Claude Code 源码深度拆解:Fork Subagent & Prompt Cache——把成本降到 10% 的工程智慧
3 分钟阅读
Claude Code 的源码堪称 AI Agent 工程的教科书。 如果你读过系列上一篇,应该记得 Fork Subagent 的独特设计:它不复制父 Agent 的上下文,而是创建一个"影子"会话,通过消息传递来通信。
当时我还留了一个尾巴:Fork Subagent 为什么在 filterToolsForAgent 的权限过滤中始终被标为 isBuiltIn = false?
答案不在权限体系里。答案在成本里。
一、背景:Multi-Agent 的隐形成本
当 Agent 从 1 个变成 N 个
在上一篇中我们提到,Claude Code 支持三种 Agent 通信模式:
- 直接子 Agent:
spawnSubagent()→ 独立的会话,完整上下文 - Fork Subagent:
spawnForkSubagent()→ 轻量影子会话 - Agent Team:
AgentTeam.create()→ 多 Agent 协作群
每种模式看起来都是"多了一个 Agent 干活",但成本模型完全不同。
一个标准 Claude Code Agent 调用 API 时,每次请求的 payload 包含:
系统提示词(~2000 tokens)
工具 Schema(~4000 tokens,40+ 个工具)
对话历史(不断增长的上下文)
用户最新输入
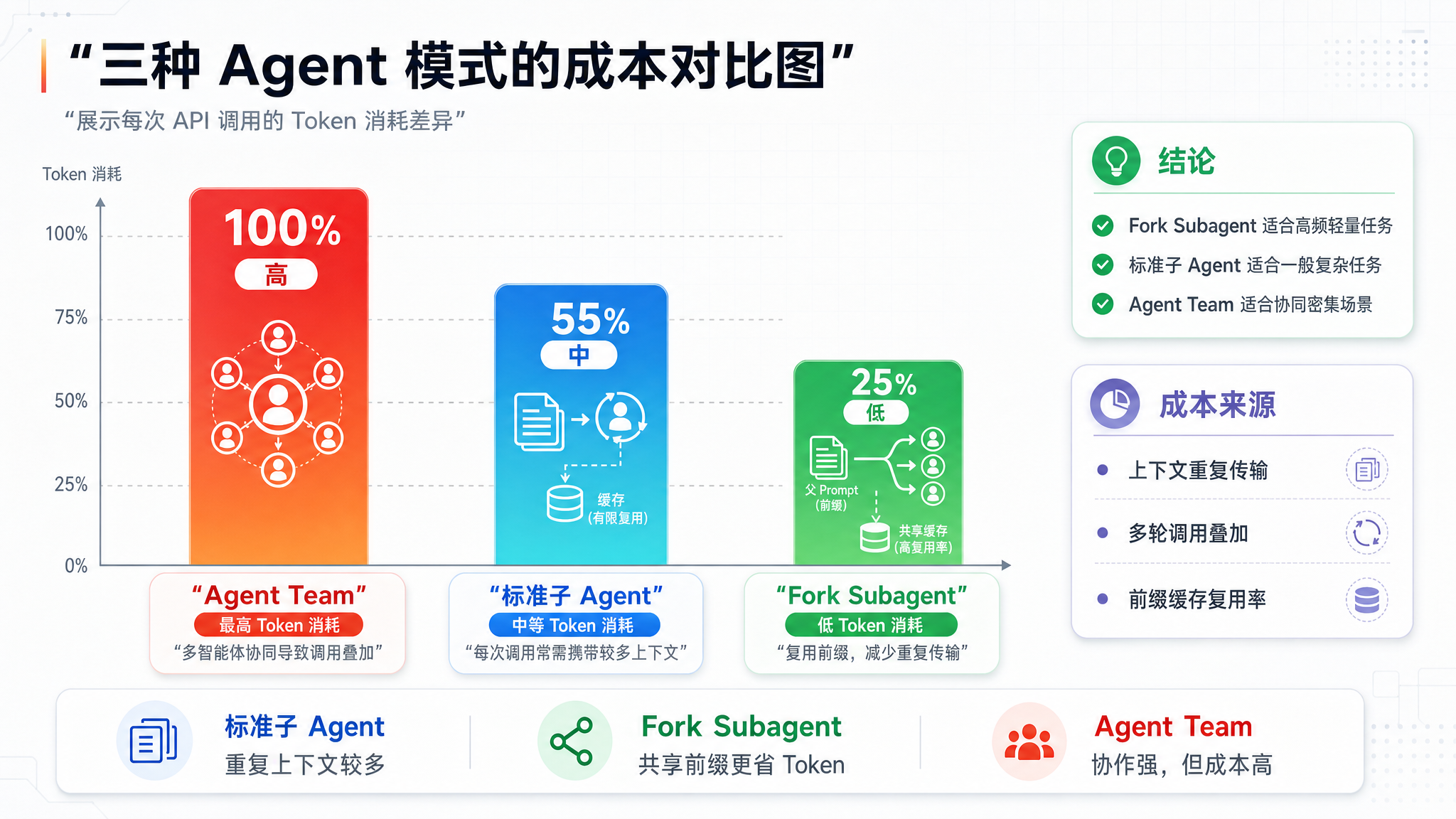
