模型回复,全部可查。支持 0.5×~4× 变速播放,排查问题极为方便。
如果你之前有过 Claude Code 的 JSONL 转录文件,也可以直接导入:
# 导入所有 ~/.claude/projects 下的历史会话
npx @agentmemory/agentmemory import-jsonl
# 导入单个文件
npx @agentmemory/agentmemory import-jsonl ~/.claude/projects/my-project/abc123.jsonl
五、Agent 生态覆盖
agentmemory 支持的 Agent 类型覆盖了当前主流的 AI 编程工具生态:
| Agent | 接入方式 | 说明 |
|---|---|---|
| Claude Code | 原生插件 + 12 个 Hook + MCP | 支持最完善 |
| Codex CLI | 原生插件 + 6 个 Hook + MCP | OpenAI 官方 |
| Cursor | MCP 服务器 | 主流 IDE 集成 |
| Gemini CLI | MCP 服务器 | Google 出品 |
| Cline | MCP 服务器 | VS Code 插件 |
| OpenClaw | 原生插件 + MCP | 支持完整 |
| Aider | REST API | 终端工具 |
| Windsurf | MCP 服务器 | 新一代 IDE |
所有 Agent 共享同一个记忆服务器,上下文完全打通。
六、成本与效率
这是最让人意外的地方——agentmemory 的 token 开销极低。
| 方式 | 年 Token 量 | 年成本 |
|---|---|---|
| 每次手动粘贴全量上下文 | 1950 万+ | 超出上下文窗口 |
| LLM 自动摘要 | ~65 万 | ~$500 |
| agentmemory(默认) | ~17 万 | ~$10 |
| agentmemory + 本地向量 | ~17 万 | $0 |
七、快速上手
# 安装
npm install -g @agentmemory/agentmemory
# 启动记忆服务器
agentmemory
# 接入 Agent
agentmemory connect claude-code
agentmemory connect cursor
# 启动演示(3 条会话 + 召回验证)
agentmemory demo
# 打开仪表盘
# → http://localhost:3113
安装完成后,agentmemory demo 会注入 3 个真实的会话样本(JWT 认证配置、N+1 SQL 优化、限流策略实现),然后你可以用语义搜索来验证召回效果——比如搜"数据库性能优化",它会把 N+1 查询修复的上下文找出来,纯关键词匹配做不到这一点。
写在最后
对于每天跟 AI 结对编程的人来说,agentmemory 解决了一个长期被忽视的基础设施问题——Agent 的上下文持久化。它不需要你改变工作流程,不需要引入外部数据库,一条命令装好就能用。
当你经历这样一个时刻:新开一个会话,Agent 自动知道你的项目用 jose 而不是 jsonwebtoken、知道你的测试覆盖了哪些边界情况、知道上周刚修复的那个 bug 的根因——你就再也回不去了。
GitHub:github.com/rohitg00/agentmemory
官网:agent-memory.dev
npm:@agentmemory/agentmemory
装上试试,让 Agent 有记忆是什么体验,用了就回不去了。