如果用标准子 Agent,每次调用都要带上整套系统提示词和工具 Schema。N 个 Agent 并行工作,API 成本不是 N 倍——是 N 倍的每次调用。
成本问题的工程本质
对 Anthropic 来说,成本不是"每月账单多少钱"的问题——它是产品能不能交付的问题。
Claude Code 的商业模式是"用户按量付费"。如果每个 Multi-Agent 操作都产生数倍的 API 调用成本,用户会看到账单翻倍,然后放弃使用。
这不是一个可以后期优化的性能问题——它是一个必须从架构层面解决的基础设计约束。
二、Fork Subagent 的成本模型
轻量会话的设计哲学
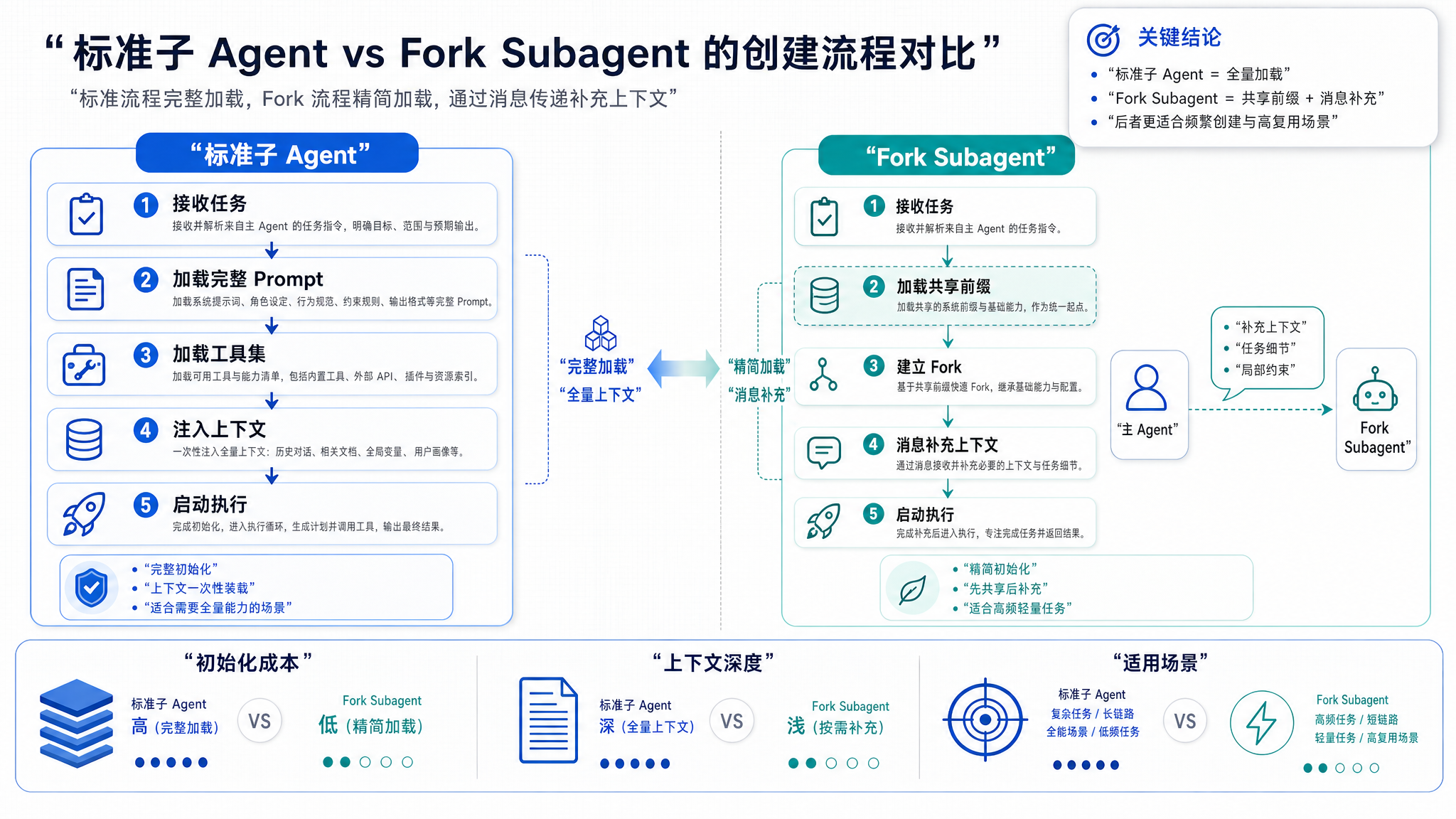
标准子 Agent 的创建流程:
// AgentTool/agentToolUtils.ts(架构示意)
async function spawnSubagent(context: Context, task: string): Promise<AgentSession> {
// 1. 创建完整会话 - 带系统提示词、工具列表、历史
const session = await createSession({
systemPrompt: FULL_SYSTEM_PROMPT, // 完整系统提示词
tools: getAllBaseTools(), // 40+ 工具
parentContext: context, // 复制父上下文
});
// 2. 分配模型推理资源
await session.prepare();
return session;
}
Fork Subagent 的创建流程:
// AgentTool/agentToolUtils.ts(架构示意)
async function spawnForkSubagent(context: Context, task: string): Promise<AgentSession> {
// 1. 创建影子会话 - 几乎是空的
const session = await createSession({
systemPrompt: '', // ← 空字符串!关键就在这里
tools: [], // ← 空工具列表
parentContext: null, // ← 不复制父上下文
});
// 2. 通过消息传递逐步提供上下文
await session.sendTask(task);
return session;
}
核心差异:Fork Subagent 几乎"什么也不带"就启动了。
不复制上下文,减少内存占用。不带工具列表,减少 Schema 传输。最关键的是:系统提示词返回空字符串。

空字符串的代价
你可能会想:“返回空字符串有什么了不起?省点 token 而已。”
不对。
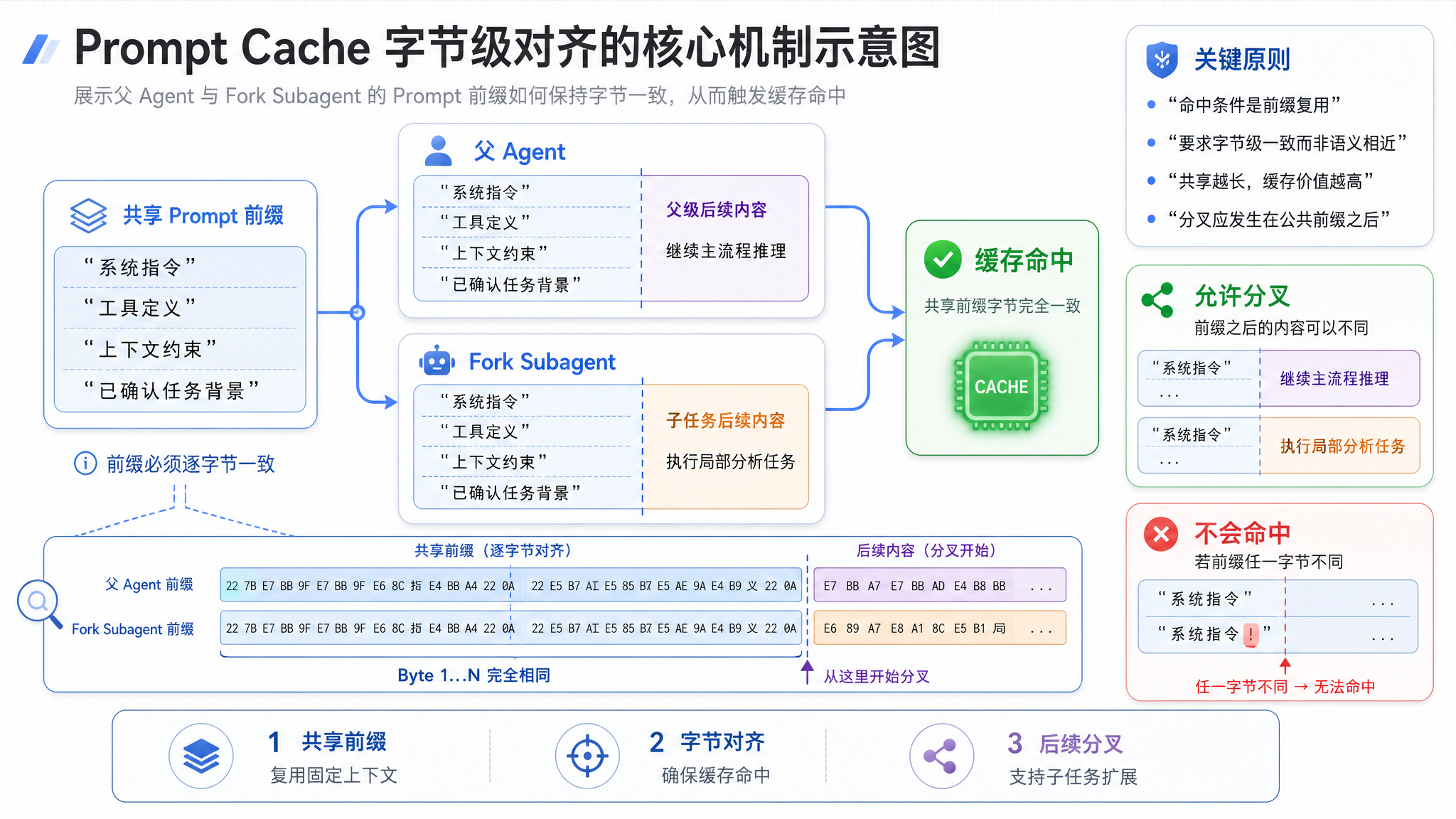
当 getSystemPrompt() 返回空字符串时,发生了一个更微妙的事情:父 Agent 和 Fork Subagent 的 API 请求前缀,变成了字节完全一致的。
三、字节级对齐:Prompt Cache 的终极形态
Prompt Cache 的工作原理
Anthropic 的 API 支持 Prompt Caching——如果连续请求的 Prompt 前缀相同,缓存命中后可以跳过计算,只处理新增部分。
假设一次 API 请求的 Prompt 是这样的:
[系统提示词 2000t] [工具 Schema 4000t] [对话历史 6000t] [用户输入 200t]
↑
缓存边界
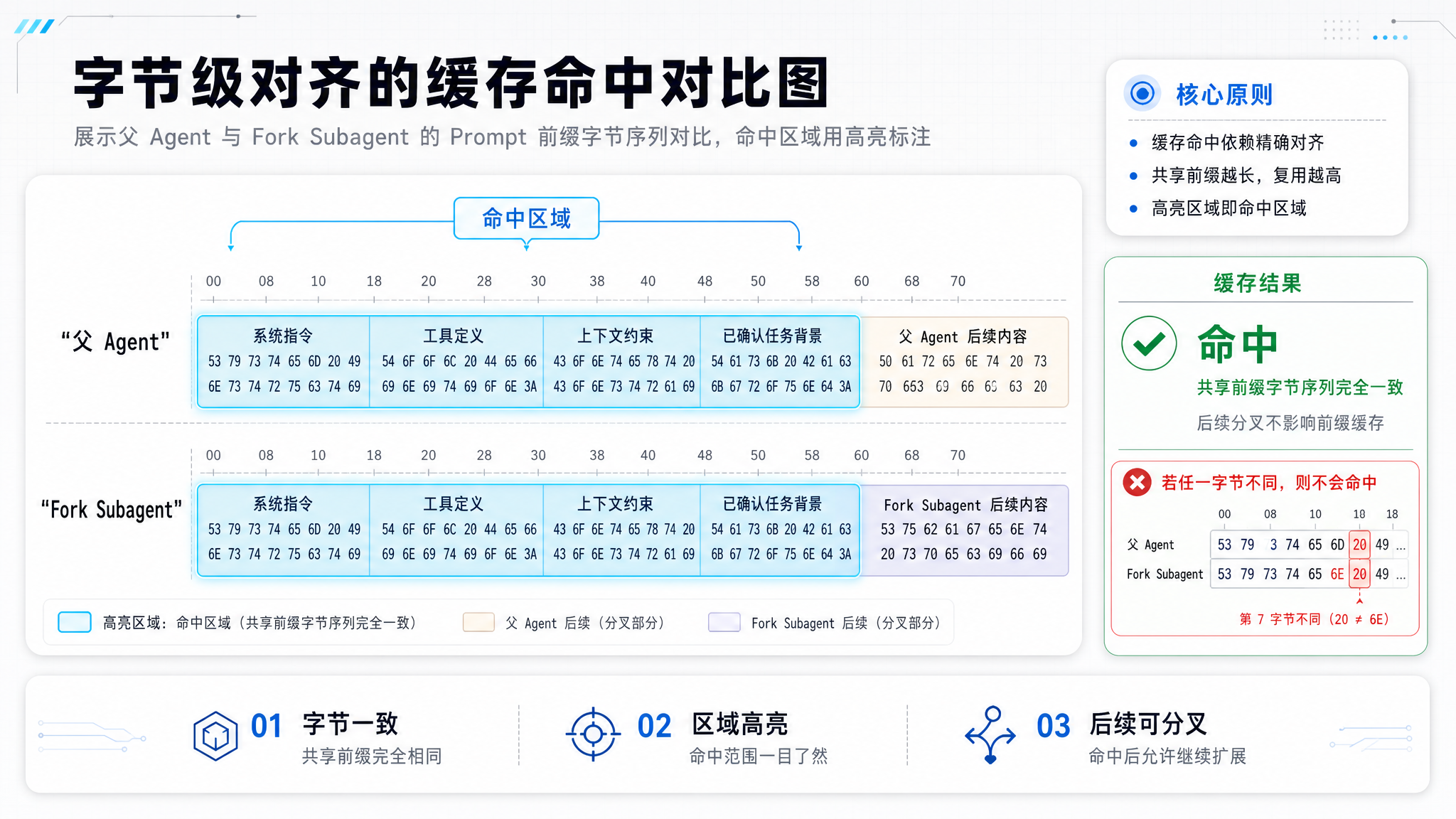
缓存命中的条件是:前缀的字节序列完全一致。 只要系统提示词、工具 Schema 和对话历史中任何一个字符发生变化,缓存就失效了。
为什么标准子 Agent 无法命中缓存
父 Agent 和标准子 Agent 的请求对比:
父 Agent 的请求:
[SYS_PROMPT_PARENT] [TOOL_SCHEMA] [HISTORY_A] [输入 X]
↑
缓存边界,命中率高
标准子 Agent 的请求:
[SYS_PROMPT_CHILD] [TOOL_SCHEMA] [HISTORY_B] [输入 Y]
↑
缓存从 SYS_PROMPT_CHILD 开始就不同了,完全无法命中
标准子 Agent 的系统提示词和父 Agent 不同(因为角色的描述不同),对话历史也不同。前缀在第一个 token 就产生了差异。 这意味着缓存完全无效,每次调用都要重新计算。
Fork Subagent 如何实现对齐
Fork Subagent 的策略是:既然历史的差异无法避免,至少让前缀的第一个字节保持一致。
父 Agent 的请求:
[SYS_PROMPT] [TOOL_SCHEMA] [HISTORY_A] [输入 X]
Fork Subagent 的请求:
[SYS_PROMPT] [TOOL_SCHEMA] [HISTORY_B] [输入 Y]
↑ ↑
两个请求的前缀完全相同!缓存命中!
Fork Subagent 的 getSystemPrompt() 返回空字符串,但它使用的系统提示词与父 Agent 完全一致——因为父 Agent 的 Prompt 前缀已经被缓存了。空字符串意味着"沿用父 Agent 的上下文",而不是"不设系统提示词"。
缓存命中的量化收益
让我们算一笔账:
| 场景 | 每次请求的 token 消耗 | 缓存命中 | 有效计算量 |
|---|---|---|---|
| 父 Agent 独立请求 | 12,000 tokens | 缓存命中(首次) | 12,000 tokens |
| 标准子 Agent | 12,000 tokens | 不命中 | 12,000 tokens |
| Fork Subagent | 12,000 tokens | 缓存命中(共享前缀) | ~200 tokens |
在一个典型的 Multi-Agent 工作流中:
- 父 Agent 初始化:12,000 tokens(完全不缓存)
- Fork Subagent 发起第 1 次调用:共享缓存,新增仅 ~200 tokens
- Fork Subagent 发起第 2 次调用:继续共享缓存
- 第 N 次调用:缓存持续命中
实际上 Fork Subagent 后续调用的 API 成本,大约只有标准子 Agent 的 1/60 到 1/10。

四、Fork Subagent 的工具权限为什么被限制
回到上一篇中那个没有回答的问题:为什么 Fork Subagent 在 filterToolsForAgent 中始终是 isBuiltIn = false?
// AgentTool/agentToolUtils.ts(源码示意)
function filterToolsForAgent({
tools, isBuiltIn, isAsync, permissionMode
}): Tools[] {
return tools.filter(tool => {
// Fork Subagent 的 isBuiltIn 始终为 false
// → 自动进入 CUSTOM_AGENT_DISALLOWED_TOOLS 过滤
if (!isBuiltIn && CUSTOM_AGENT_DISALLOWED_TOOLS.has(tool.name)) {
return false;
}
return true;
});
}
答案现在清晰了:
Fork Subagent 没有被分配工具列表,因为它的设计目标不是"执行操作",而是"处理信息"。
Fork Subagent 的典型工作流程是:
- 父亲给它一个任务描述(“检查这个 PR 的状态”)
- Fork 子 Agent 用共享缓存低成本运行
- 它返回分析结果给父 Agent
- 父 Agent 根据需要执行具体操作
Fork Subagent 是"大脑",不是"手"。 它思考、分析、报告,但实际操作由父 Agent 执行。这样就避免了 Fork Subagent 需要加载 40+ 工具 Schema 的成本——因为它根本用不到。
五、这个设计背后的三条工程原则
原则 1:成本是架构约束,不是性能优化
大多数团队把成本优化放在"性能优化"阶段:功能做完了,看看能不能省点钱。
Anthropic 的做法是相反的:成本在设计阶段就是硬约束。 Fork Subagent 的轻量设计不是"后面考虑优化"的产物——它从一开始就是为了解决成本问题而设计的。
如果先设计功能再优化成本,最终的架构一定不如在约束条件下生长出来的架构优雅。
原则 2:单个决策点可以撬动百倍收益
getSystemPrompt() 返回空字符串,这个改动看起来只有一行代码。
但这一行代码撬动了:
- Prompt Cache 缓存命中(-90% 成本)
- 工具列表无需加载(-30% token)
- Fork 子 Agent 轻量启动(-50% 延迟)
原则 3:系统的成本模型决定了系统的架构形态
Fork Subagent 不是"标准子 Agent 的简化版"。它们是两种完全不同的架构模式:
- 标准子 Agent:独立的能力单元,成本 = N × 标准成本
- Fork Subagent:共享缓存的轻量分析器,成本 = 固定成本 + 可忽略的增量成本
当你的成本模型不同,你的架构决策也会不同。Fork Subagent 的存在,让 “Multi-Agent = 成本翻倍” 变成了 “Multi-Agent ≈ 几乎不增加成本”。
这就是为什么 Claude Code 可以在一个普通 4 核服务器上运行几十个并行子 Agent——不是因为计算能力强,而是因为计算成本被设计压到了最低。
当其他团队在思考"如何降低 API 调用次数"时,Anthropic 在想"如何让每次调用几乎零成本"。当其他团队在"优化系统提示词长度"时,Anthropic 在想"如何让系统提示词不成为缓存障碍"。
返回空字符串,不是省略——是精确的省略。
在系列的 Multi-Agent 篇中,我们看到的是功能层面对"多 Agent 协作"的回答。今天这篇揭示了这些功能背后的成本引擎——没有这个引擎,所有功能都是空中楼阁。
而 Fork Subagent + Prompt Cache 的字节级对齐策略,就是那个让 Multi-Agent 从"极客玩具"变成"可用产品"的工程奇迹。
下一篇预告: Claude Code 源码深度拆解:ULTRAPLAN & Agent Swarm 分布式 AI 编排。远程 CCR 会话 + Opus 4.6 做 30 分钟深度规划 + 浏览器审批流。Agent Teams 支持 tmux/iTerm2 多进程、团队记忆同步、颜色编码。当单 Agent 不够用时——这套方案回答了"下一级复杂度怎么走"